The Brown PLT Blog

Articles by tag: User Studies
Argus: Interactively Debugging Rust trait Errors
Misconceptions In Finite-Trace and Infinite-Trace Linear Temporal Logic
Iterative Student Program Planning using Transformer-Driven Feedback
Forge: A Tool to Teach Formal Methods
Finding and Fixing Standard Misconceptions About Program Behavior
Privacy-Respecting Type Error Telemetry at Scale
Profiling Programming Language Learning
Observations on the Design of Program Planning Notations for Students
Conceptual Mutation Testing
Generating Programs Trivially: Student Use of Large Language Models
A Grounded Conceptual Model for Ownership Types in Rust
What Happens When Students Switch (Functional) Languages
Little Tricky Logics
Performance Preconceptions
Structural Versus Pipeline Composition of Higher-Order Functions
Plan Composition Using Higher-Order Functions
Towards a Notional Machine for Runtime Stacks and Scope
Gradual Soundness: Lessons from Static Python
Applying Cognitive Principles to Model-Finding Output
Student Help-Seeking for (Un)Specified Behaviors
Developing Behavioral Concepts of Higher-Order Functions
Adversarial Thinking Early in Post-Secondary Education
Teaching and Assessing Property-Based Testing
Students Testing Without Coercion
Using Design Alternatives to Learn About Data Organizations
What Help Do Students Seek in TA Office Hours?
Can We Crowdsource Language Design?
Crowdsourcing User Studies for Formal Methods
User Studies of Principled Model Finder Output
The PerMission Store
Examining the Privacy Decisions Facing Users
CS Student Work/Sleep Habits Revealed As Possibly Dangerously Normal
Social Ratings of Application Permissions (Part 4: The Goal)
Social Ratings of Application Permissions (Part 3: Permissions Within a Domain)
Social Ratings of Application Permissions (Part 2: The Effect of Branding)
Social Ratings of Application Permissions (Part 1: Some Basic Conditions)
Sharing is Scaring: Why is Cloud File-Sharing Hard?
Tags: Semantics, User Studies, Verification
Posted on 25 August 2025.Here is an actual situation we were asked to help non-technical computer users with:
Alice and Bob want to collaborate on a flyer for a social event. They are more comfortable with Word than with cloud-based tools like Google Docs. They have both heard that Dropbox is a good way to share and jointly edit files.
Alice thus creates a draft of the flyer F on Dropbox. She then shares F with Bob. Bob makes a change using Word and informs Alice he has done so. Alice opens F and sees no change. Bob confirms he is editing a file that is in Dropbox. They have several baffling rounds of exchange.
Do you see the problem? No? Here’s the critical question: How did Alice share F? Alice dragged the file from the Folder interface into Google Mail. (Do you see it now?)
The problem is that “sharing” means at least two very different things: providing a link to a single shared resource, or making a copy of the resource. Each one is correct for some contexts and wrong for others.
Does this sound familiar? To us, it certainly is! It’s the same kind of problem we saw when studying programming misconceptions, work that we have studied in great detail as part of our work on SMoL and the SMoL Tutor. Indeed, in this work, we call this the central analogy: the deep semantic similarity between
- sharing document links ↔ aliasing,
- downloading or attaching documents ↔ copying objects, and
- editing documents ↔ mutation.
We therefore find it especially unsurprising that when you combine mutation with sharing, people get confused. (Of course, there may be a deeper problem: that people are just not very good at reasoning about sharing and mutation. Cloud file-sharing and programming may just be two concrete instantiations of that abstract difficulty, and the same problems may arise in other domains as well.) Essentially, cloud file-sharing operations form an end-user instruction set architecture (EUISA) over which users “program” to achieve their goals.
This paper builds on this idea in the following ways:
- We identify this analogy both in the abstract and through several concrete examples (drawn from personal experience).
- We use our knowledge of programming semantics misconceptions to design corresponding cloud file-sharing situations, and show that people are confused there also.
- Drawing on the computing education literature, we devise an interesting way to get crowdsourcing subjects to not only “trace” but also “program” over the EUISA, and show that difficulties extend to both situations.
- We present a formal semantics for cloud file-sharing.
- We then discuss how this formal semantics might be employed to help end-users.
For more details, see our paper!
As a fun aside: The formal model is built using Forge. We were going to build a custom visualization but, to get a quick prototype in place, we used Cope and Drag. But the CnD spec was so good that we never needed to build that custom visualization!
Argus: Interactively Debugging Rust trait Errors
Tags: Rust, Tools, Types, User Studies
Posted on 29 April 2025.Traits are a source of bewildering error messages in the Rust community and people have spent money and time trying to improve the resulting diagnostics. We took a different approach. We analyzed a community suite of difficult-to-debug trait errors and formed hypotheses about why they were difficult for engineers to debug. Then, we built an interactive debugger that developers can use in the IDE to debug trait errors. Find more details about our process, the tool, and our paper in our Cognitive Engineering Lab blog post.
Misconceptions In Finite-Trace and Infinite-Trace Linear Temporal Logic
Tags: Linear Temporal Logic, Crowdsourcing, Misconceptions, User Studies, Verification
Posted on 07 July 2024.We now also have an automated tutor that puts this material to work to help students directly.
Over the past three years and with a multi-national group of collaborators, we have been digging deeper into misconceptions in LTL (Linear Temporal Logic) and studying misconceptions in LTLf, a promising variant of LTL restricted to finite traces. Why LTL and LTLf? Because beyond their traditional uses in verification and now robot synthesis, they support even more applications, from image processing to web-page testing to process-rule mining. Why study misconceptions? Because ultimately, human users need to fully understand what a formula says before they can safely apply synthesis tools and the like.
Our original post on LTL misconceptions gives more background and motivation. It also explains the main types of questions we use: translations between English specifications and formal specifications.
So what’s new this time around?
First, we provide two test instruments that have been field tested with several audiences:
-
One instrument [PDF] focuses on the delta between LTL and LTLf. If you know LTL but not LTLf, give it a try! You’ll come away with hands-on experience of the special constraints that finite traces bring.
