The Brown PLT Blog

Articles by tag: Crowdsourcing
A Grounded Conceptual Model for Ownership Types in Rust
Little Tricky Logics
Can We Crowdsource Language Design?
Crowdsourcing User Studies for Formal Methods
User Studies of Principled Model Finder Output
Misconceptions In Finite-Trace and Infinite-Trace Linear Temporal Logic
Tags: Linear Temporal Logic, Crowdsourcing, Misconceptions, User Studies, Verification
Posted on 07 July 2024.We now also have an automated tutor that puts this material to work to help students directly.
Over the past three years and with a multi-national group of collaborators, we have been digging deeper into misconceptions in LTL (Linear Temporal Logic) and studying misconceptions in LTLf, a promising variant of LTL restricted to finite traces. Why LTL and LTLf? Because beyond their traditional uses in verification and now robot synthesis, they support even more applications, from image processing to web-page testing to process-rule mining. Why study misconceptions? Because ultimately, human users need to fully understand what a formula says before they can safely apply synthesis tools and the like.
Our original post on LTL misconceptions gives more background and motivation. It also explains the main types of questions we use: translations between English specifications and formal specifications.
So what’s new this time around?
First, we provide two test instruments that have been field tested with several audiences:
-
One instrument [PDF] focuses on the delta between LTL and LTLf. If you know LTL but not LTLf, give it a try! You’ll come away with hands-on experience of the special constraints that finite traces bring.
-
The other instrument [PDF] is for LTL beginners — to see what preconceptions they bring to the table. It assumes basic awareness of G (“always”), F (“eventually”), and X (“next state”). It does not test the U (“until”) operator. Live survey here.
Second, we find evidence for several concrete misconceptions in the data. Some misconceptions were identified in prior work and are confirmed here. Others are new to this work.
For example, consider the LTLf formula:
G(red => X(X(red))). What finite traces satisfy it?In particular, can any finite traces that have
redtrue at some point satisfy the formula?Click to show answer:
No, because wheneverredis true it must be true again two states later, but every finite trace will eventually run out of states.
Now consider the LTL formula
F(X(X(red))). Is it true for an infinite trace whereredis true exactly once?Click to show answer:
Yes. But interestingly, some of our LTL beginners said no on the grounds thatX(X(red))ought to "spread out" and constrain three states in a row.
Third, we provide a code book of misconceptions and how to identify them in new data [PDF].
For more details, see the paper.
See also our LTL Tutor (traditional LTL only, not finite-trace).
A Grounded Conceptual Model for Ownership Types in Rust
Tags: Crowdsourcing, Education, Rust, Types, User Studies, Visualization
Posted on 17 September 2023.Rust is establishing itself as the safe alternative to C and C++, making it an essential component for building a future software univers that is correct, reliable, and secure. Rust achieves this in part through the use of a sophisticated type system based on the concept of ownership. Unfortunately, ownership is unfamiliar to most conventionally-trained programmers. Surveys suggest that this central concept is also one of Rust’s most difficult, making it a chokepoint in software progress.
We have spent over a year understanding how ownership is currently taught, in what ways this proves insufficient for programmers, and looked for ways to improve their understanding. When confronted with a program containing an ownership violation, we found that Rust learners could generally predict the surface reason given by the compiler for rejecting the program. However, learners could often could not relate the surface reason to the underlying issues of memory safety and undefined behavior. This lack of understanding caused learners to struggle to idiomatically fix ownership errors.
To address this, we created a new conceptual model for Rust ownership, grounded in these studies. We then translated this model into two new visualizations: one to explain how the type-system works, the other to illustrate the impact on run-time behavior. Crucially, we configure the compiler to ignore borrow-checker errors. Through this, we are able to essentially run counterfactuals, and thereby illustrate the ensuing undefined behavior.
