The Brown PLT Blog

Articles by tag: JavaScript
Typechecking Uses of the jQuery Language
Verifying Extensions' Compliance with Firefox's Private Browsing Mode
S5: Engineering Eval
Modeling DOM Events
Mechanized LambdaJS
ECMA Announces Official λJS Adoption
Objects in Scripting Languages
S5: Wat?
S5: Semantics for Accessors
S5: A Semantics for Today's JavaScript
The Essence of JavaScript
ADsafety
Slimming Languages by Reducing Sugar
Tags: JavaScript, Programming Languages, Resugaring, Semantics
Posted on 08 January 2016.JavaScript is a crazy language. It’s defined by 250 pages of English prose, and even the parts of the language that ought to be simple, like addition and variable scope, are very complicated. We showed before how to tackle this problem using λs5, which is an example of what’s called a tested semantics.
You can read about λs5 at the above link. But the basic idea is that λs5 has two parts:
- A small core language that captures the essential parts of JavaScript, without all of its foibles, and
- A desugaring function that translates the full language down to this small core.
(We typically call this core language λs5, even though technically speaking it’s only part of what makes up λs5.)
These two components together give us an implementation of JavaScript:
to run a program, you desugar it to λs5, and then
run that program. And with this implementation, we can run
JavaScript’s conformance test suite to check that
λs5 is accurate: this is why it’s called a tested
semantics. And lo, λs5 passes the relevant portion
of the test262 conformance suite.
The Problem
Every blog post needs a problem, though. The problem with λs5 lies in desugaring. We just stated that JavaScript is complicated, while the core language for λs5 is simple. This means that the complications of JavaScript must be dealt with not in the core language, but instead in desugaring. Take an illustrative example. Here’s a couple of innocent lines of JavaScript:
function id(x) {
return x;
}
These couple lines desugar into the following λs5 code:
{let
(%context = %strictContext)
{ %defineGlobalVar(%context, "id");
{let
(#strict = true)
{"use strict";
{let
(%fobj4 =
{let
(%prototype2 = {[#proto: %ObjectProto,
#class: "Object",
#extensible: true,]
'constructor' : {#value (undefined) ,
#writable true ,
#configurable false}})
{let
(%parent = %context)
{let
(%thisfunc3 =
{[#proto: %FunctionProto,
#code: func(%this , %args)
{ %args[delete "%new"];
label %ret :
{ {let
(%this = %resolveThis(#strict,
%this))
{let
(%context =
{let
(%x1 = %args
["0" , null])
{[#proto: %parent,
#class: "Object",
#extensible: true,]
'arguments' : {#value (%args) ,
#writable true ,
#configurable false},
'x' : {#getter func
(this , args)
{label %ret :
{break %ret %x1}} ,
#setter func
(this , args)
{label %ret :
{break %ret %x1 := args
["0" , {[#proto: %ArrayProto,
#class: "Array",
#extensible: true,]}]}}}}})
{break %ret %context["x" , {[#proto: null,
#class: "Object",
#extensible: true,]}];
undefined}}}}},
#class: "Function",
#extensible: true,]
'prototype' : {#value (%prototype2) ,
#writable true ,
#configurable true},
'length' : {#value (1.) ,
#writable true ,
#configurable true},
'caller' : {#getter %ThrowTypeError ,
#setter %ThrowTypeError},
'arguments' : {#getter %ThrowTypeError ,
#setter %ThrowTypeError}})
{ %prototype2["constructor" = %thisfunc3 , null];
%thisfunc3}}}})
%context["id" = %fobj4 ,
{[#proto: null, #class: "Object", #extensible: true,]
'0' : {#value (%fobj4) ,
#writable true ,
#configurable true}}]}}}}}
This is a bit much. It’s hard to read, and it’s hard for tools to process. But more to the point, λs5 is meant to be used by researchers, and this code bloat has stood in the way of researchers trying to adopt it. You can imagine that if you’re trying to write a tool that works over λs5 code, and there’s a bug in your tool and you need to debug it, and you have to wade through that much code just for the simplest of examples, it’s a bit of a nightmare.
The Ordinary Solution
So, there’s too much code. Fortunately there are well-known solutions to this problem. We implemented a number of standard compiler optimization techniques to shrink the generated λs5 code, while preserving its semantics. Here’s a boring list of the Semantics-Preserving optimizations we used:
- Dead-code elimination
- Constant folding
- Constant propogation
- Alias propogation
- Assignment conversion
- Function inlining
- Infer type & eliminate static checks
- Clean up unused environment bindings
Most of these are standard textbook optimizations; though the last two are specific to λs5. Anyhow, we did all this and got… 5-10% code shrinkage.
The Extraordinary Solution
That’s it: 5-10%.
Given the magnitude of the code bloat problem, that isn’t nearly enough shrinkage to be helpful. So let’s take a step back and ask where all this bloat came from. We would argue that code bloat can be partitioned into three categories:
- Intended code bloat. Some of it is intentional. λs5 is a small core language, and there should be some expansion as you translate to it.
- Incidental code bloat. The desugaring function from JS to λs5 is a simple recursive-descent function. It’s purposefully not clever, and as a result it sometimes generates redundant code. And this is exactly what the semantics-preserving rewrites we just mentioned get rid of.
- Essential code bloat. Finally, some code bloat is due to the semantics of JS. JS is a complicated langauge with complicated features, and they turn into complicated λs5 code.
There wasn’t much to gain by way of reducing Intended or Incidental code bloat. But how do you go about reducing Essential code bloat? Well, Essential bloat is the code bloat that comes from the complications of JS. To remove it, you would simplify the language. And we did exactly that! We defined five Semantics-Altering transformations:
- (IR) Identifier restoration: pretend that JS is lexically scoped
- (FR) Function restoration: pretend that JS functions are just functions and not function-object-things.
- (FA) Fixed arity: pretend that JS functions always take as many arguments as they’re declared with.
- (UAE) Assertion elimination: unsafely remove some runtime checks (your code is correct anyways, right?)
- (SAO) Simplifying arithmetic operators: eliminate strange behavior for basic operators like “+”.
These semantics-altering transformations blasphemously break the language. This is actually OK, though! The thing is, if you’re studying JS or doing static analysis, you probably already aren’t handling the whole language. It’s too complicated, so instead you handle a sub-language. And this is exactly what these semantics-altering transformations capture: they are simplifying assumptions about the JS language.
Lessons about JavaScript
And we can learn about JavaScript from them. We implemented these transformations for λs5, and so we could run the test suite with the transformations turned on and see how many tests broke. This gives a crude measure of “correctness”: a transformation is 50% correct if it breaks half the tests. Here’s the graph:
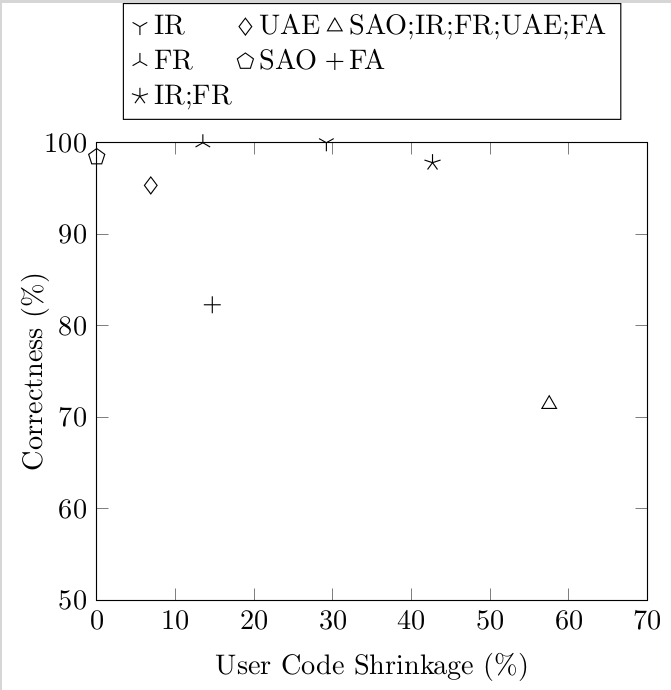
Notice that the semantics-altering transformations shrink code by more than 50%: this is way better than the 5-10% that the semantics-preserving ones gave. Going back to the three kinds of code bloat, this shows that most code bloat in λs5 is Essential: it comes from the complicated semantics of JS, and if you simplify the semantics you can make it go away.
Next, here’s the shrinkages of each of the semantics-altering transformations:
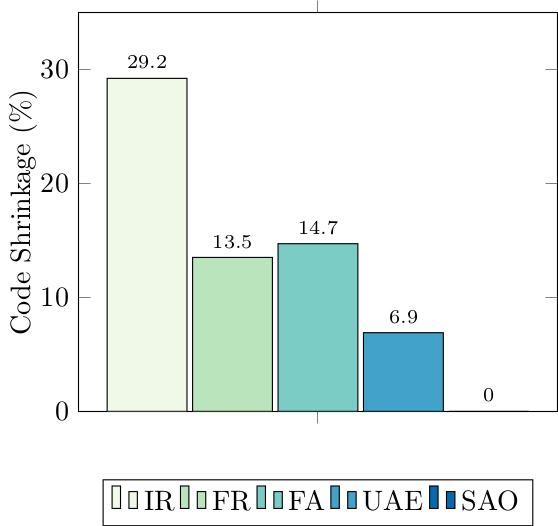
Since these semantics-altering transformations are simplifications of JS semantics, and desugared code size is a measure of complexity, you can view this graph as a (crude!) measure of complexity of language features. In this light, notice IR (Identifier Restoration): it crushes the other transformations by giving 30% code reduction. This shows that JavaScript’s scope is complex: by this metric 30% of JavaScript’s complexity is due to its scope.
Takeaway
These semantics-altering transformations give semantic restrictions on JS. Our paper makes these restrictions precise. And they’re exactly the sorts of simplifying assumptions that papers need to make to reason about JS. You can even download λs5 from git and implement your analysis over λs5 with a subset of these restrictions turned on, and test it. So let’s work toward a future where papers that talk about JS say exactly what sub-language of JS they mean.
The Paper
This is just a teaser: to read more, see the paper.
