The Brown PLT Blog

Articles by tag: Linear Temporal Logic
LTL Tutor
Misconceptions In Finite-Trace and Infinite-Trace Linear Temporal Logic
Little Tricky Logics
Human Judgment as a Specification
Tags: Large Language Models, Semantics, Tools, Linear Temporal Logic
Posted on 09 June 2026.The rise of GenAI in programming clearly requires an accompanying rise in formal methods, to confirm that AI systems running wild are producing the solutions we actually want. That in turn requires that we specify what we want. This specification is necessarily mathematical, to take advantage of the formal methods tools. But most programmers know far less about formal specification than they do about programming. What can they do?
Getting Specifications the Bad Way
The key problem we’re tackling is: how do we go from the informal (usually prose) to the formal. A natural solution is: use LLMs to translate prose into the formal specifications. On the one hand, this is not absurd: LLMs can do a fairly good job at generating terms in many contemporary formal notations. Here’s Ron Minsky, tongue-in-cheek:
I wonder if a more plausible model is, you go to your large language model and say, ‘Please write me a specification for a function that sorts a list.’ And then it, like, spits something out. And then you look at it and think, yeah, that seems about right.
Richard Eisenberg’s response to this gets to the heart of the matter: How can we be sure that the generated specification is the right one? The human may have just plain been wrong. They may have been obviously wrong, or they could have been wrong in subtle ways. They may have been been ambiguous, and the LLM may have taken the wrong interpretation. There may also be common misconceptions about the language (which may then also be embedded in the language models). Or they may have been referring to things for which there is no clear ground truth, or the only truth is in their head: what they mean depends on their context. None of these problems is fixable by an LLM alone.
Humans in the Loop
We therefore think it’s important for humans to be in the loop while formalizing specifications. A true vibe-coder, by definition, isn’t going to care. Instead, we want to target the responsible programmer: they care about their work quality, but they are also human, i.e., busy, lazy, and so on. What can we do to help them?
We believe any solution should have two key characteristics:
-
It must be meaningful. Asking humans to pass judgment on complex and abstract statements is unlikely to be effective. Laziness, automation bias, inability to form good judgments, and a desire to get things done will all lead to meaningless confirmation.
-
It must be moderate. Asking lots of questions, no matter how simple, can be exhausting and will also lead to errors as the number of questions grows. We should try to make every human action be highly impactful and not ask users to perform too many actions.
Observe that it’s easy to have one and not the other. Telling people “you must read all the code generated by an LLM” is definitely meaningful—but it is not at all moderate (so most people won’t do it). Classical security alerts, which ask just one yes/no question, are moderate effort, but not meaningful (because the alternative is to not get the job done). The challenge is to push along both dimensions just far enough to get real value but not so far as to lose people.
Our Solution
A few months ago, we posted about PICK, a tool we built to help us make better use of LLMs to generate regular expressions. You give the LLM a prompt and get back not one regex but rather several plausible ones. Your usual options are to take what the model gives you, or to read the regexes yourself and try to figure out which is right. PICK does something else: it shows you concrete strings chosen to distinguish the candidates from one another, and asks you to upvote or downvote each. The regex that survives your votes wins. It’s worth reading that post to get a sense of the workflow.
That post doesn’t mention two important things.
First, that we now have experimental results that show that this workflow works very well.
Second, that this isn’ tied to regular expressions alone. We have built PICK for three illustrative domains so far, intentionally chosen to be unlike one another: regular expressions, linear temporal logic (LTL), and attribute-based access control (ABAC). In all three the algorithm is the same: generate candidates, sample from set differences, present a pair of scenarios, update scores, converge or admit defeat. The workflow does not have to be redesigned per domain. (Readers of our older post on differential analysis will see the family resemblance. PICK is the in-the-loop version, where the semantic differences between still-viable candidates drive the next question.)
What lets the same algorithm work across all three domains is that they share two key properties:
- Closure under negation and intersection — so the difference between two candidates is itself expressible.
- Sampling from that difference — so the system can show the user concrete cases where the candidates disagree.
The machinery here is not exotic. It is the stuff of a sophomore theory-of-computation course: closure properties, set differences, and witness generation. Many of the formalisms programmers use every day already have it — either inherently (Boolean logic, network routing rules, package-version constraints) or by the standard trick of bounding the universe of discourse (almost anything at which you would point a SAT/SMT solver). The properties everyone is told in class are important and then never quite sees applied are, in 2026, what stand between you and a confidently wrong access-control policy. And motivated by, of all things, cognitive science principles. So at the very least, maybe we can improve how we teach the theory of computation!
How Synthesis Also Subtly Fails
So yes, PICK is a validation workflow: you have some intent, the model proposes candidates, and PICK helps you check those candidates against what you meant. But that framing undersells the idea. What PICK also does is recover something synthesis tends to erase: an independent witness to user intent.