Here is an example of the type-system visualization:

And here is an example of the run-time visualization:
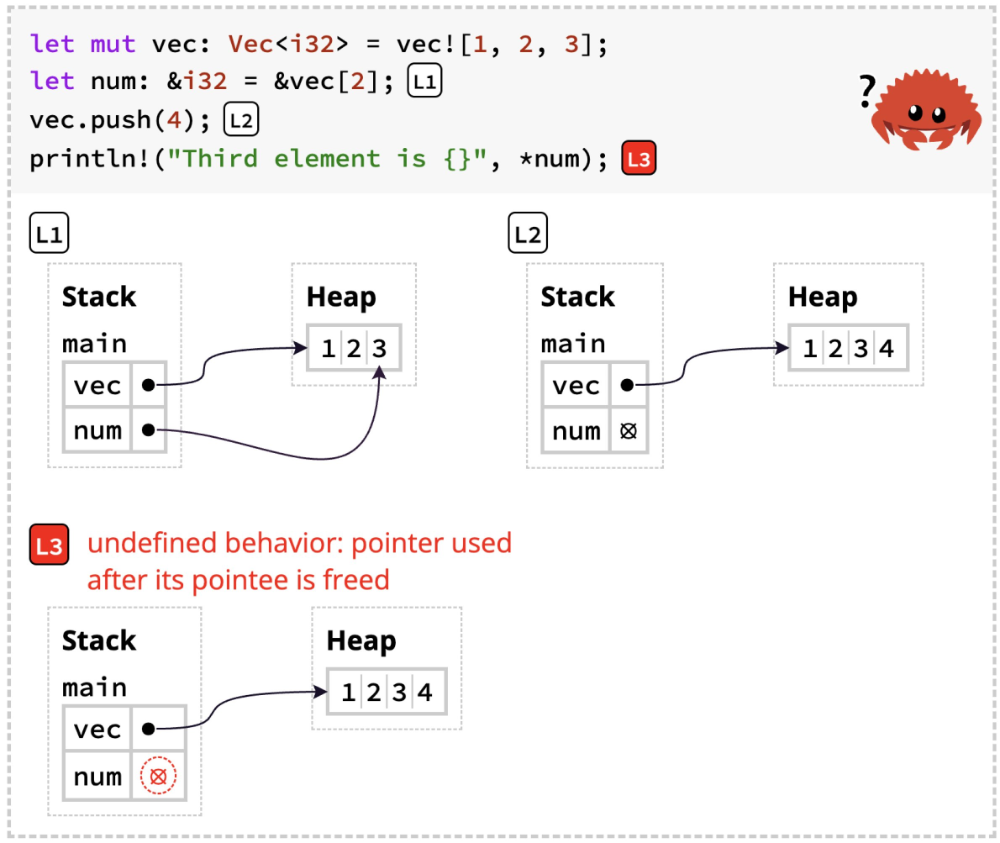
We incorporated these diagrams into an experimental version of The Rust Programming Language by Klabnik and Nichols. The authors graciously permitted us to create this fork and publicize it, and also provided a link to it from the official edition. As a result, we were able to test our tools on readers, and demonstrate that they do actually improve Rust learning.
The full details are in the paper. Our view is that the new tools are preliminary, and other researchers may come up with much better, more creative, and more effective versions of them. Rather, the main contribution is an understanding of how programmers do and don’t understand ownership, and in particular its relationship to undefined behavior. It is therefore possible that new pedagogies that make that connection clear may obviate the need for some of these tools entirely.
Little Tricky Logics
Tags: Linear Temporal Logic, Crowdsourcing, Misconceptions, User Studies, Verification
Posted on 05 November 2022.We also have followup work that continues to explore LTL and now also studies finite-trace LTL. In addition, we also have an automated tutor that puts this material to work to help students directly.
LTL (Linear Temporal Logic) has long been central in computer-aided verification and synthesis. Lately, it’s also been making significant inroads into areas like planning for robots. LTL is powerful, beautiful, and concise. What’s not to love?
However, any logic used in these settings must also satisfy the central goal of being understandable by its users. Especially in a field like synthesis, there is no second line of defense: a synthesizer does exactly what the specification says. If the specification is wrong, the output will be wrong in the same way.
Therefore, we need to understand how people comprehend these logics. Unfortunately, the human factors of logics has seen almost no attention in the research community. Indeed, if anything, the literature is rife with claims about what is “easy” or “intuitive” without any rigorous justification for such claims.
With this paper, we hope to change that conversation. We bring to bear on this problem several techniques from diverse areas—but primarily from education and other social sciences (with tooling provided by computer science)—to understand the misconceptions people have with logics. Misconceptions are not merely mistakes; they are validated understanding difficulties (i.e., having the wrong concept), and hence demand much greater attention. We are especially inspired by work in physics education on the creation of concept inventories, which are validated instruments for rapidly identifying misconceptions in a population, and take steps towards the creation of one.
Concretely, we focus on LTL (given its widespread use) and study the problem of LTL understanding from three different perspectives:
-
LTL to English: Given an LTL formula, can a reader accurately translate it into English? This is similar to what a person does when reading a specification, e.g., when code-reviewing work or studying a paper.
-
English to LTL: Given an English statement, can a reader accurately express it in LTL? This skill is essential for specification and verification.
Furthermore, “understanding LTL” needs to be divided into two parts: syntax and semantics. Therefore, we study a third issue:
- Trace satisfaction: Given an LTL formula and a trace (sequence of states), can a reader accurately label the trace as satisfying or violating? Such questions directly test knowledge of LTL semantics.
Our studies were conducted over multiple years, with multiple audiences, and using multiple methods, with both formative and confirmatory phases. The net result is that we find numerous misconceptions in the understanding of LTL in all three categories. Notably, our studies are based on small formulas and traces, so we expect the set of issues will only grow as the instruments contain larger artifacts.
Ultimately, in addition to
- finding concrete misconceptions,
we also:
-
create a codebook of misconceptions that LTL users have, and
-
provide instruments for finding these misconceptions.
We believe all three will be of immediate use to different communities, such as students, educators, tool-builders, and designers of new logic-based languages.
For more details, see the paper.
See also our LTL Tutor.
Can We Crowdsource Language Design?