Typechecking Uses of the jQuery Language
Tags: Browsers, JavaScript, Types
Posted on 17 January 2014.Manipulating HTML via JavaScript is often a frustrating task: the APIs for doing so, known as the Document Object Model (or DOM), are implemented to varying degrees of fidelity across different browsers, leading to browser-specific workarounds that contort the code. Worse, the APIs are too low-level: they amount to an “assembly language for trees”, allowing programmers to navigate from a node to its parent, children or adjacent siblings; add, remove, or modify a node at a time; etc. And like assembly programming, these low-level operations are imperative and often error-prone.
Fortunately, developers have created libraries that abstract away from this low-level tedium to provide a powerful, higher-level API. The best-known example of these is jQuery, and its API is so markedly different from the DOM API that it might as well be its own language — a domain-specific language for HTML manipulation.
With great powerlanguage comes great responsibility
Every language has its own idiomatic forms, and therefore has its own characteristic failure modes and error cases. Our group has been studying various (sub-)languages of JavaScript— JS itself, ADsafety, private browsing violations— so the natural question to ask is, what can we do to analyze jQuery as a language?
This post takes a tour of the solution we have constructed to this problem. In it, we will see how a sophisticated technique, a dependent type system, can be specialized for the jQuery language in a way that:
- Retains decidable type-inference,
- Requires little programmer annotation overhead,
- Hides most of the complexity from the programmer, and yet
- Yields non-trivial results.
Engineering such a system is challenging, and is aided by the fact that jQuery’s APIs are well-structured enough that we can extract a workable typed description of them.
What does a jQuery program look like?
Let’s get a feel for those idiomatic pitfalls of jQuery by looking at a few tiny examples. We’ll start with a (seemingly) simple question: what does this one line of code do?
$(".tweet span").next().html()With a little knowledge of the API, jQuery’s code is quite
readable: get all the ".tweet span" nodes, get
their next() siblings, and…get the HTML code of
the first one of them. In general, a jQuery expression consists of
three parts: a initial query to select some nodes, a
sequence of navigational steps that select nearby nodes
related to the currently selected set, and finally
some manipulation to retrieve or set data on those node(s).
This glib explanation hides a crucial assumption: that there exist nodes in the page that match the initial selector in the first place! So jQuery programs’ behavior depends crucially on the structure of the pages in which they run.
Given the example above, the following line of code should behave analogously:
$(".tweet span").next().text()But it doesn’t—it actually returns the concatenated text content of all the selected nodes, rather than just the first. So jQuery APIs have behavior that depends heavily on how many nodes are currently selected.
Finally, we might try to manipulate the nodes by mapping a function
across them via jQuery’s each() method, and here we
have a classic problem that appears in any language: we must ensure
that the mapped function is only applied to the correct sorts of
HTML nodes.
Our approach
The examples above give a quick flavor of what can go wrong:
- The final manipulation might not be appropriate for the type of nodes actually in the query-set.
- The navigational steps might “fall off the edge of the tree”, navigating by too many steps and resulting in a vacuous query-set.
- The initial query might not match any nodes in the document, or match too many nodes.
Our tool of choice for resolving all these issues is a type system for JavaScript. We’ve used such a system before to analyze the security of Firefox browser extensions. The type system is quite sophisticated to handle JavaScript idioms precisely, and while we take advantage of that sophistication, we also completely hide the bulk of it from the casual jQuery programmer.
To adapt our prior system for jQuery, we need two technical insights: we define multiplicities, a new kind that allows us to approximate the size of a query set in its type and ensure that APIs are only applied to correctly-sized sets, and we define local structure, which allows developers to inform the type system about the query-related parts of the page.
Technical details
Multiplicities
Typically, when type system designers are confronted with the need to keep track of the size of a collection, they turn to a dependently typed system, where the type of a collection can depend on, say, a numeric value. So “a list of five booleans” has a distinct type from “a list of six booleans”. This is very precise, allowing some APIs to be expressed with exactitude. It does come at a heavy cost: most dependent type systems lose the ability to infer types, requiring hefty programmer annotations. But is all this precision necessary for jQuery?
Examining jQuery’s APIs reveals that its behavior can be broken down into five cases: methods might require their invocant query-set contain
- Zero elements of any type
T, writen0<T> - One element of some type
T, written1<T> - Zero or one elements of some type
T, written01<T> - One or more elements of some type
T, written1+<T> - Any number (zero or more) elements of some type
T, written0+<T>
These cases effectively abstract the exact size of a collection into a simple, finite approximation. None of jQuery’s APIs actually care if a query set contains five or fifty elements; all the matters is that it contains one-or-more. And therefore our system can avoid the very heavyweight onus of a typical dependent type system, instead using this simpler abstraction without any loss of necessary precision.
Moreover, we can
manipulate these cases using interval arithmetic: for
example, combining one collection of zero-or-one elements with
another collection containing exactly one element yields a
collection of one-or-more elements: 01<T> + 1<T> =
1+<T>. This is just interval addition.
jQuery’s APIs all effectively map some behavior across a queryset.
Consider the next() method: given a collection of at
least one element, it transforms each element into at most one
element (because some element might not have any next sibling). The
result is a collection of zero-or-more elements (if every element
does not have a next sibling).
Symbolically: 1+<01<T>> = 0+<T>. This
is just interval multiplication.
We can use these two operations to describe the types of all of
jQuery’s APIs. For example, the next() method can be
given the type Forall T, 1+<T> ->
0+<@next<T>>.
Local structure
Wait — what’s @next? Recall that we need to
connect the type system to the content of the page. So we ask
programmers to define local structures that describe the
portions of their pages that they intend to query. Think of them as
“schemas for page fragments”: while it is not reasonable
to ask programmers to schematize parts of the page they neither control
nor need to manipulate (such as 3rd-party ads), they
certainly must know the structure of those parts of the page that they
query! A local structure for, say, a Twitter stream might say:
(Tweet : Div classes = {tweet} optional = {starred}
(Author : Span classes = {span})
(Time : Span classes = {time})
(Content : Span classes = {content})
Read this as “A Tweet is a Div
that definitely has class tweet and might have
class starred. It contains three children elements in order:
an Author, a Time, and
a Content. An Author is
a Span with class span…”
(If you are familiar with templating libraries like mustache.js, these local structures might look familiar: they are just the widgets you would define for template expansion.)
From these definitions, we can compute crucial relationships: for
instance, the @next sibling of an Author
is a Time. And that in turn completes our
understanding of the type for next() above: for
any local structure
type T, next() can be called on a
collection of at least one T and will
return collection of zero or more elements that are
the @next siblings of Ts.
Note crucially that while the uses of @next
are baked into our system, the function itself is not
defined once-and-for-all for all pages: it is computed from the
local structures that the programmer defined. In this way,
we’ve parameterized our type system. We imbue it with
knowledge of jQuery’s fixed API, but leave a hole for programmers to
provide their page-specific information, and
thereby specialize our system for their code.
Of course, @next is not the only function we compute
over the local structure. We can
compute @parents, @siblings, @ancestors,
and more. But all of these functions are readily deducible from the
local structure.
Ok, so what does this all do for me?
Continuing with our Tweet example above, our system provides the following output for these next queries:// Mistake made: one too many calls to .next(), so the query set is empty
$(".tweet").children().next().next().next().css("color", "red")
// ==> ERROR: 'css' expects 1+<Element>, got 0<Element>
// Mistake made: one too few calls to .next(), so the query set is too big
$(".tweet #myTweet").children().next().css("color")
// ==>; ERROR: 'css' expects 1<Element>, got 1+<Author+Time>
// Correct query
$(".tweet #myTweet").children().next().next().css("color")
// ==> Typechecks successfullyThe big picture
We have defined a set of types for the jQuery APIs that captures
their intended behavior. These types are expressed using helper
functions such as @next, whose behavior is specific to
each page. We ask programmers merely to define the local structures
of their page, and from that we compute the helper functions we
need. And finally, from that, our system can produce type errors
whenever it encounters the problematic situations we listed above.
No additional programmer effort is needed, and the type errors
produced are typically local and pertinent to fixing buggy code.
Further reading
Obviously we have elided many of the nitty-gritty details that make our system work. We’ve written up our full system, with more formal definitions of the types and worked examples of finding errors in buggy queries and successfully typechecking correct ones. The writeup also explains some surprising subtleties of the type environment, and proposes some API enhancements to jQuery that were suggested by difficulties in engineering and using the types we defined.
Verifying Extensions' Compliance with Firefox's Private Browsing Mode
Tags: Browsers, JavaScript, Programming Languages, Security, Types, Verification
Posted on 19 August 2013.All modern browsers now support a “private browsing mode”, in which the browser ostensibly leaves behind no traces on the user's file system of the user's browsing session. This is quite subtle: browsers have to handle caches, cookies, preferences, bookmarks, deliberately downloaded files, and more. So browser vendors have invested considerable engineering effort to ensure they have implemented it correctly.
Firefox, however, supports extensions, which allow third party code to run with all the privilege of the browser itself. What happens to the security guarantee of private browsing mode, then?
The current approach
Currently, Mozilla curates the collection of extensions, and any extension must pass through a manual code review to flag potentially privacy-violating behaviors. This is a daunting and tedious task. Firefox contains well over 1,400 APIs, of which about twenty are obviously relevant to private-browsing mode, and another forty or so are less obviously relevant. (It depends heavily on exactly what we mean by the privacy guarantee of “no traces left behind”: surely the browser should not leave files in its cache, but should it let users explicitly download and save a file? What about adding or deleting bookmarks?) And, if the APIs or definition of private-browsing policy ever change, this audit must be redone for each of the thousands of extensions.
The asymmetry in this situation should be obvious: Mozilla auditors should not have to reconstruct how each extension works; it should be the extension developers' responsibility to convince the auditor that their code complies with private-browsing guarantees. After all, they wrote the code! Moreover, since auditors are fallible people, too, we should look to (semi-)automated tools to lower their reviewing effort.
Our approach
So what property, ultimately, do we need to confirm about an extension's code to ensure its compliance? Consider the pseudo-code below, which saves the current preferences to disk every few minutes:
var prefsObj = ...
const thePrefsFile = "...";
function autoSavePreferences() {
if (inPivateBrowsingMode()) {
// ...must store data only in memory...
return;
} else {
// ...allowed to save data to disk...
var file = openFile(thePrefsFile);
file.write(prefsObj.tostring());
}
}
window.setTimeout(autoSafePreferences, 3000);The key observation is that this code really defines two programs that happen to share the same source code: one program runs when the browser is in private browsing mode, and the other runs when it isn't. And we simply do not care about one of those programs, because extensions can do whatever they'd like when not in private-browsing mode. So all we have to do is “disentangle” the two programs somehow, and confirm that the private-browsing version does not contain any file I/O.