-
The other instrument [PDF] is for LTL beginners — to see what preconceptions they bring to the table. It assumes basic awareness of G (“always”), F (“eventually”), and X (“next state”). It does not test the U (“until”) operator. Live survey here.
Second, we find evidence for several concrete misconceptions in the data. Some misconceptions were identified in prior work and are confirmed here. Others are new to this work.
For example, consider the LTLf formula:
G(red => X(X(red))). What finite traces satisfy it?In particular, can any finite traces that have
redtrue at some point satisfy the formula?Click to show answer:
No, because wheneverredis true it must be true again two states later, but every finite trace will eventually run out of states.
Now consider the LTL formula
F(X(X(red))). Is it true for an infinite trace whereredis true exactly once?Click to show answer:
Yes. But interestingly, some of our LTL beginners said no on the grounds thatX(X(red))ought to "spread out" and constrain three states in a row.
Third, we provide a code book of misconceptions and how to identify them in new data [PDF].
For more details, see the paper.
See also our LTL Tutor (traditional LTL only, not finite-trace).
Iterative Student Program Planning using Transformer-Driven Feedback
Tags: Large Language Models, Education, Program Planning, User Studies
Posted on 05 July 2024.We’ve had a few projects now that address this idea of teaching students to plan out solutions to programming problems. A thus-far missing but critical piece is feedback on this planning process. Ideally we want to give students feedback on their plans before they commit to any code details. Our early studies had students express their plans in a semi-formalized way which would’ve allowed us to automatically generate feedback based on formal structure. However, our most recent project highlighted a strong preference towards more freedom in notation, with plans expressed in far less structured language. This presents a challenge when designing automated feedback.
So how do we interpret plans written with little to no restrictions on notation or structure, in order to still give feedback? We throw it at an LLM, right?
It’s never that simple. We first tried direct LLM feedback, handing the student plan to an LLM with instructions of what kinds of feedback to give. Preliminary feedback results ranged from helpful to useless to incorrect. Even worse, we couldn’t prevent the LLM from directly including a correct answer in its response.
So we built a different kind of feedback system. Student plans, expressed mostly in English, are translated into code via an LLM. (We do not allow the LLM to access the problem statement— otherwise it would silently correct student misconceptions when translating into code.) The resulting code is run against an instructor test suite, and the test suite results are shown to the student as feedback.
