The Brown PLT Blog

Slimming Languages by Reducing Sugar
Tags: JavaScript, Programming Languages, Resugaring, Semantics
Posted on 08 January 2016.JavaScript is a crazy language. It’s defined by 250 pages of English prose, and even the parts of the language that ought to be simple, like addition and variable scope, are very complicated. We showed before how to tackle this problem using λs5, which is an example of what’s called a tested semantics.
You can read about λs5 at the above link. But the basic idea is that λs5 has two parts:
- A small core language that captures the essential parts of JavaScript, without all of its foibles, and
- A desugaring function that translates the full language down to this small core.
(We typically call this core language λs5, even though technically speaking it’s only part of what makes up λs5.)
These two components together give us an implementation of JavaScript:
to run a program, you desugar it to λs5, and then
run that program. And with this implementation, we can run
JavaScript’s conformance test suite to check that
λs5 is accurate: this is why it’s called a tested
semantics. And lo, λs5 passes the relevant portion
of the test262 conformance suite.
The Problem
Every blog post needs a problem, though. The problem with λs5 lies in desugaring. We just stated that JavaScript is complicated, while the core language for λs5 is simple. This means that the complications of JavaScript must be dealt with not in the core language, but instead in desugaring. Take an illustrative example. Here’s a couple of innocent lines of JavaScript:
function id(x) {
return x;
}
These couple lines desugar into the following λs5 code:
{let
(%context = %strictContext)
{ %defineGlobalVar(%context, "id");
{let
(#strict = true)
{"use strict";
{let
(%fobj4 =
{let
(%prototype2 = {[#proto: %ObjectProto,
#class: "Object",
#extensible: true,]
'constructor' : {#value (undefined) ,
#writable true ,
#configurable false}})
{let
(%parent = %context)
{let
(%thisfunc3 =
{[#proto: %FunctionProto,
#code: func(%this , %args)
{ %args[delete "%new"];
label %ret :
{ {let
(%this = %resolveThis(#strict,
%this))
{let
(%context =
{let
(%x1 = %args
["0" , null])
{[#proto: %parent,
#class: "Object",
#extensible: true,]
'arguments' : {#value (%args) ,
#writable true ,
#configurable false},
'x' : {#getter func
(this , args)
{label %ret :
{break %ret %x1}} ,
#setter func
(this , args)
{label %ret :
{break %ret %x1 := args
["0" , {[#proto: %ArrayProto,
#class: "Array",
#extensible: true,]}]}}}}})
{break %ret %context["x" , {[#proto: null,
#class: "Object",
#extensible: true,]}];
undefined}}}}},
#class: "Function",
#extensible: true,]
'prototype' : {#value (%prototype2) ,
#writable true ,
#configurable true},
'length' : {#value (1.) ,
#writable true ,
#configurable true},
'caller' : {#getter %ThrowTypeError ,
#setter %ThrowTypeError},
'arguments' : {#getter %ThrowTypeError ,
#setter %ThrowTypeError}})
{ %prototype2["constructor" = %thisfunc3 , null];
%thisfunc3}}}})
%context["id" = %fobj4 ,
{[#proto: null, #class: "Object", #extensible: true,]
'0' : {#value (%fobj4) ,
#writable true ,
#configurable true}}]}}}}}
This is a bit much. It’s hard to read, and it’s hard for tools to process. But more to the point, λs5 is meant to be used by researchers, and this code bloat has stood in the way of researchers trying to adopt it. You can imagine that if you’re trying to write a tool that works over λs5 code, and there’s a bug in your tool and you need to debug it, and you have to wade through that much code just for the simplest of examples, it’s a bit of a nightmare.
The Ordinary Solution
So, there’s too much code. Fortunately there are well-known solutions to this problem. We implemented a number of standard compiler optimization techniques to shrink the generated λs5 code, while preserving its semantics. Here’s a boring list of the Semantics-Preserving optimizations we used:
- Dead-code elimination
- Constant folding
- Constant propogation
- Alias propogation
- Assignment conversion
- Function inlining
- Infer type & eliminate static checks
- Clean up unused environment bindings
Most of these are standard textbook optimizations; though the last two are specific to λs5. Anyhow, we did all this and got… 5-10% code shrinkage.
The Extraordinary Solution
That’s it: 5-10%.
Given the magnitude of the code bloat problem, that isn’t nearly enough shrinkage to be helpful. So let’s take a step back and ask where all this bloat came from. We would argue that code bloat can be partitioned into three categories:
- Intended code bloat. Some of it is intentional. λs5 is a small core language, and there should be some expansion as you translate to it.
- Incidental code bloat. The desugaring function from JS to λs5 is a simple recursive-descent function. It’s purposefully not clever, and as a result it sometimes generates redundant code. And this is exactly what the semantics-preserving rewrites we just mentioned get rid of.
- Essential code bloat. Finally, some code bloat is due to the semantics of JS. JS is a complicated langauge with complicated features, and they turn into complicated λs5 code.