Technical insight
Our tool of choice for this purpose is a type system for JavaScript. We've used such a system before to analyze the security of the ADsafe sandbox. The type system is quite sophisticated to handle JavaScript idioms precisely, but for our purposes here we need only part of its expressive power. We need three pieces: first, three new types; second, specialized typing rules; and third, an appropriate type environment.
- We define one new primitive type:
Unsafe. We will ascribe this type to all the privacy-relevant APIs. - We use union types to define
Ext, the type of “all private-browsing-safe extensions”, namely: numbers, strings, booleans, objects whose fields areExt, and functions whose argument and return types areExt. Notice thatUnsafe“doesn’t fit” intoExt, so attempting to use an unsafe function, or pass it around in extension code, will result in a type error. - Instead of defining
Boolas a primitive type, we will instead defineTrueandFalseas primitive types, and defineBoolas their union.
- If an expression has some union type, and only one component
of that union actually typechecks, then we optimistically say
that the expression typechecks even with the whole union type.
This might seem very strange at first glance: surely, the
expression
5("true")shouldn't typecheck? But remember, our goal is to prevent privacy violations, and the code above will simply crash---it will never write to disk. Accordingly, we permit this code in our type system. - We add special rules for typechecking if-expressions. When
the condition typechecks at type
True, we only check the then-branch; when the condition typechecks at typeFalse, we only check the else-branch. (Otherwise, we check both branches as normal.)
- We give all the privacy-relevant APIs the
type
Unsafe. - We give the API
inPrivateBrowsingMode()the typeTrue. Remember: we just don't care what happens when it's false!
Put together, what do all these pieces achieve?
Because Unsafe and Ext are disjoint from
each other, we can safely segregate any code into two pieces that
cannot communicate with each other. By carefully initializing the
type environment, we make Unsafe precisely delineate
the APIs that extensions should not use in private browsing mode.
The typing rules for if-expressions plus the type
for inPrivateBrowsingMode() amount to disentangling the
two programs from each other: essentially, it implements dead-code
elimination at type-checking time. Lastly, the rule about union
types makes the system much easier for programmers to use, since they
do not have to spend any effort satisfying the typechecker about
properties other than this privacy guarantee.
In short, if a program passes our typechecker, then it must not call any privacy-violating APIs while in private-browsing mode, and hence is safe. No audit needed!
Wait, what about exceptions to the policy?
Sometimes, extensions have good reasons for writing to disk even
while in private-browsing mode. Perhaps they're updating their
anti-phishing blacklists, or they implement a download-helper that
saves a file the user asked for, or they are a bookmark manager. In
such cases, there simply is no way for the code to typecheck. As in
any type system, we provide a mechanism to break out of the type
system: an unchecked typecast. We currently write such casts
as cheat(T). Such casts must be checked by a human
auditor: they are explicitly marking the places where the extension
is doing something unusual that must be confirmed.
(In our original version, we took our cue from Haskell and wrote
such casts as unsafePerformReview, but sadly that is
tediously long to write.)
But does it work?
Yes.
We manually analyzed a dozen Firefox extensions that had already
passed Mozilla's auditing process. We annotated the extensions with
as few type annotations as possible, with the goal of forcing the
code to pass the typechecker, cheating if necessary.
These annotations found five extensions that violated
the private-browsing policy: they could not be typechecked without
using cheat, and the unavoidable uses
of cheat pointed directly to where the extensions
violated the policy.
Further reading
We've written up our full system, with more formal definitions of the types and worked examples of the annotations needed. The writeup also explains how we create the type environment in more detail, and what work is necessary to adapt this system to changes in the APIs or private-browsing implementation.
S5: Engineering Eval
Tags: JavaScript, Programming Languages, Semantics
Posted on 21 October 2012.In an earlier post, we introduced S5, our semantics for ECMAScript 5.1 (ES5). S5 is no toy, but strives to correctly model JavaScript's messy details.
One such messy detail of JavaScript is eval. The
behavior of eval was updated in the ES5 specification to
make its behavior less surprising and give more control to programmers.
However, the old behavior was left intact for backwards compatibility.
This has led to a language construct with a number of subtle behaviors.
Today, we're going to explore JavaScript's eval, explain
its several modes, and describe our approach to engineering an
implementation of it.
Quiz Time!
We've put together a short quiz to give you a tour of the various
types of eval in JavaScript. How many can you get right on
the first try?
Question 1
function f(x) {
eval("var x = 2;");
return x;
}
f(1) === ?;
f(1) === 2
This example returns 2 because the var declaration in
the eval actually refers to the same variables as
the body of the function. So, the eval body overwrites the
x parameter and returns the new value.
Question 2
function f(x) {
eval("'use strict'; var x = 2;");
return x;
}
f(1) === ?;
f(1) === 1
The 'use strict'; directive creates a new scope for
variables defined inside the eval. So, the
var x = 2; still evaluates, but doesn't affect the
x that is the function's parameter. These first two
examples show that strict mode
changes the scope that eval affects. We might
ask, now that we've seen these, what scope does eval
see?
Question 3
function f(x) {
eval("var x = y;");
return x;
}
f(1) === ?;
f(1) === ReferenceError: y is not defined
OK, that was sort of a trick question. This program throws an
exception saying that y is unbound. But it serves to
remind us of an important JavaScript feature; if a variable isn't
defined in a scope, trying to access it is an exception. Now we can ask
the obvious question: can we see y if we define it outside
the eval?
Question 4
function f(x) {
var y = 2;
eval("var x = y;");
return x;
}
f(1) === ?;
f(1) === 2
OK, here's our real answer. The y is certainly visible
inside the eval, which can both see and affect the outer
scope. What if the eval is strict?
Question 5
function f(x) {
var y = 2;
eval("'use strict'; var x = y;");
return x;
}
f(1) === ?;
f(1) === 1
Interestingly, we don't get an error here, so
it seems like y was visible to the eval
even in strict mode. However, as before the assignment doesn't
escape. New topic next.
Question 6
function f(x) {
var avel = eval;
avel("var x = y;");
return x;
}
f(1) === ?;
f(1) === ReferenceError: y is not defined
OK, that was a gimme. Lets add the variable declaration we need.
Question 7
function f(x) {
var avel = eval;
var y = 2;
avel("var x = y;");
return x;
}
f(1) === ?;
f(1) --> ReferenceError: y is not defined
What's going on here? We defined a variable and it isn't visible
like it was before, and all we did was rename eval.
Let's try a simpler example.
Question 8
function f(x) {
var avel = eval;
avel("var x = 2;");
return x;
}
f(1) === ?;
f(1) === 1
OK, so somehow we aren't seeing the assignment to x
either... Let's try making one more observation:
Question 9
function f(x) {
var avel = eval;
avel("var x = 2;");
return x;
}
f(1);
x === ?;
x === 2
Whoa! So that eval changed the x in the global
scope. This is what the specification refers to as an
indirect eval; when the call to eval doesn't
use a direct reference to the variable eval.
Question 10 (On the home stretch!)
function f(x) {
"use strict";
eval("var x = 2;");
return x;
}
f(1) === ?;
x === ?;
f(1) === 1
Before, when we had "use strict"; inside the
eval, we saw that the variable declarations did not
escape. Here, the "use strict"; is outside, but we see
the same thing: the value of
1 simply flows through to the return statement
unaffected. Second, we know that we aren't doing the same thing as
the indirect eval from the previous question,
because we didn't affect the global scope.
Question 11 (last one!)
function f(x) {
"use strict";
var avel = eval;
avel("var x = 2;");
return x;
}
f(1) === ?;
x === ?;
f(1) === 1
x === 2
Unlike in the previous question, this indirect eval has
the same behavior as before: it affects the global scope. The
presence of a "use strict"; appears to mean something different to an
indirect versus a direct eval.
Capturing all the Evals
We saw three factors that could affect the behavior of eval
above:
-
Whether the code passed to
evalwas instrictmode; -
Whether the code surrounding the
evalwas instrictmode; and -
Whether the
evalwas direct or indirect.
Each of these is a binary choice, so there are eight potential
configurations for an eval. Each of the eight cases
specifies both:
-
Whether the
evalsees the current scope or the global one; -
Whether variables introduced in the
evalare seen outside of it.
We can crisply describe all of these choices in a table:
| Strict outside? | Strict inside? | Direct or Indirect? | Local or global scope? | Affects scope? |
|---|---|---|---|---|
| Yes | Yes | Indirect | Global | No |
| No | Yes | Indirect | Global | No |
| Yes | No | Indirect | Global | Yes |
| No | No | Indirect | Global | Yes |
| Yes | Yes | Direct | Local | No |
| No | Yes | Direct | Local | No |
| Yes | No | Direct | Local | No |
| No | No | Direct | Local | Yes |
Rows where eval can affect some scope are shown in red
(where it cannot is blue),
and rows where the string passed to eval is strict mode code are in
bold.
Some patterns emerge here that make some of the design decisions of
eval clear. For example:
- If the
evalis indirect it always uses global scope; if direct it always uses local scope. - If the string passed to
evalis strict mode code, then variable declarations will not be seen outside theeval. - An indirect
evalbehaves the same regardless of the strictness of its context, while directevalis sensitive to it.
Engineering eval
To specify eval, we need to somehow both detect these
different configurations, and evaluate code with the right combination
of visible environment and effects. To do so, we start with a flexible
primitive that lets us evaluate code in an environment expressed as an
object:
internal-eval(string, env-object)
This internal-eval expects env-object to be an
object whose fields represent the environment to evaluate in. No
identifiers other than those in the passed-in environment are bound.
For example, a call like:
internal-eval("x + y", { "x" : 2, "y" : 5 })
Would evaluate to 7, using the values of the
"x" and "y" fields from the environment object as the
bindings for the identifiers x and y. With
this core primitive, we have the control we need to implement all the
different versions of eval.
In previous
posts, we talked about the
overall strategy of our evaluator for JavaScript. The relevant
high-level point for this discussion is that we define a core language,
dubbed S5, that contains only the essential features of JavaScript.