When we deployed this system, we found that the results from running the LLM-generated code against our instructor test suite seemed to serve as a useful proxy for student plan correctness. However, many issues from the LLM still caused a great deal of student frustration, especially from the LLM not having access to details from the problem statement.
LLMs are good at presenting correct code solutions and correcting errors, and there is clear incentive for these behaviors to improve. But these behaviors are sometimes counterproductive to student feedback. Creating LLM-based feedback systems still requires careful thought in both its design and presentation to students.
For more detail on our design and results, read here.
Forge: A Tool to Teach Formal Methods
Tags: Education, Formal Methods, Properties, Tools, User Studies, Verification, Visualization
Posted on 21 April 2024.For the past decade we have been studying how best to get students into formal methods (FM). Our focus is not on the 10% or so of students who will automatically gravitate towards it, but on the “other 90%” who don’t view it as a fundamental part of their existence (or of the universe). In particular, we decided to infuse FM thinking into the students who go off to build systems. Hence the course, Logic for Systems.
The bulk of the course focuses on solver-based formal methods. In particular, we began by using Alloy. Alloy comes with numerous benefits: it feels like a programming language, it can “Run” code like an IDE, it can be used for both verification and state-exploration, it comes with a nice visualizer, and it allows lightweight exploration with gradual refinement.
Unfortunately, over the years we have also run into various issues with Alloy, a full catalog of which is in the paper. In response, we have built a new FM tool called Forge. Forge is distinguished by the following three features:
-
Rather than plunging students into the full complexity of Alloy’s language, we instead layer it into a series of language levels.
-
We use the Sterling visualizer by default, which you can think of as a better version of Alloy’s visualizer. But there’s much more! Sterling allows you to craft custom visualizations. We use this to create domain-specific visualizations. As we show in the paper, the default visualization can produce unhelpful, confusing, or even outright misleading images. Custom visualization takes care of these.
-
In the past, we have explored property-based testing as a way to get students on the road from programming to FM. In turn, we are asking the question, “What does testing look like in this FM setting?” Forge provides preliminary answers, with more to come.
Just to whet your appetite, here is an example of what a default Sterling output looks like (Alloy’s visualizer would produce something similar, with fewer distinct colors, making it arguably even harder to see):
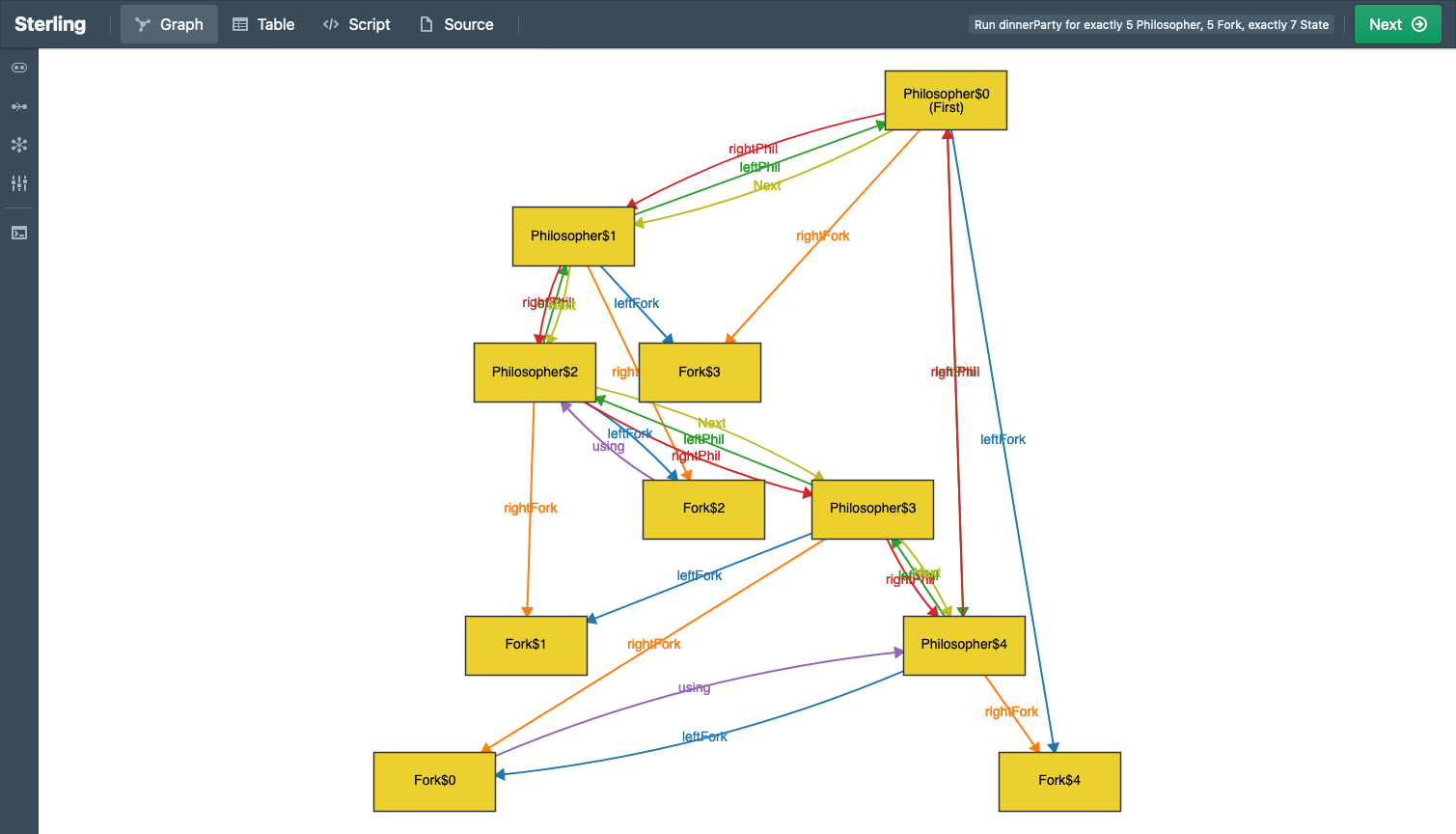
Here’s what custom visualization shows:
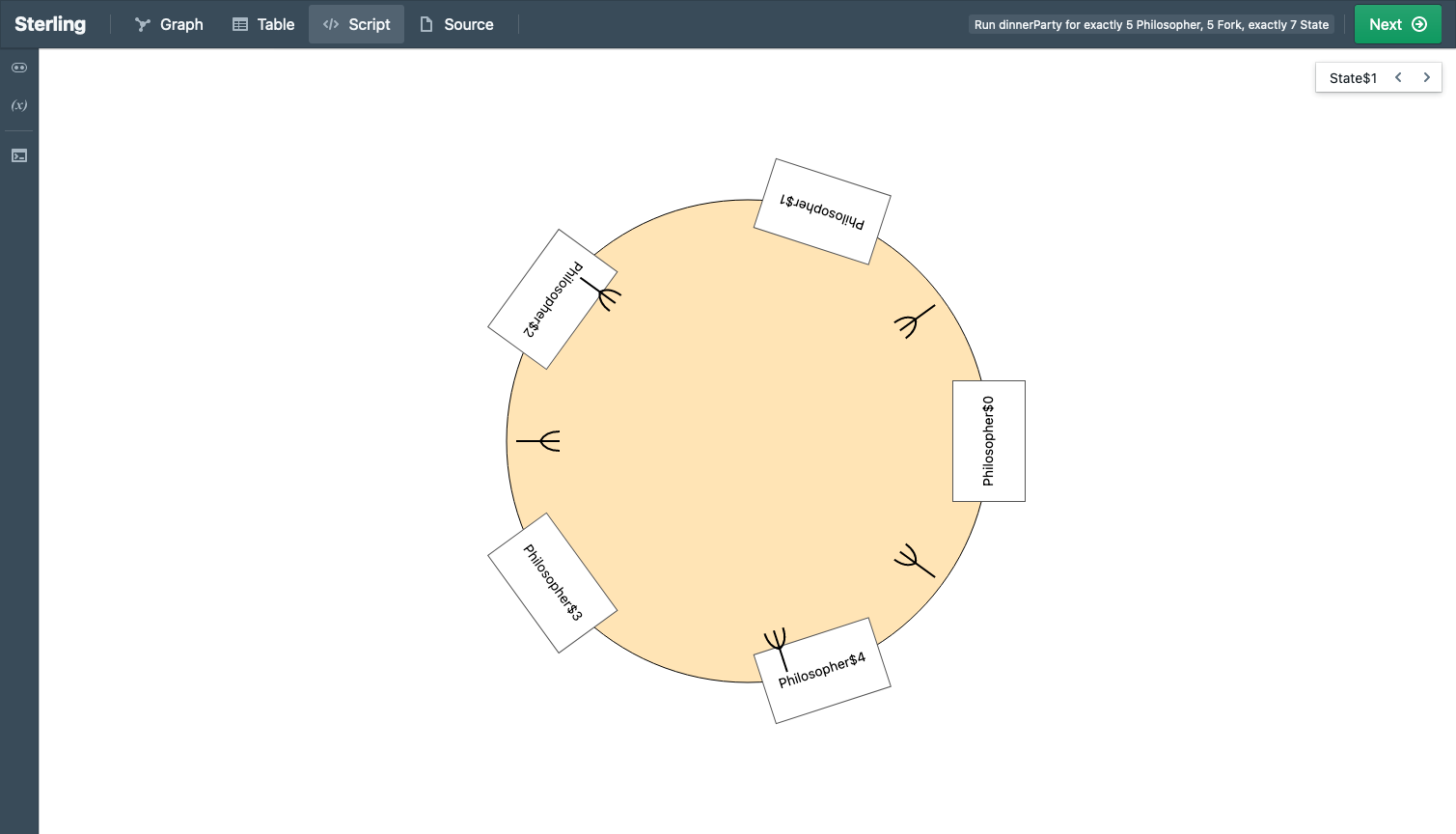
See the difference?