There wasn’t much to gain by way of reducing Intended or Incidental code bloat. But how do you go about reducing Essential code bloat? Well, Essential bloat is the code bloat that comes from the complications of JS. To remove it, you would simplify the language. And we did exactly that! We defined five Semantics-Altering transformations:
- (IR) Identifier restoration: pretend that JS is lexically scoped
- (FR) Function restoration: pretend that JS functions are just functions and not function-object-things.
- (FA) Fixed arity: pretend that JS functions always take as many arguments as they’re declared with.
- (UAE) Assertion elimination: unsafely remove some runtime checks (your code is correct anyways, right?)
- (SAO) Simplifying arithmetic operators: eliminate strange behavior for basic operators like “+”.
These semantics-altering transformations blasphemously break the language. This is actually OK, though! The thing is, if you’re studying JS or doing static analysis, you probably already aren’t handling the whole language. It’s too complicated, so instead you handle a sub-language. And this is exactly what these semantics-altering transformations capture: they are simplifying assumptions about the JS language.
Lessons about JavaScript
And we can learn about JavaScript from them. We implemented these transformations for λs5, and so we could run the test suite with the transformations turned on and see how many tests broke. This gives a crude measure of “correctness”: a transformation is 50% correct if it breaks half the tests. Here’s the graph:
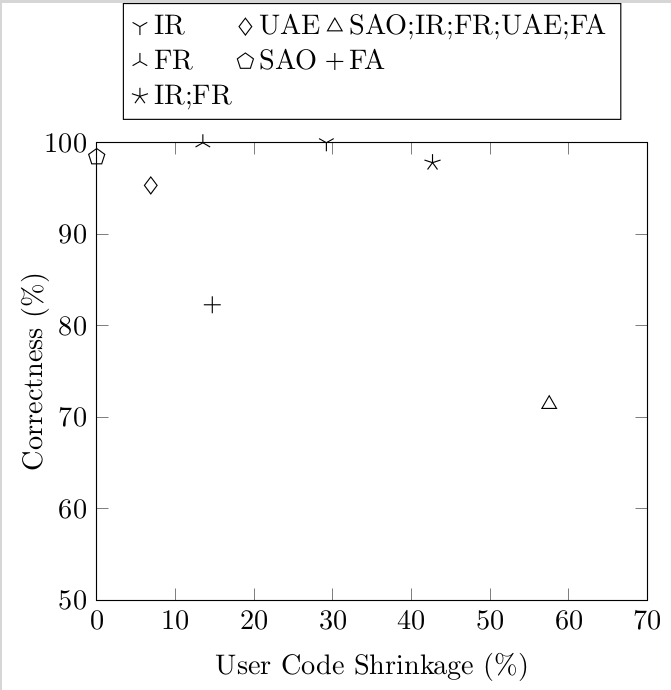
Notice that the semantics-altering transformations shrink code by more than 50%: this is way better than the 5-10% that the semantics-preserving ones gave. Going back to the three kinds of code bloat, this shows that most code bloat in λs5 is Essential: it comes from the complicated semantics of JS, and if you simplify the semantics you can make it go away.
Next, here’s the shrinkages of each of the semantics-altering transformations:
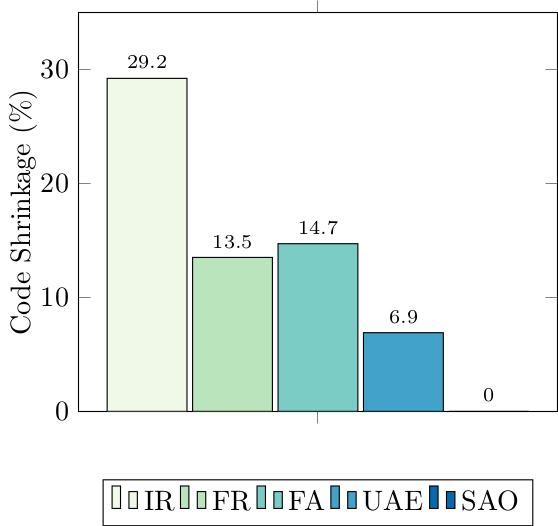
Since these semantics-altering transformations are simplifications of JS semantics, and desugared code size is a measure of complexity, you can view this graph as a (crude!) measure of complexity of language features. In this light, notice IR (Identifier Restoration): it crushes the other transformations by giving 30% code reduction. This shows that JavaScript’s scope is complex: by this metric 30% of JavaScript’s complexity is due to its scope.
Takeaway
These semantics-altering transformations give semantic restrictions on JS. Our paper makes these restrictions precise. And they’re exactly the sorts of simplifying assumptions that papers need to make to reason about JS. You can even download λs5 from git and implement your analysis over λs5 with a subset of these restrictions turned on, and test it. So let’s work toward a future where papers that talk about JS say exactly what sub-language of JS they mean.
The Paper
This is just a teaser: to read more, see the paper.