Tags: Crowdsourcing, Programming Languages, Semantics, User Studies
Posted on 06 July 2017.Programming languages are user interfaces. There are several ways of making decisions when designing user interfaces, including:
- a small number of designers make all the decisions, or
- user studies and feedback are used to make decisions.
Most programming languages have been designed by a Benevolent Dictator for Life or a committee, which corresponds to the first model. What happens if we try out the second?
We decided to explore this question. To get a large enough number of answers (and to engage in rapid experimentation), we decided to conduct surveys on Amazon Mechanical Turk, a forum known to have many technically literate people. We studied a wide range of common programming languages features, from numbers to scope to objects to overloading behavior.
We applied two concrete measures to the survey results:
- Consistency: whether individuals answer similar questions the same way, and
- Consensus: whether we find similar answers across individuals.
Observe that a high value of either one has clear implications for language design, and if both are high, that suggests we have zeroed in on a “most natural” language.
As Betteridge’s Law suggests, we found neither. Indeed,
-
A surprising percentage of workers expected some kind of dynamic scope (83.9%).
-
Some workers thought that record access would distribute over the field name expression.
-
Some workers ignored type annotations on functions.
-
Over the field and method questions we asked on objects, no worker expected Java’s semantics across all three.
These and other findings are explored in detail in our paper.
Crowdsourcing User Studies for Formal Methods
Tags: Crowdsourcing, User Studies, Verification
Posted on 03 July 2017.For decades, we have neglected performing serious user studies of formal-methods tools. This is now starting to change. An earlier post introduces our new work in this area.
That study works with students in an upper-level class, who are a fairly good proxy for some developers (and are anyway an audience we have good access to). Unfortunately, student populations are problematic for several reasons:
-
There are only so many students in a class. There may not be enough to obtain statistical strength, especially on designs that require A/B testing and the like.
-
The class is offered only so often. It may take a whole year between studies. (This is a common problem in computing education research.)
-
As students progress through a class, it’s hard to “rewind” them and study their responses at an earlier stage in their learning.
And so on. It would be helpful if we could obtain large numbers of users quickly, relatively cheaply, and repeatedly.
This naturally suggests crowdsourcing. Unfortunately, the tasks we are examining involve using tools based on formal logic, not identifying birds or picking Web site colors (or solving CAPTCHAs…). That would seem to greatly limit the utility of crowd-workers on popular sites like Mechanical Turk.
In reality, this depends on how the problem is phrased. If we view it as “Can we find lots of Turkers with knowledge of Promela (or Alloy or …)?”, the answer is pretty negative. If, however, we can rework the problems somewhat so the question is “Can we get people to work on a puzzle?”, we can find many, many more workers. That is, sometimes the problem is one of vocabulary (and in particular, the use of specific formal methods languages) than of raw ability.
Concretely, we have taken the following steps:
-
Adapt problems from being questions about Alloy specifications to being phrased as logic “puzzles”.
-
Provide an initial training phase to make sure workers understand what we’re after.
-
Follow that with an evaluation phase to ensure that they “got the idea”. Only consider responses from those workers who score at a high enough threshold on evaluation.
-
Only then conduct the actual study.
Observe that even if we don’t want to trust the final results obtained from crowdsourcing, there are still uses for this process. Designing a good study requires several rounds of prototyping: even simple wording choices can have huge and unforeseen (negative) consequences. The more rounds we get to test a study, the better it will come out. Therefore, the crowd is useful at least to prototype and refine a study before unleashing it on a more qualified, harder-to-find audience — a group that, almost by definition, you do not want to waste on a first-round study prototype.
For more information, see our paper. We find fairly useful results using workers on Mechanical Turk. In many cases the findings there correspond with those we found with class students.
User Studies of Principled Model Finder Output
Tags: Crowdsourcing, Formal Methods, User Studies, Verification, Visualization
Posted on 01 July 2017.For decades, formal-methods tools have largely been evaluated on their correctness, completeness, and mathematical foundations while side-stepping or hand-waving questions of usability. As a result, tools like model checkers, model finders, and proof assistants can require years of expertise to negotiate, leaving knowledgeable but uninitiated potential users at a loss. This state of affairs must change!
One class of formal tool, model finders, provides concrete instances of a specification, which can guide a user’s intuition or witness the failure of desired properties. But are the examples produced actually helpful? Which examples ought to be shown first? How should they be presented, and what supplementary information can aid comprehension? Indeed, could they even hinder understanding?
We’ve set out to answer these questions via disciplined user-studies. Where can we find participants for these studies? Ideally, we would survey experts. Unfortunately, it has been challenging to do so in the quantities needed for statistical power. As an alternative, we have begun to use formal methods students in Brown’s upper-level Logic for Systems class. The course begins with Alloy, a popular model-finding tool, so students are well suited to participate in basic studies. With this population, we have found some surprising results that call into question some intuitively appealing answers to (e.g.) the example-selection question.
For more information, see our paper.
Okay, that’s student populations. But there are only so many students in a class, and they take the class only so often, and it’s hard to “rewind” them to an earlier point in a course. Are there audiences we can use that don’t have these problems? Stay tuned for our next post.