For more details, see the paper. And please try out Forge!
Acknowledgements
We are grateful for support from the U.S. National Science Foundation (award #2208731).
Finding and Fixing Standard Misconceptions About Program Behavior
Tags: Education, Misconceptions, Semantics, Tools, User Studies
Posted on 12 April 2024.A large number of modern languages — from Java and C# to Python and JavaScript to Racket and OCaml — share a common semantic core:
- variables are lexically scoped
- scope can be nested
- evaluation is eager
- evaluation is sequential (per “thread”)
- variables are mutable, but first-order
- structures (e.g., vectors/arrays and objects) are mutable, and first-class
- functions can be higher-order, and close over lexical bindings
- memory is managed automatically (e.g., garbage collection)
We call this the Standard Model of Languages (SMoL).
SMoL potentially has huge pedagogic benefit:
-
If students master SMoL, they have a good handle on the core of several of these languages.
-
Students may find it easier to port their knowledge between languages: instead of being lost in a sea of different syntax, they can find familiar signposts in the common semantic features. This may also make it easier to learn new languages.
-
The differences between the languages are thrown into sharper contrast.
-
Students can see that, by going beyond syntax, there are several big semantic ideas that underlie all these languages, many of which we consider “best practices” in programming language design.
We have therefore spent the past four years working on the pedagogy of SMoL:
-
Finding errors in the understanding of SMoL program behavior.
-
Finding the (mis)conceptions behind these errors.
-
Collating these into clean instruments that are easy to deploy.
-
Building a tutor to help students correct these misconceptions.
-
Validating all of the above.
We are now ready to present a checkpoint of this effort. We have distilled the essence of this work into a tool:
It identifies and tries to fix student misconceptions. The Tutor assumes users have a baseline of programming knowledge typically found after 1–2 courses: variables, assignments, structured values (like vectors/arrays), functions, and higher-order functions (lambdas). Unlike most tutors, instead of teaching these concepts, it investigates how well the user actually understands them. Wherever the user makes a mistake, the tutor uses an educational device called a refutation text to help them understand where they went wrong and to correct their conception. The Tutor lets the user switch between multiple syntaxes, both so they can work with whichever they find most comfortable (so that syntactic unfamiliarity or discomfort does not itself become a source of errors), and so they can see the semantic unity beneath these languages.
Along the way, to better classify student responses, we invent a concept called the misinterpreter. A misinterpreter is an intentionally incorrect interpreter. Concretely, for each misconception, we create a corresponding misinterpreter: one that has the same semantics as SMoL except on that one feature, where it implements the misconception instead of the correct concept. By making misconceptions executable, we can mechanically check whether student responses correspond to a misconception.
There are many interesting lessons here:
-
Many of the problematic programs are likely to be startlingly simple to experts.
-
The combination of state, aliasing, and functions is complicated for students. (Yet most introductory courses plunge students into this maelstrom of topics without a second thought or care.)
-
Misinterpreters are an interesting concept in their own right, and are likely to have value independent of the above use.
In addition, we have not directly studied the following claims but believe they are well warranted based on observations from this work and from experience teaching and discussing programming languages:
-
In SMoL languages, local and top-level bindings behave the same as the binding induced by a function call. However, students often do not realize that these have a uniform semantics. In part this may be caused by our focus on the “call by” terminology, which focuses on calls (and makes them seem special). We believe it would be an improvement to replace these with “bind by”.
-
We also believe that the terms “call-by-value” and “call-by-reference” are so hopelessly muddled at this point (between students, instructors, blogs, the Web…) that finding better terminology overall would be helpful.
-
The way we informally talk about programming concepts (like “pass a variable”), and the syntactic choices our languages make (like
return x), are almost certainly also sources of confusion. The former can naturally lead students to believe variables are being aliased, and the latter can lead them to believe the variable, rather than its value, is being returned.
For more details about the work, see the paper. The paper is based on an old version of the Tutor, where all programs were presented in parenthetical syntax. The Tutor now supports multiple syntaxes, so you don’t have to worry about being constrained by that. Indeed, it’s being used right now in a course that uses Scala 3.
Most of all, the SMoL Tutor is free to use! We welcome and encourage instructors of programming courses to consider using it — you may be surprised by the mistakes your students make on these seemingly very simple programs. But we also welcome learners of all stripes to give it a try!
Privacy-Respecting Type Error Telemetry at Scale
Tags: Privacy, Types, User Studies
Posted on 02 February 2024.Thesis: Programming languages would benefit hugely from telemetry. It would be extremely useful to know what people write, how they edit, what problems they encounter, etc. Problem: Observing programmers is very problematic. For students, it may cause anxiety and thereby hurt their learning (and grades). For professionals too it may cause anxiety, but it can also leak trade secrets.
One very partial solution is to perform these observations in controlled settings, such as a lab study. The downside is that it is hard to get diverse populations of users, it’s hard to retain them for very long, it’s hard to pay for these studies, etc. Furthermore, the activities they perform in a lab study may be very different from what they would do in real use: i.e., lab studies especially lack ecological validity when compared against many real-world programming settings.
We decided to instead study a large number of programmers doing their normal work—but in a privacy-respecting way. We collaborated with the Roblox Studio team on this project. Roblox is a widely-used platform for programming and deploying games, and it has lots of users of all kinds of ages and qualifications. They range from people writing their first programs to developers working for game studios building professional games.
In particular, we wanted to study a specific phenomenon: the uptake of types in Luau. Luau is an extension of Lua that powers Roblox. It supports classic Lua programs, but also lets programmers gradually add types to detect bugs at compile time. We specifically wanted to see what kind of type errors people make when using Luau, with the goal of improving their experience and thereby hopefully increasing uptake of the language.
Privacy-respecting telemetry sounds wonderful in theory but is very thorny in practice. We want our telemetry to have several properties:
-
It must not transmit any private information. This may be more subtle than it sounds. Error messages can, for instance, contain the names of functions. But these names may contain a trade secret.
-
It must be fast on the client-side so that the programmer experience is not disrupted.
-
It must transmit only small amount of data, so as not to overload the database servers.
(The latter two are not specific to privacy, but are necessary when working at scale.)