Then, we define a source-to-source transformer, called desugar,
that converts JavaScript programs to S5 programs. Since our evaluator
is defined only over S5, we need to use desugar in our
interpreter to perform the evaluation step. Semantically, the
evaluation of internal-eval is then:
internal-eval(string, env-object) -> desugar(string)[x1 / v1, ...] for each x1 : v1 in env-object (where [x / v] indicates substitution)
It is the combination of desugar and the customizable
environment argument to internal-eval that let us implement
all of JavaScript's eval forms. We actually
desugar all calls to JavaScript's eval into a
function call defined in S5 called maybeDirectEval, which
performs all the necessary checks to construct the correct environment
for the eval.
Leveraging S5's Eval
With our implementation of eval, we have made progress on a
few fronts.
Analyzing more JavaScript: We can now tackle more programs
than any of our prior formal semantics for JavaScript. For example, we
can actually run all of the complicated evals in
Secure ECMAScript, and
print the
heap inside a use of a sandboxed eval. This enables
new kinds of analyses that we haven't been able to perform before.
Understanding scripting languages' eval: Other
scripting languages, like Ruby and Python, also have eval.
Their implementations are closer to our internal-eval, in
that they take dictionary arguments that specify the bindings that are
available inside the evaluation. Is something like
internal-eval, which was inspired by well-known semantic
considerations, a useful underlying mechanism to use to describe all of
these?
The implementation of S5 is open-source, and a detailed report of our strategy and test results is appearing at the Dynamic Languages Symposium. Check them out if you'd like to learn more!
Modeling DOM Events
Tags: Browsers, JavaScript, Semantics
Posted on 17 July 2012.In previous posts, we’ve talked about our group’s work on providing an operational semantics for JavaScript, including the newer features of the language. While that work is useful for understanding the language, most JavaScript programs don’t run in a vacuum: they run in a browser, with a rich API to access the contents of the page.
That API, known as the Document Object Model (or DOM), consists of several parts:
- A graph of objects encoding the structure of page (This graph is optimistically called a "tree" since the HTML markup is indeed tree-shaped, but this graph has extra pointers between objects.),
- Methods to manipulate the HTML tree structure,
- A sophisticated event model to allow scripts to react to user interactions.
What makes this event programming so special?
To a first approximation, the execution of every web page looks roughly like: load the markup of the page, load scripts, set up lots of event handlers … and wait. For events. To fire. Accordingly, to understand the control flow of a page, we have to understand what happens when events fire.
Let’s start with this:
<div id="d1">
In outer div
<p id="p1">
In paragraph in div.
<span id="s1" style="background:white;">
In span in paragraph in div.
</span>
</p>
</div>
<script>
document.getElementById("s1").addEventListener("click",
function() { this.style.color = "red"; });
</script>
If you click on the text "In span in paragraph in div"
the event listener that gets added to element span#s1 is
triggered by the click, and turns the text red. But consider the
slightly more complicated example:
<div id="d2">
In outer div
<p id="p2">
In paragraph in div.
<span id="s2" style="background:white;">
In span in paragraph in div.
</span>
</p>
</div>
<script>
document.getElementById("d2").addEventListener("click",
function() { this.style.color = "red"; });
document.getElementById("s2").addEventListener("click",
function() { this.style.color = "blue"; });
</script>
Now, clicking anywhere in the box will turn all the text red. That
makes sense: we just clicked on the <div>
element, so its listener fires. But clicking on the <span> will turn
it blue and still turn the rest red. Why? We didn’t click on
the <div>! Well, not directly…
The key feature of event dispatch, as implemented for the DOM, is that
it takes advantage of the page structure. Clicking on an element of
the page (or typing into a text box, moving the mouse over an
element, etc.) will cause an event to fire "at" that element: the
element is the target of the event, and any event listener
installed for that event on that target node will be called. But in
addition, the event will also trigger event listeners on
the ancestors of the target node: this is called
the dispatch path. So in the example above,
because div#d2 is an ancestor of span#s2,
its event listener is also invoked, turning the text red.
What Could Possibly Go Wrong?
In a word: mutation. The functions called as event listeners are arbitrary JavaScript code, which can do anything they want to the state of the page, including modifying the DOM. So what might happen?
- The event listener might move the current target in the page. What happens to the dispatch path?
- The event listener adds (or removes) other listeners for the event being dispatched. Should newly installed listeners be invoked before or after existing ones? Should those listeners even be called?
- The event listener tries to cancel event dispatch. Can it do so?
- The listener tries to (programmatically) fire another event while the current one is active. Is event dispatch reentrant?
- There are legacy mechanisms to add event "handlers" as well as listeners. How should they interact with listeners?
Modeling Event Dispatch
Continuing our group’s theme of reducing a complicated, real-world system to a simpler operational model, we developed an idealized version of event dispatch in PLT Redex, a domain-specific language embedded in Racket for specifying operational semantics. Because we are focusing on exactly how event dispatch works, our model does not include all of JavaScript, nor does it need to—instead, it includes a miniature statement language containing the handful of DOM APIs that manipulate events. Our model does not include all the thousands of DOM properties and methods, instead including just a simplified tree-structured heap of nodes: this is all the structure we need to faithfully model the dispatch path of an event.
Our model is based on
the DOM Level 3
Events specification. It expresses the key behaviors of event
dispatch, and does so far more compactly than the spec: roughly 1000
lines of commented Redex code replace several pages’ worth of
(at times self-contradictory!) requirements that are spread
throughout a spec over a hundred pages long. From this concise
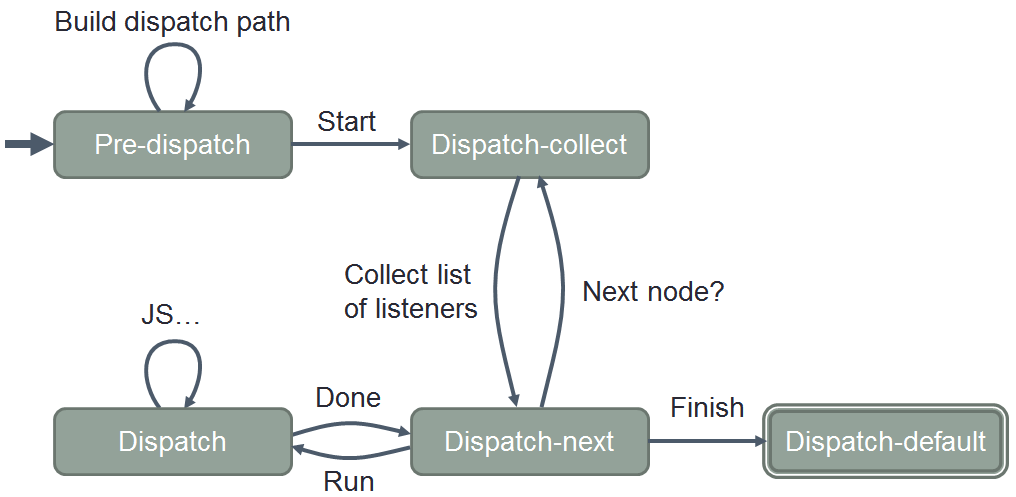
model, for example, we can easily extract a state machine describing
the key stages of dispatch:
Moreover, the model is executable: Redex allows us to
construct test cases—randomly, systematically, or ad-hoc, as
we choose—and then run them through our model and see what
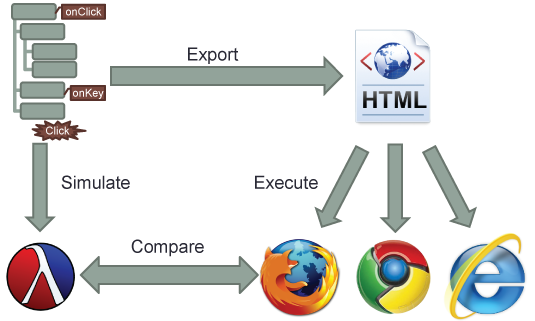
output it produces. Even better, we can export our tests to HTML
and JavaScript, and run them in real browsers and compare results:
What’s Done
Here’s what we’ve got so far:
- A PLT Redex model of event dispatch,
- An annotated copy of the DOM Level 3 Events spec, showing exactly which lines of our model correspond to which text in the spec, and
- A paper describing the model (and some applications of it) in greater detail.
What’s Next
Since our original JavaScript semantics was also written in Redex, we can combine our model of event dispatch with the JavaScript one, for a much higher-fidelity model of what event listeners can do in a browser setting. Then of course there are further applications, such as building a precise control-flow analysis of web pages and analyzing their code. And other uses? If you’re interested in using our model, let us know!
Mechanized LambdaJS
Tags: JavaScript, Programming Languages, Semantics
Posted on 04 June 2012.See the discussion on Lambda the Ultimate about this work.
In an earlier post, we introduced λJS, our operational semantics for JavaScript. Unlike many other operational semantics, λJS is no toy, but strives to correctly model JavaScript's messy details. To validate these claims, we test λJS with randomly generated tests and with portions of the Mozilla JavaScript test suite.
Testing is not enough. Despite our work, other researchers found a missing case in λJS. Today, we're introducing Mechanized λJS, which comes with a machine-checked proof of correctness, using the Coq proof assistant.
Recap: The Structure of λJS
λJS has two key parts: an operational semantics and a desugaring function. Our earlier post discusses how we tackle the minutiae of JavaScript with our desugaring function. This post focuses on the operational semantics, where others found a bug, which now has a machine-checked proof of correctness.
The operational semantics is typical of programming languages research. It specifies the sequence of steps required to evaluate the program. For example, the following sequence evaluates to a value:
{ x: 2 + 3, y : 9 }["x"] * (11 + 23)
→ { x: 5, y: 9 }["x"] * (11 + 23)
→ 5 * (11 + 23)
→ 5 * 34
→ 170
The sequence above evaluates expressions from left to right—a detail
spelled out in the operational semantics.
Not all expressions reduce to values. For example, the following reduces to an error:
null["x"] → err "Cannot read property 'x' of null"An operational semantics specifies exactly which errors may occur.
Finally, an operational semantics allows some programs to run forever. This is a basic infinite loop, and its non-terminating reduction sequence:
while (true) { 1; }
→ if true then 1; while (true) { 1; } else undefined
→ 1; while (true) { 1; }
→ while (true) { 1; }
→ if true then 1; while (true) { 1; } else undefined
→ 1; while (true) { 1; }
…
In general, these are the only three cases that the semantics should allow—an expression must either (1) evaluate to a value, (2) signal an error, or (3) not terminate. In fact, we can state that as a theorem.
