The Brown PLT Blog

Articles by tag: Large Language Models
Iterative Student Program Planning using Transformer-Driven Feedback
Generating Programs Trivially: Student Use of Large Language Models
LLMs ⭢ Regular Expressions, Responsibly!
Tags: Large Language Models, Semantics, Tools
Posted on 11 December 2025.Do you use GenAI/LLMs to generate your regular expressions? We certainly do! But we always do it with trepidation, given the many slips that can occur with blindly pasting the output into a program. We may have been unclear in our prose, our prose may have been ambiguous, the domain may lend itself to ambiguity (what is a “date”?), the LLM may have misinterpreted what you said, the domain may have persistent misconceptions, and so on.
Oh, you read your regexes, you say? Is this a valid regex for dates?
^(?:(?:31-(?:0[13578]|1[02])-(?:\d{4}))|
(?:29|30-(?:0[13-9]|1[0-2])-(?:\d{4}))|
(?:29-02-(?:(?:\d\d(?:0[48]|[2468][048]|[13579][26]))|
(?:[048]000)))|
(?:0[1-9]|1\d|2[0-8]-(?:0[1-9]|1[0-2])-(?:\d{4})))
But we can do a lot better! Our new tool, PICK:Regex, does the following. It asks you for a prompt and sends it to a GenAI system. However, it doesn’t ask for one regex; instead, it uses an LLMs ability to interpret prose in multiple ways to generate multiple (about four) candidate expressions. (The details don’t matter, but if you want to you can open the images below in a new tab to read them more easily.)

In theory, that’s better than getting just one interpretation. But now you may have to read four regexes like the above, which is actually worse! Therefore, instead, PICK shows you concrete examples. Furthermore, the examples are carefully chosen to tell apart the regexes. You are then asked to upvote/downvote each example. As you do, you are actually voting on all the candidate regexes.
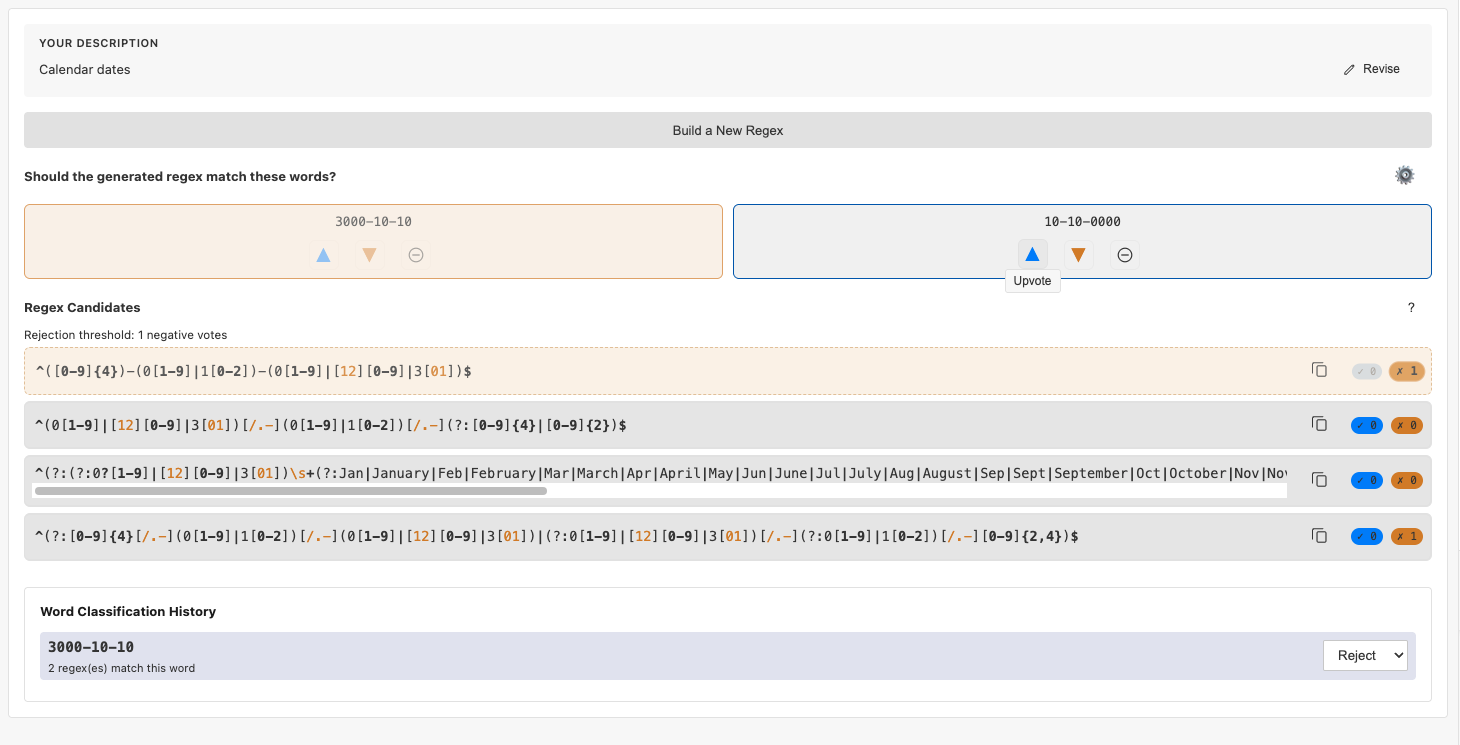
You can stop at any point (you’re always shown the regexes), but the process naturally halts when only one regex remains (this is your best candidate of the ones you’ve seen so far) or none remain (in which case it would have been dangerous to use the LLMs output!).