Our earlier, pioneering work on error message analysis was able to obtain a large amount of insight from logs. As a result of the above constraints, we cannot even pose many of the same questions in our setting.
Nevertheless, we were able to still learn several useful things about Luau. For more details, see the paper. But to us, this project is at least as interesting for the questions it inspires as for the particular solution or the insights gained from it. We hope to see many more languages incorporate privacy-respecting telemetry. (We’re pleased to see the Go team also thinking about these issues, as summarized in Russ Cox’s transparent telemetry notes. While there are some differences between our approaches, our overarching goals and constraints are very much in harmony.)
Profiling Programming Language Learning
Tags: Education, Rust, User Studies
Posted on 01 February 2024.Programmers profile programs. They use profiling when they suspect a program is not being as effective (performant) as they would like. Profiling helps them track down what is working well and what needs more work, and how best to use their time to make the program more effective.
Programming language creators want their languages to be adopted. To that end, they create documentation, such as a book or similar written document. These are written with the best of intentions and following the best practices they know of. But are they effective? Are they engaging? How do they know? These are questions very much in the Socio-PLT mould proposed by Meyerovich and Rabkin.
In addition, their goal in writing such documentation is that people learn about their language. But many people do not enjoy a passive reading experience or, even if they do, they won’t learn much from it.
These two issues mesh together well. Books should be more interactive. Books should periodically stop readers and encourage them to think about what they’re reading:
If a listener nods his head when you’re explaining your program, wake him up.
—Alan Perlis
Books should give readers feedback on how well they have been reading so far. And authors should use this information to drive the content of the book.
We have been doing this in our Rust Book experiment. There, the focus was on a single topic: ownership. But in fact we have been doing this across the whole book, and in doing so we have learned a great deal.
-
We analyzed the trajectory of readers and showed that many drop out when faced with difficult language concepts like Rust’s ownership types. This suggests either revising how those concepts are presented, moving them later in the book, or splitting them into two parts, a gentle introduction that retains readers and a more detailed, more technical chapter later in the book once readers are more thoroughly invested.
-
We used both classical test theory and item response theory to analyze the characteristics of quiz questions. We found that better questions are more conceptual in nature, such as asking why a program does not compile versus whether a program compiles.
-
We performed 12 interventions into the book to help readers with difficult questions. We evaluated how well an intervention worked by comparing the performance of readers pre- and post-intervention on the question being targeted.
In other words, the profiler analogy holds: it helps us understand the behavior of “the program” (namely, users going through the book), suggests ways to improve it, and helps us analyze specific attempts at improvement and shows that they are indeed helpful.
However, we did all this with a book for which, over 13 months, 62,526 readers answered questions 1,140,202 times. This is of no help to new languages who might struggle to get more than dozens of users! Therefore, we sampled to simulate how well we would have fared on much smaller subsets of users. We show that for some of our analyses even 100 users would suffice, while others require around a 1000. These numbers—especially 100—are very much attainable for young languages.
Languages are designed for adoption, but mere design is usually insufficient to enable it, as the Socio-PLT paper demonstrated. We hope work along these lines can help language designers get their interesting work into many more hands and minds.
For more details, see the paper. Most of all, you can do this with your materials, too! The library for adding these quizzes is available here.
Observations on the Design of Program Planning Notations for Students
Tags: Higher-Order Functions, Education, Program Planning, User Studies
Posted on 27 December 2023.In two recent projects we’ve tried to make progress on the long-dormant topic of teaching students how to plan programs. Concretely, we chose higher-order functions as our driving metaphor to address the problem of “What language shall we use to express plans?” We showed that this was a good medium for students. We also built some quite nice tool support atop Snap!. Finally, we were making progress on this long open issue!
Not so fast.
We tried to replicate our previous finding with a new population of students and somewhat (but not entirely) different problems. It didn’t work well at all. Students made extensive complaints about the tooling and, when given a choice, voted with their feet by not using it.
We then tried again, allowing them freedom in what notation they used, but suggesting two: one was diagrammatic (essentially representing dataflow), and the other was linear prose akin to a todo-list or recipe. Students largely chose the latter, and also did a better job with planning.
Overall, this is a sobering result. It diminishes some of our earlier success. At the same time, it sheds more light on the notations students prefer. In particular, it returns to our earlier problem: planning needs a vocabulary, and we are still far from establishing one that students find comfortable and can use successfully. But it also highlights deeper issues, such as the need to better support students with composition. Critically, composition serves as a bridge between more plan-oriented students and bricoleurs, making it especially worthy of more study, no matter your position on how students should or do design programs.
For more details, see the paper.
Conceptual Mutation Testing
Tags: Education, Misconceptions, Testing, Tools, User Studies
Posted on 31 October 2023.Here’s a summary of the full arc, including later work, of the Examplar project.
The Examplar system is designed to solve the documented phenomenon that students often misunderstand a programming problem statement and hence “solve” the wrong problem. It does so by asking students to begin by writing input/output examples of program behavior, and evaluating them against correct and buggy implementations of the solution. Students refine and demonstrate their understanding of the problem by writing examples that correctly classify these implementations.

It is, however, very difficult to come up with good buggy candidates. These programs must correspond to the problem misconceptions students are most likely to have. Students can, otherwise, end up spending too much time catching them, and not enough time on the actual programming task. Additionally, a small number of very effective buggy implementations is far more useful than either a large number or ineffective ones (much less both).
Our previous research has shown that student-authored examples that fail the correct implementation often correspond to student misconceptions. Buggy implementations based on these misconceptions circumvent many of the pitfalls of expert-generated equivalents (most notably the ‘expert blind spot’). That work, however, leaves unanswered the crucial question of how to operationalize class-sourced misconceptions. Even a modestly sized class can generate thousands of failing examples per assignment. It takes a huge amount of manual effort, expertise, and time to extract misconceptions from this sea of failing examples.
The key is to cluster these failing examples. The obvious clustering method – syntactic – fails miserably: small syntactic differences can result in large semantic differences, and vice versa (as the paper shows). Instead, we need a clustering technique that is based on the semantics of the problem.