Theorem 1 (Soundness). For all λJS programs, p, either:
- p →* v,
- p →* err, or
- p →* p2, and there exists a p3 such that p2 → p3.
This is a standard theorem worth proving for any language. Since languages and their correctness proofs involve detailed, delicate designs and decisions, the proofs are easy to do wrong, and tedious for humans to get right. If only computers could help.
PLT Redex: Lightweight Mechanization
We first developed λJS in PLT Redex, a domain-specific language embedded in Racket for specifying operational semantics.
Redex brings dull semantics to life. It doesn't just make a semantics executable, but also lets you visualize it. For example, here is our first example sequence in Redex (parentheses included):
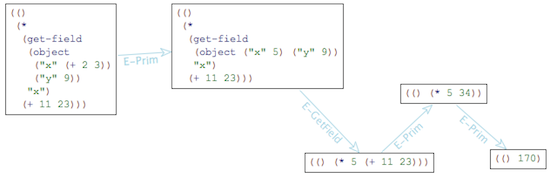
The visualizer is a lot of fun, and a very effective debugging tool. It helped us catch several bugs in the early design of λJS.
Redex can also generate random tests to exercise your semantics. Random testing caught several more bugs in λJS.
Coq: A Machine-Checked Proof
Testing is not enough. We shipped λJS with a bug that breaks the soundness theorem above. We didn't discover it for a year. David van Horn and Ian Zerny both reported it to us independently. We'd missed a case in the semantics, which caused certain terms to get "stuck". It turned out to be a simple fix, but we were left wondering if anything else was left lurking.
To gain further assurance, we mechanized λJS with the Coq proof assistant. The soundness theorem now has a machine-checked proof of correctness. You still need to read the Coq definition of λJS and ensure it matches your intuitions. But once that's done, you can be confident that the proofs are valid.
Doing this proof was surprisingly easy, once we'd read Software Foundations and Certified Programming with Dependent Types. We'd like to thank Benjamin Pierce and his co-authors, and Adam Chlipala, for putting their books online.
What's Done
Here's what we've got so far:
- A PLT Redex model,
- A Coq model, and
- A proof of soundness in Coq.
What's Next
We're not done. Here's what's coming up:
- There are a few easy bits missing from the Coq model (e.g., a parameterized delta-function).
- Once those easy bits are done, we'll wire it together with desugaring.
- Finally, we'll upgrade the model to support semantics for ECMAScript 5.
ECMA Announces Official λJS Adoption
Tags: April 1, JavaScript
Posted on 01 April 2012.GENEVA - ECMA's Technical Committee 39, which oversees the standardization of ECMAScript, has completed the adoption of Brown PLT's λJS as the new basis for the language. "We were being hampered by the endless debates about the semantics of ECMAScript 5", said J. Neumann, the Chairman of the Committee. "By adopting λJS, we can return to focusing on the important parts of the programming language instead, such as its interaction with parts of the W3C DOM Specification."
"The replacement of scope objects
with substitution is a clear design flaw."
-Arjun Guha
Improvements to λJS - Neumann added that the
standardization process uncovered a significant weakness in
λJS: the absence of the with construct. The
Technical Committee therefore mandated its introduction. Lead designer
Arjun Guha agreed, stating, "The replacement of scope objects with
substitution is a clear design flaw. It was pointed out to me by
numerous academic researchers who have obtained considerable mileage
from them, but it took me a while to appreciate their value." The
Committee also recommended a "strict mode", so Guha removed first-class
functions, which are widely believed to induce laxity by deferring
decision-making.
Opposition to the Change - The adoption of λJS has not, however, met with unanimous approval. When asked for comment, Douglas Crockford of Yahoo! complained that the small parts are not good while the good parts are not small. Another detractor, Northeastern University researcher Sam Tobin-Hochstadt, had pushed for the adoption of Racket as the core language instead of λJS, but he admitted that Racket was untenable as it suffered from having a working module system. The team from Apple declined response, but it is widely rumored that Jonathan Ive is at work on a new core calculus that will have only one operation, which will automatically take the step that the user did not know they should have performed.
"We see this as a fight for the future
of the Internet."
-David Herman
Influential Support - Nevertheless, the adoption has support from various influential circles. The Internet Explorer group at Microsoft has already agreed to implement λJS in the core engine of their upcoming release, IE12; lead designer Dean Hachamovitch said it is second in innovation only to the introduction of tabs. Strict mode will be supported in IE13. Google's Mark Miller pointed out, "With the aid of membranes, any primordial vat can be instantiated with desirable liveness properties." When asked to comment about λJS instead of the Miller-Urey experiment, Miller repeated the comment. Finally, noted Mozilla researcher Dave Herman commented, "For Mozilla, we see this as a fight for the future of the Internet." On questioning, he admitted that he diverts all interviews into conversations about Boot2Gecko.
Objects in Scripting Languages
Tags: JavaScript, Programming Languages, Semantics
Posted on 28 February 2012.We've been studying scripting languages in some detail, and have collected a number features of their object systems that we find unusually expressive. This expressiveness can be quite powerful, but also challenges attempts to reason about and understand programs that use these features. This post outlines some of these exceptionally expressive features for those who may not be intimately familiar with them.
Dictionaries with Inheritance
Untyped scripting languages implement objects as dictionaries mapping member names (strings) to values. Inheritance affects member lookup, but does not affect updates and deletion. This won't suprise any experienced JavaScript programmer:
var parent = {"z": 9};
// Using __proto__ sets up inheritance directly in most browsers
var obj = { "x": 1, "__proto__": parent};
obj.x // evaluates to 1
obj.z // evaluates to 9
obj.z = 50 // creates new field on obj
obj.z // evaluates to 50, z on parent is "overridden"
parent.z // evaluates to 9; parent.z was unaffected by obj.z = 50In other scripting languages, setting up this inheritance can't be done quite so directly. Still, its effect can be accomplished, and the similar object structure observed. For example, in Python:
class parent(object):
z = 9 # class member
def __init__(self):
self.x = 1 # instance member
obj = parent()
obj.x # evaluates to 1
obj.z # evaluates to 9
obj.z = 50 # creates new field on obj
obj.z # evaluates to 50, z on parent is "overridden"
parent.z # evaluates to 9, just like JavaScript We can delete the field in both languages, which returns
obj to its original state, before it was extended with a
z member. In JavaScript:
delete obj.z;
obj.z // evaluates to 9 againThis also works in Python:
delattr(obj, "z");
obj.z # evaluates to 9 againIn both languages, we could have performed the assignments and lookups with computed strings as well:
// JavaScript
obj["x " + "yz"] = 99 // creates a new field, "x yz"
obj["x y" + "z"] // evaluates to 99# Python
setattr(obj, "x " + "yz", 99) # creates a new field, "x yz"
getattr(obj, "x y" + "z") # evaluates to 99We can go through this entire progression in Ruby, as well:
class Parent; def z; return 9; end; end
obj = Parent.new
class << obj; def x; return 1; end; end
obj.x # returns 1
obj.z # returns 9
class << obj; def z; return 50; end; end
obj.z # return 50
# no simple way to invoke shadowed z method
class << obj; remove_method :z; end
obj.z # returns 9
class << obj
define_method("xyz".to_sym) do; return 99; end
end
print obj.xyz # returns 99Classes Do Not Shape Objects
The upshot is that a class definition in a scripting language says little about the structure of its instances. This is in contrast to a language like Java, in which objects' structure is completely determined by their class, to the point where memory layouts can be predetermined for runtime objects. In scripting languages, this isn't the case. An object is an instance of a 'class' in JavaScript, Python, or Ruby merely by virtue of several references to other runtime objects. Some of these be changed at runtime, others cannot, but in all cases, members can be added to and removed from the inheriting objects. This flexibility can lead to some unusual situations.
Brittle inheritance: Fluid classes make inheritance brittle. If we start with this Ruby class:
class A
def initialize; @privateFld = 90; end
def myMethod; return @privateFld * @privateFld; end
end Then we might assume that implementation of myMethod assumes
a numeric type for @privateFld. This assumption can be
broken by subclasses, however:
class B < A
def initialize; super(); @privateFld = "string (not num)"; end
end
Since both A and B use the same name, and it
is simply a dictionary key, B instances violate the
assumptions of A's methods:
obj = B.new
B.myMethod # error: cannot multiply stringsRuby's authors are well aware of this; the Ruby manual states "it is only safe to extend Ruby classes when you are familiar with (and in control of) the implementation of the superclass" (page 240).
Mutable Inheritance: JavaScript and Python expose the
inheritance chain through mutable object members. In JavaScript, we
already saw that the member "__proto__" could be used to
implement inheritance directly. The "__proto__" member is
mutable, so class hierarchies can be changed at runtime. We found it a
bit more surprising when we realized the same was possible in Python:
class A(object):
def method(self): return "from class A"
class B(object):
def method(self): return "from class B"
obj = A()
obj.method() # evaluates to "from class A"
isinstance(obj, A) # evaluates to True
obj.__class__ = B # the __class__ member determines inheritance
obj.method() # evaluates to "from class B"
isinstance(obj, B) # evaluates to True: obj's 'class' has changed!Methods?
These scripting languages also have flexible, and different, definitions of "methods".
JavaScript simply does not have methods. The syntax
obj.method(...)
Binds this to the value of obj in the body of
method. However, the method member is just a
function and can be easily extracted and applied:
var f = obj.method; f(...);
Since f() does not use the method call syntax above, it is
treated as a function call. In this case, it is a well known JavaScript
wart that this is bound to a default "global object" rather
than obj.
Python and Ruby make a greater effort to retain a binding for the
this parameter. Python doesn't care about the name of the
parameter (though self is canonically used), and simply has
special semantics for the first argument of a method. If a method is
extracted via member access, it returns a function that binds the object
from the member access to the first parameter:
class A(object):
def __init__(self_in_init): self_in_init.myField = 900
def method(self_in_method): return self_in_method.myField
obj = A()
f1 = obj.method # the access binds self_in_method to obj
f1() # evaluates to 900, using the above bindingIf the same method is accessed as a field multiple times, it isn't the same function both times―a new function is created for each access:
obj = A()
f1 = obj.method # first extraction
f2 = obj.method # second extraction
f1 is f2 # evaluates to False, no reference equality
Python lets programmers access the underlying function without the first
parameter bound through the member im_func. This is
actually the same reference across all extracted methods, regardless of
even the original object of extraction:
obj = A()
f1 = obj.method # first extraction
f2 = obj.method # second extraction
otherobj = A()
f3 = obj.method # extraction from another object
# evaluates to True, same function referenced from extractions on the
# same object
f1.im_func is f2.im_func
# evaluates to True, same function referenced from extractions on
# different objects
f2.im_func is f3.im_funcRuby has a similar treatment of methods, their extraction, and their reapplication to new arguments.