To see why that witness matters, it helps to remember what verification was for.
Verification is famously written P ⊧ ɸ: a program P implements a property ɸ. The check is informative precisely because P and ɸ are written independently. If both encode the same misconception, agreement rules out nothing; the redundancy disappears. (And this is the danger of having both sides of the verification coin generated by an LLM. PICK intervenes to make sure the LLM is not the only source of ɸ.)
Now consider synthesis: ɸ ⟹ P. The program is correct-by-construction. However, that means it is also incorrect-by-construction. When ɸ is wrong, the resulting P is wrong in precisely the same way, and no cross-check of P against ɸ can catch that. This was already true of classical deductive synthesis and of programming-by-example. It is wildly more true of synthesis-by-LLM. The LLM only sees the user’s natural language, which is a lossy hint of what they want.
Piling on more LLMs does not necessarily fix this. They share training data, share priors, and often share misconceptions. More models give you more agreement, faster. They do not necessarily give you more redundancy, which is what verification has always been about. And neither can know the user’s true intent: which is exactly what PICK is about.
Human Judgment as Specification
In PICK,
that independent witness is not a separately-written spec — it lives in the user’s classifications: each accept or reject is a commitment to a concrete behavior, and the candidates that survive must be consistent with all of them together. Taken as a whole, those commitments expose what the original prompt left unstated. Suppose the prompt was “a regex for dates”, and the model came back with several candidates. PICK puts strings in front of you: yes to 1/15/2025 and no to 13/01/2025 declares a position on day-month-year versus month-day-year — a question the prompt left implicit and the user may never have answered formally, even to themselves. The user arrives with a vague intent; PICK helps sharpen it — call it spec elucidation — not by interrogating them about formulae but by forcing them to commit on questions the prompt leaves implicit.
This is also why PICK can usefully fail. Sometimes none of the model’s candidates is right, and PICK ends with zero survivors. Under the spec-elucidation reading, that outcome means: the commitments you made through classification could not be satisfied by anything the model produced. Better to know than to ship the regex anyway.
This is also why we do not believe PICK becomes less useful as models improve. Better models do not make user intent more articulate — asked for “a regex matching countries of North America”, a more capable model still cannot tell you whether you want the Caribbean included, or where you want to stop heading south. Better models produce better candidates, faster — which shifts user effort precisely toward the work PICK is built to support.
To learn more, read our ECOOP 2026 paper, or try out the PICK:Regex tool in VS Code.
If you have a formal language with the closure properties above — we suspect you would be surprised how many do — we would very much like to hear from you.
LTL Tutor
Tags: Linear Temporal Logic, Education, Formal Methods, Misconceptions, Properties, Tools, Verification
Posted on 08 August 2024.We have been engaged in a multi-year project to improve education in Linear Temporal Logic (LTL) [Blog Post 1, Blog Post 2]. In particular, we have arrived at a detailed understanding of typical misconceptions that learners and even experts have. Our useful outcome from our studies is a set of instruments (think “quizzes”) that instructors can deploy in their classes to understand how well their students understand the logic and what weaknesses they have.
However, as educators, we recognize that it isn’t always easy to add new materials to classes. Furthermore, your students make certain mistakes—now what? They need explanations of what went wrong, need additional drill problems, and need checks whether they got the additional ones right. It’s hard for an educator to make time for all that. And if one is an independent learner, they don’t even have access to such educators.
Recognizing these practical difficulties, we have distilled our group’s expertise in LTL into a free online tutor:
We have leveraged insights from our studies to create a tool designed to be used by learners with minimal prior instruction. All you need is a brief introduction to LTL (or even just propositional logic) to get started. As an instructor, you can deliver your usual lecture on the topic (using your preferred framing), and then have your students use the tool to grow and to reinforce their learning.
In contrast to traditional tutoring systems, which are often tied to a specific curriculum or course, our tutor adaptively generates multiple-choice question-sets in the context of common LTL misconceptions.
- The tutor provides students who get a question wrong with feedback in terms of their answer’s relationship to the correct answer. Feedback can take the form of visual metaphors, counterexamples, or an interactive trace-stepper that shows the evaluation of an LTL formula across time.