This paper instead presents a conceptual clustering technique based on key characteristics of each programming assignment. These clusters dramatically shrink the space that must be examined by course staff, and naturally suggest techniques for choosing buggy implementation suites. We demonstrate that these curated buggy implementations better reflect student misunderstandings than those generated purely by course staff. Finally, the paper suggests further avenues for operationalizing student misconceptions, including the generation of targeted hints.
You can learn more about the work from the paper.
Generating Programs Trivially: Student Use of Large Language Models
Tags: Large Language Models, Education, Formal Methods, Properties, Testing, User Studies
Posted on 19 September 2023.The advent of large language models like GPT-3 has led to growing concern from educators about how these models can be used and abused by students in order to help with their homework. In computer science, much of this concern centers on how LLMs automatically generate programs in response to textual prompts. Some institutions have gone as far as instituting wholesale bans on the use of the tool. Despite all the alarm, however, little is known about whether and how students actually use these tools.
In order to better understand the issue, we gave students in an upper-level formal methods course access to GPT-3 via a Visual Studio Code extension, and explicitly granted them permission to use the tool for course work. In order to mitigate any equity issues around access, we allocated $2500 in OpenAI credit for the course, enabling free access to the latest and greatest OpenAI models.
Can you guess the total dollar value of OpenAI credit used by students?
We then analyzed the outcomes of this intervention, how and why students actually did and did not use the LLM.
Which of these graphs do you think best represents student use of GPT models over the semester?
When surveyed, students overwhelmingly expressed concerns about using GPT to help with their homework. Dominant themes included:
- Fear that using LLMs would detract from learning.
- Unfamiliarity with LLMs and issues with output correctness.
- Fear of breaking course rules, despite being granted explicit permission to use GPT.
Much ink has been spilt on the effect of LLMs in education. While our experiment focuses only on a single course offering, we believe it can help re-balance the public narrative about such tools. Student use of LLMs may be influenced by two opposing forces. On one hand, competition for jobs may cause students to feel they must have “perfect” transcripts, which can be aided by leaning on an LLM. On the other, students may realize that getting an attractive job is hard, and decide they need to learn more in order to pass interviews and perform well to retain their positions.
You can learn more about the work from the paper.
A Grounded Conceptual Model for Ownership Types in Rust
Tags: Crowdsourcing, Education, Rust, Types, User Studies, Visualization
Posted on 17 September 2023.Rust is establishing itself as the safe alternative to C and C++, making it an essential component for building a future software univers that is correct, reliable, and secure. Rust achieves this in part through the use of a sophisticated type system based on the concept of ownership. Unfortunately, ownership is unfamiliar to most conventionally-trained programmers. Surveys suggest that this central concept is also one of Rust’s most difficult, making it a chokepoint in software progress.
We have spent over a year understanding how ownership is currently taught, in what ways this proves insufficient for programmers, and looked for ways to improve their understanding. When confronted with a program containing an ownership violation, we found that Rust learners could generally predict the surface reason given by the compiler for rejecting the program. However, learners could often could not relate the surface reason to the underlying issues of memory safety and undefined behavior. This lack of understanding caused learners to struggle to idiomatically fix ownership errors.
To address this, we created a new conceptual model for Rust ownership, grounded in these studies. We then translated this model into two new visualizations: one to explain how the type-system works, the other to illustrate the impact on run-time behavior. Crucially, we configure the compiler to ignore borrow-checker errors. Through this, we are able to essentially run counterfactuals, and thereby illustrate the ensuing undefined behavior.
Here is an example of the type-system visualization:

And here is an example of the run-time visualization:
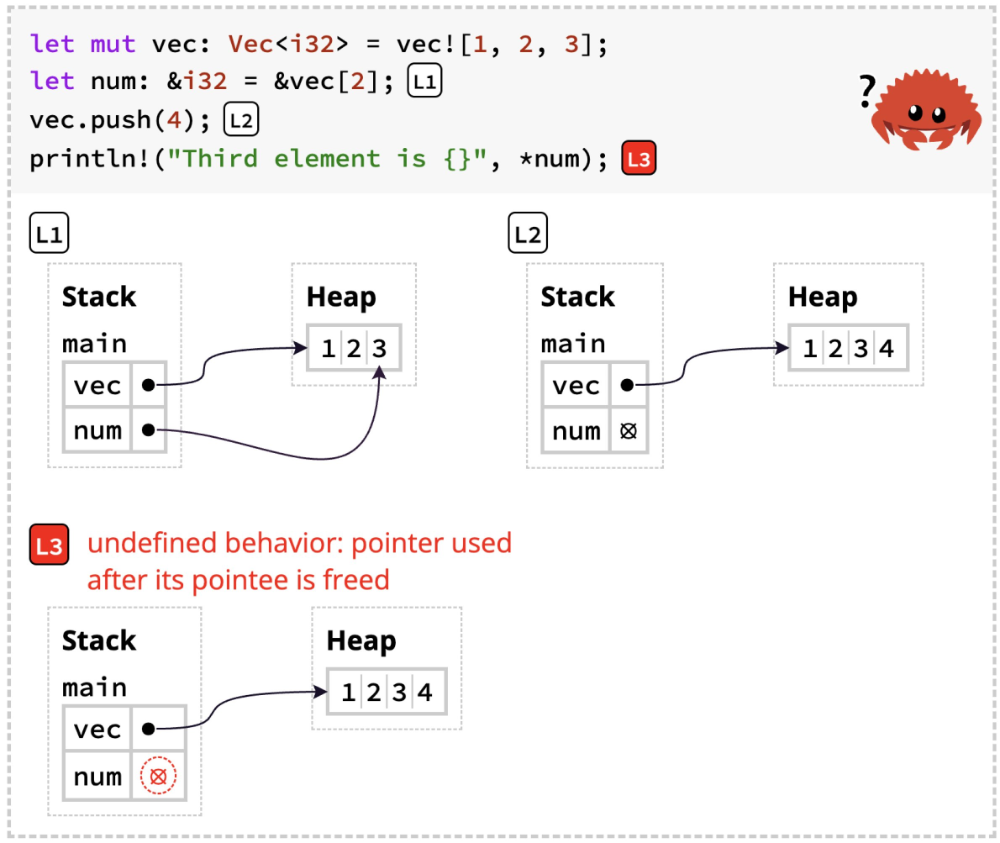
We incorporated these diagrams into an experimental version of The Rust Programming Language by Klabnik and Nichols. The authors graciously permitted us to create this fork and publicize it, and also provided a link to it from the official edition. As a result, we were able to test our tools on readers, and demonstrate that they do actually improve Rust learning.