But Why?
These features aren't just curiosities―we've found examples where they are used in practice. For example, Django's ORM builds classes dynamically, modifying them based on strings that come from modules describing database tables and relationships ( base.py):
attr_name = '%s_ptr' % base._meta.module_name
field = OneToOneField(base, name=attr_name,
auto_created=True, parent_link=True)
new_class.add_to_class(attr_name, field)Ruby on Rails' ActiveRecord uses dynamic field names as well, iterating over fields and invoking methods only when their names match certain patterns ( base.rb):
attributes.each do |k, v|
if k.include?("(")
multi_parameter_attributes << [ k, v]
elsif respond_to?("#{k}=")
if v.is_a?(Hash)
nested_parameter_attributes << [ k, v ]
else
send("#{k}=", v)
else
raise(UnkownAttributeError, "unknown attribute: #{k}")
end
endThese applications use objects as dictionaries (with inheritance) to build up APIs that they couldn't otherwise.
These expressive features aren't
without their perils. Django has
explicit warnings that things can go awry if relationships between
tables expressed in ORM classes overlap. And the fact that
__proto__ is in the same namespace as the other members bit
Google Docs, whose
editor would crash if the string "__proto__" was
entered. The implementation was using an object as a hashtable keyed by
strings from the document, which led to an assignment to
__proto__ that changed the behavior of the map.
So?
The languages presented here are widely adopted and used, and run critical systems. Yet, they contain features that defy conventional formal reasoning, at the very least in their object systems. Perhaps these features' expressiveness outweighs the cognitive load of using them. If it doesn't, and using these features is too difficult or error-prone, we should build tools to help us use them, or find better ways to implement the same functionality. And if not, we should take notice and recall that we have these powerful techniques at our disposal in the next object system we design.
S5: Wat?
Tags: JavaScript, Programming Languages, Semantics
Posted on 31 January 2012.Gary Bernhardt's Wat talk has been making a well-deserved round of the blogodome in the past few weeks. If you haven't seen it, go give it a watch (you can count it as work time, since you saw it on the Brown PLT Blog, and we're Serious Researchers). The upshot of the second half of the talk is that JavaScript has some less than expected behaviors. We happen to have a JavaScript implementation floating around in the form of S5, and like to claim that it handles the hairy corners of the language. We decided to throw Gary's examples at it.
The Innocuous +
Gary's first JavaScript example went like this:
failbowl:~(master!?) $ jsc
> [] + []
> [] + {}
[object Object]
> {} + []
0
> {} + {}
NaN S5 lacks a true REPL―it simply takes JavaScript strings and produces
output and answers―so we started by approximating a little bit. We
first tried a series of print statements to see if we got
the same effect:
$ cat unit-tests/wat-arrays.js
print([] + []);
print([] + {});
print({} + []);
print({} + {});
$ ./s5 < unit-tests/wat-arrays.js
[object Object]
[object Object]
[object Object][object Object]
undefinedWAT.
Well, that doesn't seem good at all. Only half of the answers are
right, and there's an undefined at the end. What went
wrong? It turns out the semantics of REPLs are to blame. If we take
the four programs and run them on their own, we get something that looks
quite a bit better:
$ ./s5 "[] + []"
""
$ ./s5 "[] + {}"
"[object Object]"
$ ./s5 "{} + []"
0.
$ ./s5 "{} + {}"
nanThere are two issues here:
- Why do
0.andnanprint like that? - Why did this work, when the previous attempt didn't?
The answer to the first question is pretty straightforward: under the covers, S5 is using Ocaml floats and printing Ocaml values at the end of its computation, and Ocaml makes slightly different decisions than JavaScript in printing numbers. We could change S5 to print answers in JavaScript-printing mode, but the values themselves are the right ones.
The second question is more interesting. Why do we get such different answers depending on whether we evaluate individual strings versus printing the expressions? The answer is in the semantics of JavaScript REPLs. When parsing a piece of JavaScript, the REPL needs to make a choice. Sensible decisions would be to treat each new JavaScript string as a Statement, or as an entire JavaScript Program. Most REPLs choose the Program production.
The upshot is that the parsing of {} + {} is quite
different from [] + []. With S5, it's trivial to print the
desugared representation and understand the difference. When we parse
and desugar, we get very different results for {} + {} and
[] + []:
$ ./s5-print "{} + {}"
{undefined;
%UnaryPlus({[#proto: %ObjectProto,
#class: "Object",
#extensible: true,]
})}
$ ./s5-print "[] + []"
%PrimAdd({
[#proto: %ArrayProto,
#class: "Array",
#extensible: true,]
'length' : {#value 0., #writable true, #configurable false}
},
{
[#proto: %ArrayProto,
#class: "Array",
#extensible: true,]
'length' : {#value 0., #writable true, #configurable false}
}
)
It is clear that {} + {} parses as two statements (an
undefined followed by a UnaryPlus), and
[] + [] as a single statement containing a binary addition
expression. What's happening is that in the Program production, for the
string {} + {}, the first {} is matched with
the Block
syntactic form, with no internal statements. The rest of the expression
is parsed as a UnaryExpression. This is in
contrast to [] + [], which only correctly parses as an
ExpressionStatement containing an AdditiveExpression.
In the example where we used successive print
statements, every expression in the argument position to print
was parsed in the second way, hence the different answers. The lesson?
When you're at a REPL, be it Firebug, Chrome, or the command line, make
sure the expression you're typing is what you think it is: not being
aware of this difference can make it even more difficult to know what to
expect!
If You Can't Beat 'Em...
Our first example led us on an interesting excursion into parsing,
from which S5 emerged triumphant, correctly modelling the richness
and/or weirdness of the addition examples. Next up, Gary showed some
straightforward uses of Array.join():
failbowl:~(master!?) $ jsc
> Array(16)
,,,,,,,,,,,,,,,,
> Array(16).join("wat")
watwatwatwatwatwatwatwatwatwatwatwatwatwatwatwat
> Array(16).join("wat" + 1)
wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1
> Array(16).join("wat" - 1) + " Batman"
NaNNaNNaNNaNNaNNaNNaNNaNNaNNaNNaNNaNNaNNaNNaNNaN Batman Our results look oh-so-promising, right up until the last line
(note: we call String on the first case, because S5 doesn't
automatically toString answers, which the REPL does).
$ ./s5 "String(Array(16))"
",,,,,,,,,,,,,,,,"
$ ./s5 "Array(16).join('wat')"
"watwatwatwatwatwatwatwatwatwatwatwatwatwatwatwat"
$ ./s5 "Array(16).join('wat' + 1)"
"wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1wat1"
$ ./s5 "Array(16).join('wat' - 1) + ' Batman'"
"nullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnull Batman"WAT.
Are we really that awful that we somehow yield null rather
than NaN? A quick glance at the desugared code shows us
that we actually have the constant value null as
the argument to join(). How did that happen?
Interestingly, the following version of the program works:
$ ./s5 "var wat = 'wat'; Array(16).join(wat - 1) + ' Batman';"
"NaNNaNNaNNaNNaNNaNNaNNaNNaNNaNNaNNaNNaNNaNNaN Batman" This leads us to our answer. We use SpiderMonkey's very handy Parser
API as part of our toolchain. Reflect.parse() takes
strings and converts them to JSON structures with rich AST information,
which we stringify and pass off to the innards of S5 to do desugaring
and evaluation. Reflect.parse() is part of a JavaScript
implementation that strives for performance, and to that end it performs
constant folding. That is, as an optimization, when it sees the
expression "wat" - 1, it automatically converts it to
NaN. All good so far.
The issue is that the NaN yielded by constant folding
is not quite the same NaN we might expect in JavaScript
programs. In JavaScript, the identifier NaN is a
property of the global object with the value
NaN. The Parser API can't safely fold to the
identifier NaN (as was pointed
out to us when we reported this bug), because it might be shadowed
in a different context. Presumably to avoid this pitfall, the folding
yields a JSON structure that looks like:
expression:{type:"Literal", value:NaN} But we can't sensibly use JSON.stringify() on this
structure, because NaN isn't valid JSON! Any guesses on
what SpiderMonkey's JSON implementation turns NaN into? If
you guessed null, we owe you a cookie.
We have designed a
hack based on suggestions from the bug report to get around this
(passing a function to stringify to look for
NaNs and return a stylized object literal instead).
There's a bug open to make constant folding optional in
Reflect.parse(), so this will be fixed in Mozilla's
parser. (Update) The bug
is fixed, and we've updated our version of Spidermonkey. This example
now works happily, thanks to Dave Herman.
Producing a working JavaScript implementation leads to a whole host of exciting moments and surprising discoveries. Building this semantics and its desugaring gives us much more confidence that our tools say something meaningful about real JavaScript programs. These examples show that getting perfect correspondence is difficult, but we strive to be as close as possible.
S5: Semantics for Accessors
Tags: JavaScript, Programming Languages, Semantics
Posted on 11 December 2011.Getters and setters (known as accessors) are a new feature in ECMAScript 5 that extend the behavior of assignment and lookup expressions on JavaScript objects. If a field has a getter defined on it, rather than simply returning the value in field lookup, a getter function is invoked, and its return value is the result of the lookup:
var timesGotten = 0;
var o = {get x() { timesGotten++; return 22; }};
o.x; // calls the function above, evaluates to 22
timesGotten; // is now 1, due to the increment in the getter
o.x; // calls the function above, still evaluates to 22
timesGotten; // is now 2, due to another increment in the getterSimilarly, if a field has a setter defined on it, the setter function is called on field update. The setter function gets the assigned value as its only argument, and its return value is ignored:
var foo = 0;
var o = {set x(v) { foo = v; }};
o.x = 37; // calls the function above (with v=37)
foo; // evaluates to 37
o.x; // evaluates to undefined Getters and setters have a number of proposed uses―they can be used to wrap
DOM objects that have interesting effects on assignment, like
onmessage and onbeforeunload, for example. We leave
discovering good uses to more creative JavaScript programmers, and focus on
their semantic properties here.