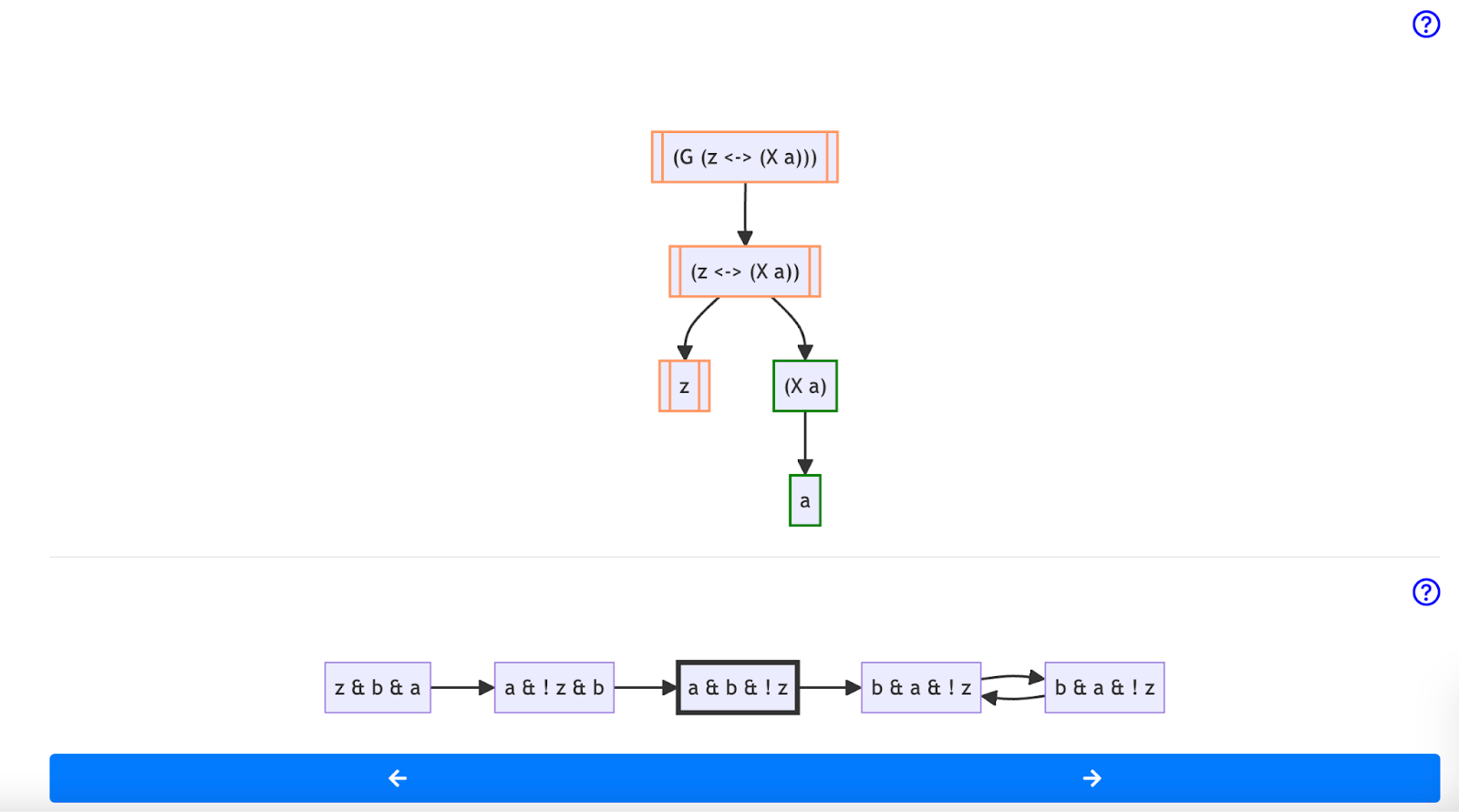
(G (z <-> X(a))) in the third state of a trace. While the overall formula is not satisfied at this moment in time, the sub-formula (X a) is satisfied. This allows learners to explore where their understanding of a formula may have diverged from the correct answer.
- If learners consistently demonstrate the same misconception, the tutor provides them further insight in the form of tailored text grounded in our previous research.
- Once it has a history of misconceptions exhibited by the student, the tutor generates novel, personalized question sets designed to drill students on their specific weaknesses. As students use the tutor, the system updates its understanding of their evolving needs, generating question sets to address newly uncovered or pertinent areas of difficulty.
We also designed the LTL Tutor with practical instructor needs in mind:
- Curriculum Agnostic: The LTL Tutor is flexible and not tied to any specific curriculum. You can seamlessly integrate it into your existing course without making significant changes. It both generates exercises for students and allows you to import your own problem sets.
- Detailed Reporting: To track your class’s progress effectively, you can create a unique course code for your students to enter, so you can get detailed insights into their performance.
- Self-Hostable: If you prefer to have full control over your data, the LTL Tutor can easily be self-hosted.
To learn more about the Tutor, please read our paper!
Misconceptions In Finite-Trace and Infinite-Trace Linear Temporal Logic
Tags: Linear Temporal Logic, Crowdsourcing, Misconceptions, User Studies, Verification
Posted on 07 July 2024.We now also have an automated tutor that puts this material to work to help students directly.