The full details are in the paper. Our view is that the new tools are preliminary, and other researchers may come up with much better, more creative, and more effective versions of them. Rather, the main contribution is an understanding of how programmers do and don’t understand ownership, and in particular its relationship to undefined behavior. It is therefore possible that new pedagogies that make that connection clear may obviate the need for some of these tools entirely.
What Happens When Students Switch (Functional) Languages
Tags: Education, Pyret, Python, User Studies
Posted on 16 July 2023.What happens when students learn a second programming language after having gotten comfortable with one? This was a question of some interest in the 1980s and 1990s, but interest in it diminished. Recent work by Ethel Tshukudu and her collaborators have revived interest in this question.
Unfortunately, none of this work has really considered the role of functional programming. This is especially worth considering in the framework that Tshukudu’s work lays out, which is to separate syntax and semantics. That is the issue we tackle.
Specifically, we try to study two conditions:
-
different syntax, similar semantics
-
similar syntax, different semantics
For the same semantics, any two sufficiently syntactically different functional languages would do. The parenthetical syntax of the Lisp family gives us a syntax that is clearly different from the infix syntaxes of most other languages. In our particular case, we use Racket and Pyret.
The second case is trickier. For a controlled lab study, one could do this with very controlled artificial languages. However, we are interested in student experiences, which require curricula and materials that made-up languages usually cannot provide.
Instead, we find a compromise. The Pyret syntax was inspired by that of Python, though it does have some differences. It comes with all the curricular support we need. Therefore, we can compare it versus an imperative curriculum in Python.
You can read the details in the paper. The work is less interesting for its answers than for its setup. As a community we know very little about this topic. We hope the paper will inspire other educators both through the questions we have asked and the materials we have designed.
Little Tricky Logics
Tags: Linear Temporal Logic, Crowdsourcing, Misconceptions, User Studies, Verification
Posted on 05 November 2022.We also have followup work that continues to explore LTL and now also studies finite-trace LTL. In addition, we also have an automated tutor that puts this material to work to help students directly.
LTL (Linear Temporal Logic) has long been central in computer-aided verification and synthesis. Lately, it’s also been making significant inroads into areas like planning for robots. LTL is powerful, beautiful, and concise. What’s not to love?
However, any logic used in these settings must also satisfy the central goal of being understandable by its users. Especially in a field like synthesis, there is no second line of defense: a synthesizer does exactly what the specification says. If the specification is wrong, the output will be wrong in the same way.
Therefore, we need to understand how people comprehend these logics. Unfortunately, the human factors of logics has seen almost no attention in the research community. Indeed, if anything, the literature is rife with claims about what is “easy” or “intuitive” without any rigorous justification for such claims.
With this paper, we hope to change that conversation. We bring to bear on this problem several techniques from diverse areas—but primarily from education and other social sciences (with tooling provided by computer science)—to understand the misconceptions people have with logics. Misconceptions are not merely mistakes; they are validated understanding difficulties (i.e., having the wrong concept), and hence demand much greater attention. We are especially inspired by work in physics education on the creation of concept inventories, which are validated instruments for rapidly identifying misconceptions in a population, and take steps towards the creation of one.
Concretely, we focus on LTL (given its widespread use) and study the problem of LTL understanding from three different perspectives:
-
LTL to English: Given an LTL formula, can a reader accurately translate it into English? This is similar to what a person does when reading a specification, e.g., when code-reviewing work or studying a paper.
-
English to LTL: Given an English statement, can a reader accurately express it in LTL? This skill is essential for specification and verification.
Furthermore, “understanding LTL” needs to be divided into two parts: syntax and semantics. Therefore, we study a third issue:
- Trace satisfaction: Given an LTL formula and a trace (sequence of states), can a reader accurately label the trace as satisfying or violating? Such questions directly test knowledge of LTL semantics.
Our studies were conducted over multiple years, with multiple audiences, and using multiple methods, with both formative and confirmatory phases. The net result is that we find numerous misconceptions in the understanding of LTL in all three categories. Notably, our studies are based on small formulas and traces, so we expect the set of issues will only grow as the instruments contain larger artifacts.
Ultimately, in addition to
- finding concrete misconceptions,
we also:
-
create a codebook of misconceptions that LTL users have, and
-
provide instruments for finding these misconceptions.
We believe all three will be of immediate use to different communities, such as students, educators, tool-builders, and designers of new logic-based languages.
For more details, see the paper.
See also our LTL Tutor.
Performance Preconceptions
Tags: Education, Misconceptions, User Studies
Posted on 10 October 2022.What do computer science students entering post-secondary (collegiate) education think “performance” means?
Who or what shapes these views?
How accurate are these views?
And how correctable are their mistakes?
These questions are not merely an idle curiosity. How students perceive performance impacts how they think about program design (e.g., they may think a particular design is better but still not use it because they think it’s less performant). It also affects their receptiveness to new programming languages and styles (“paradigms”) of programming. Anecdotally, we have seen exactly these phenomena at play in our courses.
We are especially interested in students who have had prior computer science (in secondary school), such as students taking the AP Computer Science exam in the US. These students often have significant prior computing, but we have studied relatively little about the downstream consequences of these courses. Indeed, performance considerations are manifest in material as early as the age 4–8 curriculum from Code.org!
This paper takes a first step in examining these issues. We find that students have high confidence in incorrect answers on material they should have little confidence about. To address these problems, we try multiple known techniques from the psychology and education literature — the Illusion of Explanatory Depth, and Refutation Texts — that have been found to work in several other domains. We see that they have little impact here.
This work has numerous potential confounds based on the study design and location of performance. Therefore, we don’t view this as a definitive result, but rather as a spur to start an urgently-needed conversation about factors that affect post-secondary computer science education. Concretely, as we discuss in the discussion sections, we also believe there is very little we know about how students conceive of “performance”, and question whether our classical methods for approaching it are effective.