As you’re looking at examples, you may realize you could have provided a better prompt (or could have used a more expensive LLM). You don’t need to start over; you can revise your request. This generates regexes afresh, but critically, you don’t lose your hard work: your prior upvotes and downvotes are automatically applied to the new proposed regexes.
Also as you’re looking at examples, you might come up with some good ones of your own. You can type these into PICK and vote on them (i.e., provide both positive and negative examples), and PICK will add them to the example stream. Similarly, you can edit an example PICK has shown you before voting on it.
Finally, you can also change your mind. PICK shows you all your prior classifications at the bottom. If you change how you classified an example, that will update the scores of all the candidates.
PICK is based on the confluence of two very different bodies of ideas. It draws from cognitive science: the idea of understanding the abstract through the concrete, and the theory of contrasting cases. It also puts to work all the formal language closure properties you studied in a theory of computation class and wondered why and when they would ever be useful.
Enough prose! Please try PICK for yourself. It’s available as an extension from the Visual Studio Code Marketplace (it uses your VSCode LLM configuration). Visit this link, or search for SiddharthaPrasad.pick-regex in the Marketplace. If you don’t have a ready question, try a prompt like “countries of North America”—but before you do, what regex are you expecting? Think about it for a moment, then see what PICK offers you. Let us know what you think!
Iterative Student Program Planning using Transformer-Driven Feedback
Tags: Large Language Models, Education, Program Planning, User Studies
Posted on 05 July 2024.We’ve had a few projects now that address this idea of teaching students to plan out solutions to programming problems. A thus-far missing but critical piece is feedback on this planning process. Ideally we want to give students feedback on their plans before they commit to any code details. Our early studies had students express their plans in a semi-formalized way which would’ve allowed us to automatically generate feedback based on formal structure. However, our most recent project highlighted a strong preference towards more freedom in notation, with plans expressed in far less structured language. This presents a challenge when designing automated feedback.
So how do we interpret plans written with little to no restrictions on notation or structure, in order to still give feedback? We throw it at an LLM, right?
It’s never that simple. We first tried direct LLM feedback, handing the student plan to an LLM with instructions of what kinds of feedback to give. Preliminary feedback results ranged from helpful to useless to incorrect. Even worse, we couldn’t prevent the LLM from directly including a correct answer in its response.
So we built a different kind of feedback system. Student plans, expressed mostly in English, are translated into code via an LLM. (We do not allow the LLM to access the problem statement— otherwise it would silently correct student misconceptions when translating into code.) The resulting code is run against an instructor test suite, and the test suite results are shown to the student as feedback.
When we deployed this system, we found that the results from running the LLM-generated code against our instructor test suite seemed to serve as a useful proxy for student plan correctness. However, many issues from the LLM still caused a great deal of student frustration, especially from the LLM not having access to details from the problem statement.
LLMs are good at presenting correct code solutions and correcting errors, and there is clear incentive for these behaviors to improve. But these behaviors are sometimes counterproductive to student feedback. Creating LLM-based feedback systems still requires careful thought in both its design and presentation to students.
For more detail on our design and results, read here.
Generating Programs Trivially: Student Use of Large Language Models
Tags: Large Language Models, Education, Formal Methods, Properties, Testing, User Studies
Posted on 19 September 2023.The advent of large language models like GPT-3 has led to growing concern from educators about how these models can be used and abused by students in order to help with their homework. In computer science, much of this concern centers on how LLMs automatically generate programs in response to textual prompts. Some institutions have gone as far as instituting wholesale bans on the use of the tool. Despite all the alarm, however, little is known about whether and how students actually use these tools.
In order to better understand the issue, we gave students in an upper-level formal methods course access to GPT-3 via a Visual Studio Code extension, and explicitly granted them permission to use the tool for course work. In order to mitigate any equity issues around access, we allocated $2500 in OpenAI credit for the course, enabling free access to the latest and greatest OpenAI models.
Can you guess the total dollar value of OpenAI credit used by students?
We then analyzed the outcomes of this intervention, how and why students actually did and did not use the LLM.
Which of these graphs do you think best represents student use of GPT models over the semester?
When surveyed, students overwhelmingly expressed concerns about using GPT to help with their homework. Dominant themes included:
- Fear that using LLMs would detract from learning.
- Unfamiliarity with LLMs and issues with output correctness.
- Fear of breaking course rules, despite being granted explicit permission to use GPT.
Much ink has been spilt on the effect of LLMs in education. While our experiment focuses only on a single course offering, we believe it can help re-balance the public narrative about such tools. Student use of LLMs may be influenced by two opposing forces. On one hand, competition for jobs may cause students to feel they must have “perfect” transcripts, which can be aided by leaning on an LLM. On the other, students may realize that getting an attractive job is hard, and decide they need to learn more in order to pass interviews and perform well to retain their positions.
You can learn more about the work from the paper.