Over the past three years and with a multi-national group of collaborators, we have been digging deeper into misconceptions in LTL (Linear Temporal Logic) and studying misconceptions in LTLf, a promising variant of LTL restricted to finite traces. Why LTL and LTLf? Because beyond their traditional uses in verification and now robot synthesis, they support even more applications, from image processing to web-page testing to process-rule mining. Why study misconceptions? Because ultimately, human users need to fully understand what a formula says before they can safely apply synthesis tools and the like.
Our original post on LTL misconceptions gives more background and motivation. It also explains the main types of questions we use: translations between English specifications and formal specifications.
So what’s new this time around?
First, we provide two test instruments that have been field tested with several audiences:
-
One instrument [PDF] focuses on the delta between LTL and LTLf. If you know LTL but not LTLf, give it a try! You’ll come away with hands-on experience of the special constraints that finite traces bring.
-
The other instrument [PDF] is for LTL beginners — to see what preconceptions they bring to the table. It assumes basic awareness of G (“always”), F (“eventually”), and X (“next state”). It does not test the U (“until”) operator. Live survey here.
Second, we find evidence for several concrete misconceptions in the data. Some misconceptions were identified in prior work and are confirmed here. Others are new to this work.
For example, consider the LTLf formula:
G(red => X(X(red))). What finite traces satisfy it?In particular, can any finite traces that have
redtrue at some point satisfy the formula?Click to show answer:
No, because wheneverredis true it must be true again two states later, but every finite trace will eventually run out of states.
Now consider the LTL formula
F(X(X(red))). Is it true for an infinite trace whereredis true exactly once?Click to show answer:
Yes. But interestingly, some of our LTL beginners said no on the grounds thatX(X(red))ought to "spread out" and constrain three states in a row.
Third, we provide a code book of misconceptions and how to identify them in new data [PDF].
For more details, see the paper.
See also our LTL Tutor (traditional LTL only, not finite-trace).
Little Tricky Logics
Tags: Linear Temporal Logic, Crowdsourcing, Misconceptions, User Studies, Verification
Posted on 05 November 2022.We also have followup work that continues to explore LTL and now also studies finite-trace LTL. In addition, we also have an automated tutor that puts this material to work to help students directly.
LTL (Linear Temporal Logic) has long been central in computer-aided verification and synthesis. Lately, it’s also been making significant inroads into areas like planning for robots. LTL is powerful, beautiful, and concise. What’s not to love?
However, any logic used in these settings must also satisfy the central goal of being understandable by its users. Especially in a field like synthesis, there is no second line of defense: a synthesizer does exactly what the specification says. If the specification is wrong, the output will be wrong in the same way.
Therefore, we need to understand how people comprehend these logics. Unfortunately, the human factors of logics has seen almost no attention in the research community. Indeed, if anything, the literature is rife with claims about what is “easy” or “intuitive” without any rigorous justification for such claims.
With this paper, we hope to change that conversation. We bring to bear on this problem several techniques from diverse areas—but primarily from education and other social sciences (with tooling provided by computer science)—to understand the misconceptions people have with logics. Misconceptions are not merely mistakes; they are validated understanding difficulties (i.e., having the wrong concept), and hence demand much greater attention. We are especially inspired by work in physics education on the creation of concept inventories, which are validated instruments for rapidly identifying misconceptions in a population, and take steps towards the creation of one.
Concretely, we focus on LTL (given its widespread use) and study the problem of LTL understanding from three different perspectives:
-
LTL to English: Given an LTL formula, can a reader accurately translate it into English? This is similar to what a person does when reading a specification, e.g., when code-reviewing work or studying a paper.
-
English to LTL: Given an English statement, can a reader accurately express it in LTL? This skill is essential for specification and verification.
Furthermore, “understanding LTL” needs to be divided into two parts: syntax and semantics. Therefore, we study a third issue:
- Trace satisfaction: Given an LTL formula and a trace (sequence of states), can a reader accurately label the trace as satisfying or violating? Such questions directly test knowledge of LTL semantics.
Our studies were conducted over multiple years, with multiple audiences, and using multiple methods, with both formative and confirmatory phases. The net result is that we find numerous misconceptions in the understanding of LTL in all three categories. Notably, our studies are based on small formulas and traces, so we expect the set of issues will only grow as the instruments contain larger artifacts.
Ultimately, in addition to
- finding concrete misconceptions,
we also:
-
create a codebook of misconceptions that LTL users have, and
-
provide instruments for finding these misconceptions.
We believe all three will be of immediate use to different communities, such as students, educators, tool-builders, and designers of new logic-based languages.
For more details, see the paper.
See also our LTL Tutor.