The Brown PLT Blog

Applying Cognitive Principles to Model-Finding Output
Tags: User Studies, Verification, Visualization
Posted on 26 April 2022.Model-finders produce output to help users understand the specifications they have written. They therefore effectively make assumptions about how these will be processed cognitively, but are usually unaware that they are doing so. What if we apply known principles from cognitive science to try to improve the output of model-finders?
Model Finding and Specification Exploration
Model-finding is everywhere. SAT and SMT solvers are the canonical model-finders: given a logical specification, they generate a satisfying instance (a “model”) or report that it’s impossible. Their speed and generality have embedded them in numerous back-ends. They are also used directly for analysis and verification, e.g., through systems like Alloy.
One powerful modality enabled by tools like Alloy is the exploration of specifications. Usually, model-finders are used for verification: you have a specification and some properties about it, and a verifier tells you whether the properties are satisfied or not. However, we often don’t have properties; we just want to understand the consequences of a design. While a conventional verifier is useless in this setting, model-finders have no problem with it: they will generate models of the specification that show different possible ways in which it can be realized.
Presenting Exploration
The models generated by exploration (or even by verification, where they are typically counterexamples) can be presented in several ways. For many users, the most convenient output is visual. Here, for instance, is a typical image generated using the Sterling visualizer:
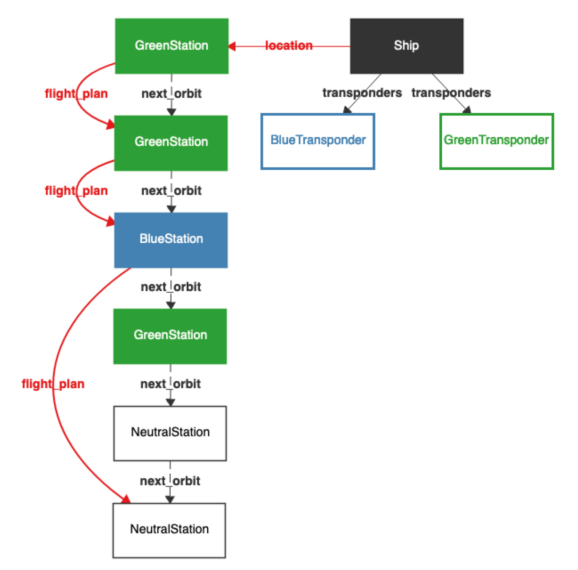
As of this writing, Alloy will let you sequentially view one model at a time.
Exploration for Understanding
The purpose of showing these models is to gain understanding. It is therefore reasonable to ask what forms of presentation would be most useful to enable the most understanding. In earlier work we studied details of how each model is shown. That work is orthogonal to what we do here.
Here, we are interested in how many models, and of what kind, should be displayed. We draw on a rich body of literature in perceptual psychology going back to seminal work by Gibson and Gibson in 1955. A long line of work since then has explored several dimensions of this, resulting in a modern understanding of contrasting cases. In this work, you don’t show a single result; rather, you show a set of similar examples, to better help people build models of what they are seeing. Since our goal is to help people understand a specification through visual output, it was natural to ask whether any of this literature could help in our setting.
Our Study
We concretely studied numerous experimental conditions involving different kinds of contrasting cases, where we show multiple models on screen at once. Critically, we looked at the use of both positive and negative models. Positive models are what you expect: models of the specification. In contrast, “negative” models are ones that don’t model the specification.
There can, of course, be an infinite number of negative models, most of which are of no use whatsoever: if I write a specification of a leader-election protocol, a whale or a sandwich are legitimate negative models. What we are interested in is “near miss” models, i.e., ones that could almost have been models but for a small difference. Our theory was that showing these models would help a user better understand the “space” of their model. (In this, we were inspired by prior work by Montaghmi and Rayside.)
Our Findings
We study these questions through both crowdsourced and talkaloud studies, and using both quantitative and qualitative methods. We find that in this setting, the use of multiple models does not seem to have been a big win. (Had it been, we would still have to confront the problem of how to fit all that information onto a screen in the general case.) The use of negative instances does seem to be helpful. We also constructed novel modes of output such as where a user can flip between positive and negative instances, and these seem especially promising.
Of course, our findings come with numerous caveats. Rather than think of our results as in any way definitive, we view this as formative work for a much longer line of research at the intersection of formal methods and human-computer interaction. We especially believe there is enormous potential to apply cognitive science principles in this space, and our paper provides some very rough, preliminary ideas of how one might do so.
For More Details
You can read about all this in our paper. Be warned, the paper is a bit of heavy going! There are a lot of conditions and lots of experiments and data. But hopefully you can get the gist of it without too much trouble.