The examples above are straightforward, and it seems like a simple model might work out quite easily. First, we need some definitions, so we'll start with what's in λJS. Here's a fragment of the values that λJS works with, and the most basic of the operations on objects:
v := str | { str1:v1, ⋯, strn:vn } | func(x ⋯) . e | ⋯
e := e[e] | e[e=e] | e(e, ⋯) | ⋯
(E-Lookup)
{ ⋯, str:v, ⋯ }[strx] → v
when strx = str
(E-Update)
{ ⋯, str:v, ⋯}[strx=v'] → { ⋯, str:v', ⋯}
when strx = str
(E-UpdateAdd)
{ str1:v1, ⋯}[str=v] → { str:v, str1:v1, ⋯}
when str ≠ str1, ⋯
We update and set fields when they are found, and add fields if there is an update on a not-found field. Clearly, this isn't enough to model the semantics of getters and setters. On lookup, if the value of a field is a getter, we need to have our semantics step to an invocation of the function. We need to make the notion of a field richer, so the semantics can have behavior that depends on the kind of field. We distinguish two kinds of fields p, one for simple values and one for accessors:
p := [get: vg, set: vs] | [value: v]
v := str | { str1:p1, ⋯, strn:pn } | func(x ⋯) . e | ⋯
e := e[e] | e[e=e] | e(e, ⋯) | ⋯
The updated rules for simple values are trivial to write down (differences in bold):
(E-Lookup)
{ ⋯, str:[value:v], ⋯ }[strx] → v
when strx = str
(E-Update)
{ ⋯, str:[value:v], ⋯}[strx=v'] → { ⋯, str:[value:v'], ⋯}
when strx = str
(E-UpdateAdd)
{ str1:v1, ⋯}[str=v] → { str:[value:v], str1:v1, ⋯}
when str ≠ str1, ⋯
But now we can also handle the cases where we have a getter or setter. If a lookup expression e[e] finds a getter, it applies the function, and the same goes for setters, which get the value as an argument:
(E-LookupGetter)
{ ⋯, str:[get:vg, set:vs], ⋯ }[strx] → vg()
when strx = str
(E-UpdateSetter)
{ ⋯, str:[get:vg, set:vs], ⋯}[strx=v'] → vs(v')
when strx = str
Great! This can handle the two examples from the beginning of the post. But those two examples weren't the whole story for getters and setters, and our first fragment wasn't the whole story for λJS objects.
Consider this program:
var o = {
get x() { return this._x + 1; },
set x(v) { this._x = v * 2; }
};
o.x = 5; // calls the set function above (with v=5)
o._x; // evaluates to 10, because of assignment in the setter
o.x; // evaluates to 11, because of addition in the getter
Here, we see that the functions also have access to the target object of the
assignment or lookup, via the this parameter. We could try to
encode this into our rules, but let's not get too far ahead of ourselves.
JavaScript objects have more subtleties up their sleeves. We can't forget
about prototype inheritance. Let's start with the same object o,
this time called parent, and use it as the prototype of another
object:
var parent = {
get x() { return this._x + 1; },
set x(v) { this._x = v * 2; }
};
var child = Object.create(parent);
child.x = 5; // Sets... what exactly to 10?
parent._x; // ???
child._x; // ???
parent.x; // ???
child.x; // ??? Take a minute to guess what you think each of the values should be. Click here to see the answers (which hopefully are what you expected).
So, JavaScript is passing the object in the lookup expression into the function, for both field access and field update. Something else subtle is going on, as well. Recall that before, when an update occurred on a field that wasn't present, JavaScript simply added it to the object. Now, on field update, we see that the assignment traverses the prototype chain to check for setters. This is fundamentally different from JavaScript before accessors―assignment never considered prototypes. So, our semantics needs to do two things:
- Pass the correct
thisargument to getters and setters; - Traverse the prototype chain for assignments.
Let's think about a simple way to pass the this argument to
getters:
(E-LookupGetter)
{ ⋯, str:[get:vg, set:vs], ⋯ }[strx] → vg({ ⋯, str:[get:vg, set:vs], ⋯ })
when strx = str
Here, we simply copy the object over into the first argument to the
function vg. We can (and do) desugar
functions to have an implicit first this argument to line up with
this invocation. But we need to think carefully about this rule's interaction
with prototype inheritance.
Here is E-Lookup-Proto from the original λJS:
(E-Lookup-Proto)
{ str1:v1, ⋯, "__proto__": vp, strn:vn, ⋯}[str] → vp[str]
when str ≠ str1, ⋯, strn, ⋯
Let's take a moment to look at this rule in conjunction with E-LookupGetter. If the field isn't found, and
__proto__ is present, it looks up the __proto__ field and performs the same
lookup on that object (we are eliding the case where proto is not present or
not an object for this presentation). But note something crucial: the
expression on the right hand side drops everything about the original
object except its prototype. If we applied this rule to child
above, the getter rule would pass parent to the getter instead of
child!
The solution is to keep track of the original object as we traverse the prototype chain. If we don't, the reduction relation simply won't have the information it needs to pass in to the getter or setter when it reaches the right point in the chain. This is a deep change―we need to modify our expressions to get it right:
p := [get: vg, set: vs] | [value: v]
v := str | { str1:p1, ⋯, strn:pn } | func(x ⋯) . e | ⋯
e := e[e] | e[e=e] | ev[e] | ev[e=e] | e(e, ⋯) | ⋯
And now, when we do a prototype lookup, we can keep track of the same
this argument (written as vt)
the whole way up the chain, and the rules for getters and setters can use this
new piece of the expression:
(E-Lookup-Proto)
{ str1:v1, ⋯, "__proto__": vp, strn:vn, ⋯}vt[str] → vpvt[str]
when str ≠ str1, ⋯, strn, ⋯
(E-LookupGetter)
{ ⋯, str:[get:vg, set:vs], ⋯ }vt[strx] → vg(vt)
when strx = str
(E-UpdateSetter)
{ ⋯, str:[get:vg, set:vs], ⋯}vt[strx=v'] → vs(vt,v')
when strx = str
This idea was inspired by Di Gianantonio, Honsell, and Liquori's 1998 paper, A lambda calculus of objects with self-inflicted extension. They use a similar encoding to model method dispatches in a small prototype-based object calculus. The original expressions, e[e] and e[e=e], simply copy values into the new positions once the subexpressions have reduced to values:
(E-Lookup) v[str] → vv[str] (E-Update) v[str=v'] → vv[str=v']
The final set of evaluation rules and expressions is a little larger:
p := [get: vg, set: vs] | [value: v]
v := str | { str1:p1, ⋯, strn:pn } | func(x ⋯) . e | ⋯
e := e[e] | e[e=e] | ev[e] | ev[e=e] | e(e, ⋯) | ⋯
(E-Lookup)
v[str] → vv[str]
(E-Update)
v[str=v'] → vv[str=v']
(E-LookupGetter)
{ ⋯, str:[get:vg, set:vs], ⋯ }vt[strx] → vg(vt)
when strx = str
(E-Lookup-Proto)
{ str1:v1, ⋯, "__proto__": vp, strn:vn, ⋯}vt[str] → vpvt[str]
when str ≠ str1, ⋯, strn, ⋯
(E-UpdateSetter)
{ ⋯, str:[get:vg, set:vs], ⋯}vt[strx=v'] → vs(vt,v')
when strx = str
(E-Update-Proto)
{ str1:v1, ⋯, "__proto__": vp, strn:vn, ⋯}vt[str=v'] → vpvt[str=v']
when str ≠ str1, ⋯, strn, ⋯
This is most of the rules―we've elided some details to only present the
key insight behind the new ones. Our full semantics (discussed in our last post), handles the
details of the arguments object that is implicitly available
within getters and setters, and using built-ins, like
defineProperty, to add already-defined functions to existing
objects as getters and setters.
S5: A Semantics for Today's JavaScript
Tags: JavaScript, Programming Languages, Semantics
Posted on 11 November 2011.The JavaScript language isn't static―the ECMAScript committee is working hard to improve the language, and browsers are implementing features both in and outside the spec, making it difficult to understand just what "JavaScript" means at any point in time. Existing implementations aren't much help―their goal is to serve pages well and fast. We need a JavaScript architecture that can help us make sense of the upcoming (and existing!) features of the language.
To this end, we've developed S5, an ECMAScript 5 runtime, built on λJS, with the explicit goal of helping people understand and tinker with the language. We built it to understand the features in the new standard, building on our previous efforts for the older standard. We've now begun building analyses for this semantics, and are learning more about it as we do so. We're making it available with the hope that you can join us in playing with ES5, extending it with new features, and building tools for it.
S5 implements the core features of ES5 strict mode. How do we know this? We've tested S5 against Test262 to measure our progress. We are, of course, not feature complete, but we're happy with our progress, which you can check out here.
A Malleable Implementation
The semantics of S5 is designed to be two things: a language for writing down the algorithms of the specification, and a translation target for JavaScript programs. We've implemented an interpreter for S5, and a desugaring function that translates JavaScript source into S5 programs.
We have a number of choices to make in defining desugaring. The ECMAScript standard defines a whole host of auxiliary functions and library routines that we must model. Putting these implementations directly in the desugaring function would work, but would make desugaring unnecessary brittle, and require recompilation on every minor change. Instead, we implement the bulk of this functionality as an S5 program. The majority of our work happens in an environment file that defines the spec in S5 itself. The desugaring defines a translation from the syntactic forms of JavaScript to the (smaller) language of S5, filled with calls into the functions defined in this environment.
This separation of concerns is what makes our implementation so amenable to
exploration. If you want to try something out, you can edit the environment
file and rerun whatever tests you care to learn about. Want to try a different
implementation of the == operator? Just change the definition, as
it was pulled from the spec, at line
300. Want a more expressive Object.toString() that doesn't
just print "[object Object]"? That's right
here. No changing an interpreter, no recompiling a desugaring function
necessary.
The environment we've written reflects the standard's algorithms as we understand them in terms of S5. The desugaring from JavaScript to S5 code with calls into this library is informed by the specification's definitions of expression and statement evaluation. We have confidence in the combination of desugaring and library implementation, given our increasing test coverage. Further, we know how to continue―implement more of the spec and pass more test cases!
More than λJS
S5 is built on λJS, but extends it in three significant ways:
- Explicit getters and setters;
- Object fields with attributes, like
writableandconfigurable, built-in; - Support for
eval().
Attributes on objects weren't treated directly in the original
λJS.
In 5th Edition, they are crucial to several security-relevant operations on
objects. For example, the standard specifies Object.freeze(),
which makes an object's properties forever unwritable. S5 directly models the
writable and configurable attributes that make this
operation possible, and make its implementation in S5 easy to understand.
λJS explicitly elided eval() from its semantics. S5
implements eval() by performing desugaring within the
interpreter and then interpreting the desugared code. We implement only
the strict mode version of eval, which restricts the environment
that the eval'd code can affect. With these restrictions, we can
implement eval in a straightforward way within our interpreter.
We'll cover the details of how we do this, and why it works, in another post.
Building on S5
There's a ton we can do with S5. More, in fact, than we can do by ourselves:- Experiment with Harmony features: ECMAScript 6, or Harmony, as it is often called, is being designed right now. Proxies, string interpolation, syntactic sugar for classes, and modules are just a few of the upcoming features. Modeling them in S5 would help us understand these features better as they get integrated into the language.
- Build Verification Tools: Verification based on objects' attributes is an interesting research problem―what can we prove about interacting programs if we know about unwritable fields and inextensible objects? Building this knowledge into a type-checker or a program analysis could give interesting new guarantees.
- Abstract Our Machine: Matt Might and David van Horn wrote about abstracting λJS for program analysis. We've added new constructs to the language since then. Do they make abstraction any harder?
- Complete the Implementation: We've made a lot of progress, but there's still more ground to cover. We need support for more language features, like JSON and regular expressions, that would move our implementation along immensely. We'll work on this more, but anyone who wants to get involved is welcome to help.
If any of this sounds interesting, or if you're just curious, go ahead and check out S5! It's open source and lives in a Github repository. Let us know what you do with it!
The Essence of JavaScript
Tags: JavaScript, Programming Languages, Semantics
Posted on 29 September 2011.Back in 2008, the group decided to really understand JavaScript. Arjun had built a static analysis for JavaScript from scratch. Being the honest chap that he is, he was forced to put the following caveat into the paper:
"We would like to formally prove that our analysis is sound. A sound analysis would guarantee that our tool will never raise a false alarm, an imporant usability concern. However, a proof of soundness would require a formal semantics for JavaScript and the DOM in browsers, and this does not exist."
A "formal semantics for JavaScript [...] does not exist"? Didn't he know
about the official documents on such matters, the ECMAScript standard?
ECMAScript 3rd edition, the standard at the time, was around 180 pages long,
written in prose and pseudocode. Reading it didn't help much. It includes
gems such as this description of the switch statement:
1. Let A be the list of CaseClause items in the first
CaseClauses, in source text order.
2. For the next CaseClause in A, evaluate CaseClause. If there is
no such CaseClause, go to step 7.
3. If input is not equal to Result(2), as defined by the !==
operator, go to step 2.
4. Evaluate the StatementList of this CaseClause.
5. If Result(4) is an abrupt completion then return Result(4).
6. Go to step 13.
7. Let B be the list of CaseClause items in the second
CaseClauses, in source text order.
8. For the next CaseClause in B, evaluate CaseClause. If there is
no such CaseClause, go to step 15.
9. If input is not equal to Result(8), as defined by the !==
operator, go to step 8.
10. Evaluate the StatementList of this CaseClause.
11. If Result(10) is an abrupt completion then return Result(10).
12. Go to step 18.
...
And this is just one of 180 pages of lesser or greater eloquence. With this as his formal reference, it's no wonder Arjun had a hard time making soundness claims.
Around the same time, Ankur Taly, Sergio Maffeis, and John Mitchell noticed the same problem. They presented a formal semantics for JavaScript in their APLAS 2008 paper. You can find their semantics here, and it is a truly staggering effort, running for 40+ pages (that's at least four times easier to understand!). However, we weren't quite satisfied. Their semantics formalizes the ECMAScript specification as written, and therefore inherits some of its weirdness, such as heap-allocated "scope objects", implicit coercions, etc. We still couldn't build tools over it, and were unwilling to do 40-page case analyses for proofs. Leo Meyerovich, peon extraordinaire and friend of the blog, felt the same:
"Challenging current attempts to analyze JavaScript, there is no formal semantics realistic enough to include many of the attack vectors we have discussed yet structured and tractable enough that anyone who is not the inventor has been able to use; formal proofs are therefore beyond the scope of this work."
How To Tackle JavaScript: The PLT Way
We decided to start smaller. In the fall of 2009, Arjun wrote down a semantics for the "core" of JavaScript that fits on just three pages (that's 60 times easier to understand!). This is great programming languages research—we defined away the hairy parts of the problem and focused on a small core that was amenable to proof. For these proofs, we could assume the existence of a trivial desugaring that maps real JavaScript programs into programs in the core semantics, which Arjun dubbed λJS.
Things were looking great until one night Arjun had a few too many glasses of wine and decided to implement desugaring. Along with Claudiu Saftoiu, he wrote a thousand lines of Haskell that turns JavaScript programs into λJS programs. Even worse, they implemented an interpreter for λJS, so the resulting programs actually run. They had therefore produced a JavaScript runtime.
Believe it or not, there are other groups in the business of creating JavaScript runtimes, namely Google, Mozilla, Microsoft, and a few more. And since they care about the correctness of their implementations, they have actual test suites. Which Arjun's system could run, and give answers for, that may or may not be the right ones:
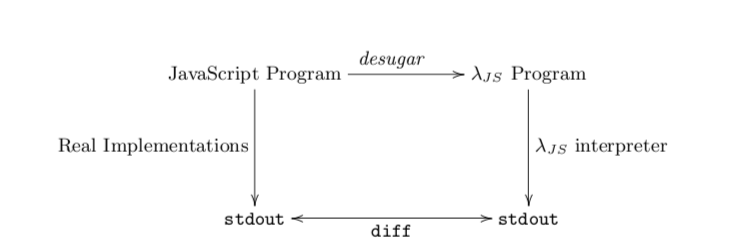
As it turns out, Arjun and Claudiu did a pretty good job. λJS agrees with Mozilla SpiderMonkey on a few thousand lines of tests. We say "agreed" and not "passed" because SpiderMonkey fails some of its own tests. Without any other standard of correctness, λJS strives for bug-compatibility with SpiderMonkey on those tests.
Building on λJS
λJS is discussed in our ECOOP paper, but it's the work built on λJS that's most interesting. We've built the following systems ourselves:
- A type-checker for JavaScript that employs a novel mix of type-checking and flow analysis ("flow typing"), discussed in our ESOP 2011 paper, and
- An extension to the above type-checker to verify ADsafe, as discussed in our USENIX Security 2011 paper.
- David van Horn and Matt Might use λJS to build an analytic framework for JavaScript,
- Rodolfo Toledo and Éric Tanter use λJS to specify aspects for JavaScript,
- IBEX, from Microsoft Research, uses λJS for its JavaScript backend to produce verified Web browser extensions, and
- Others have a secret reimplementation of λJS in Java. We are now enterprise-ready.
Want to use λJS to write JavaScript tools? Check out our software and let us know what you think!
Coming up next: The latest version of JavaScript, ECMAScript 5th ed.,
is vastly improved. We've nearly finished updating our JavaScript semantics to
match ECMAScript 5th ed. Our new semantics uses the official ECMAScript test
suite and tackles problems, such as eval, that the original
λJS elided. We'll talk about it next time. Update:
We've written about our update, dubbed S5, its semantics for accessors,
and a particularly interesting
example.
ADsafety
Tags: Browsers, JavaScript, Programming Languages, Security, Types, Verification
Posted on 13 September 2011.
A mashup is a webpage that mixes and mashes content from various sources. Facebook apps, Google gadgets, and various websites with embedded maps are obvious examples of mashups. However, there is an even more pervasive use case of mashups on the Web. Any webpage that displays third-party ads is a mashup. It's well known that third-party content can include third-party cookies; your browser can even block these if you're concerned about "tracking cookies". However, third party content can also include third-party JavaScript that can do all sorts of wonderful and malicious things (just some examples).
Is it possible to safely embed untrusted JavaScript on a page? Google Caja, Microsoft Web Sandbox, and ADsafe are language-based Web sandboxes that try to do so. Language-based sandboxing is a programming language technique that restricts untrusted code using static and runtime checks and rewriting potential dangerous calls to safe, trusted functions.
Sandboxing JavaScript, with all its corner cases, is particularly hard. A
single bug can easily break the entire sandboxing system. JavaScript sandboxes
do not clearly state their intended guarantees, nor do they clearly argue why
they are safe. 
Verifying Web Sandboxes
A year ago, we embarked on a project to verify ADsafe, Douglas Crockford's Web sandbox. ADsafe is admittedly the simplest of the aforementioned sandboxes. But, we were also after the shrimp bounty that Doug offers for sandbox-breaking bugs:
Write a program [...] that calls the alert function when run on any browser. If the program produces no errors when linted with the ADsafe option, then I will buy you a plate of shrimp. (link)A year later, we've produced a USENIX Security paper on our work, which we presented in San Francisco in August. The paper discusses the many common techniques employed by Web sandboxes and discusses the intricacies of their implementations. (TLDR: JavaScript and the DOM are really hard.) Focusing on ADsafe, it precisely states what ADsafety actually means. The meat of the paper is our approach to verifying ADsafe using types. Our verification leverages our earlier work on semantics and types for JavaScript, and also introduces some new techniques:
- Check out the ★s and ☠s in our object types; we use them to type-check "scripty" features of JavaScript. ☠ marks a field as "banned" and ★ specifies the type of all other fields.
- We also characterize JSLint as a type-checker. The Widget type presented in the paper specifies, in 20 lines, the syntactic restrictions of JSLint's ADsafety checks.
Unlike conventional type systems, ours does not prevent runtime errors. After all, stuck programs are safe because they trivially don't execute any code. If you think type systems only catch "method not found" errors, you should have a look at ours.
We found bugs in both ADsafe and JSLint that manifested as type errors. We reported all of them and they were promptly fixed by Doug Crockford. A big thank you to Doug for his encouragement, for answering our many questions, and for buying us every type of shrimp dish in the house.

Learn more about ADsafety! Check out:
- The paper, code, and proofs;
- Video of Arjun presenting at USENIX Security;
- ADsafe and JSLint.