The paper is split into a short paper, that summarizes the results, an an extensive appendix, which provides all the details and justifies the summary. Both are available online.
Structural Versus Pipeline Composition of Higher-Order Functions
Tags: Higher-Order Functions, Education, User Studies
Posted on 16 August 2022.Building on our prior work on behavioral conceptions of higher-order functions (HOFs), we have been looking now at their composition. In designing a study, we kept running into tricky problems in designing HOF composition problems. Eventually, we set out to study that question directly.
We’re going to give you a quiz. Imagine you have a set of standard
HOFs (map, filter, sort, andmap, ormap, take-while). You
are given two ways to think about composing them (where “funarg” is
short for the parameter that is a function):
Type A: HOF_A(<some funarg>, HOF_B(<some funarg>, L))
Type B: HOF_C((lambda (inner) HOF_D(<some funarg>, inner)), L)
-
Which of these would you consider “easier” for students to understand and use?
-
How would you rate their relative expressive power in terms of problems they can solve?
Don’t go on until you’ve committed to answers to these questions.
Rather than A and B, here are better names: we’ll refer to A
as pipeline, because it corresponds to a traditional
data-processing/Unix pipeline composition (HOF_B L | HOF_A), and
we’ll refer to B as structural. If you’re like many other people
we’ve asked, you likely think that pipeline is easier, but you’re less
certain about how to answer the second question.
Alright, now you’re ready to read the paper! We think the structural/pipeline distinction is similar to the structural/generative recursion distinction in HtDP, and similarly has consequences for how we order HOF composition in our pedagogy. We discuss all this, and more, in the document.
Plan Composition Using Higher-Order Functions
Tags: Higher-Order Functions, Education, Program Planning, User Studies
Posted on 09 July 2022.There is a long history of wanting to examine planning in computing education research, but relatively little work on it. One problem you run into when trying to do this seriously is: “What language shall we use to express plans?” A lot hinges on this language.
-
The programming language itself is too low-level: there are too many administrative details that get in the way and might distract the student; failures may then reflect these distractions, not an inability to plan.
-
Plain English may be too high-level. It’s both difficult to give any useful (automated) feedback about, it may also require too much interpretation. In particular, an expert may interpret student utterances in ways the student didn’t mean, thereby giving the student an OK signal when in fact the student is not on the right path.
Separately, in prior work, we looked at whether students are able to understand higher-order functions (HOFs) from a behavioral perspective: i.e., as atomic units of behavior without reference to their underlying implementation. For our population, we found that they generally did quite well.
You may now see how these dovetail. Once students have a behavioral understanding of individual HOFs, you can use them as a starting vocabulary for planning. Or to think in more mechanical terms, we want to study how well students understand the composition of HOFs. That is the subject of this work.
Concretely, we start by confirming our previous result—that they understand the building blocks—and can also articulate many of the features that we previously handed out to them. This latter step is important because any failures at composition may lie in their insufficiently rich understanding of the functions. Fortunately, we see that this is again not a problem with our population.
We then focus on the main question: can they compose these HOFs. We do this in two ways:
-
We give them input-output examples and ask them to identify which compositions of functions would have produced those results. This is akin to having a dataset you need to transform and knowing what you would like the result to look like, and figuring out what steps will take it there.
-
We give them programming problems to solve, and ask them to first provide high-level plans of their solutions.
What we find is that students don’t do superbly on (1), but do extremely well on (2). Indeed, our goal had been to study what changes between the planning and programming phase (e.g., if they planned incorrectly but programmed correctly; or vice versa), but our students unfortunately did too well on both to give us any useful data!
Of particular interest is how we got them to state plans. While HOFs are the “semantics”, we still need a “syntax” for writing them. Conventional textual programming has various bad affordances. Instead, we created a custom palette of operations in Snap!. In keeping with the point of this paper, the operations were HOFs. There are numerous advantages to this use of Snap!:
-
Drag-and-drop construction avoids getting bogged down in the vagaries of textual syntax.
-
Changing plans is much easier, because you can drag whole blocks and (again) not get caught up in messy textual details. This means students are hopefully more willing to change around their plans.
-
The planning operations focus on the operations we care about, and students can ignore irrelevant details.
-
Most subtly: the blanks can be filled in with text. That is, you get “operations on the outside, text on the inside”: at the point where things get too detailed, students can focus on presenting their ideas rather than on low-level details. This is, in other words, a hybrid of the two methods we suggested at the beginning.
Critically, these aren’t programs! Because of the text, they can’t be executed. But that’s okay! They’re only meant to help students think through their plans before starting to write the program. In particular, given students’ reluctance to change their programs much once they start coding, it seems especially important to give them a fluid medium—where switching costs are low—in which to plan things before they start to write a line of code. So one of the best things about this paper, beyond the main result, is actually our discovery of Snap!’s likely utility in this setting.
For more details, see the paper!
Towards a Notional Machine for Runtime Stacks and Scope
Tags: Education, Misconceptions, Scope, Semantics, User Studies
Posted on 07 July 2022.Stacks are central to our understanding of program behavior; so is scope. These concepts become ever more important as ever more programming languages embrace concepts like closures and advanced control (like generators). Furthermore, stacks and scope interact in an interesting way, and these features really exercise their intersection.
Over the years we’ve seen students exhibit several problematic conceptions about stacks (and scope). For instance, consider a program like this:
def f(x):
return g(x + 1)
def g(y):
return y + x
f(3)
What is its value? You want an error: that x is not bound. But think
about your canonical stack diagram for this program. You have a frame
for g atop that for x, and you have been told that you “look down
the stack”. (Or vice versa, depending on how your stacks grow.) So
it’s very reasonable to conclude that this program produces 7, the
result produced by dynamic scope.
We see students thinking exactly this.
Consider this program:
def f(x):
return lambda y: x + y
p = f(3)
p(4)
This one, conversely, should produce 7. But students who have been
taught a conventional notion of call-and-return assume that f’s
stack frame has been removed after the call completed (correct!), so
p(4) must result in an error that x is not bound.
We see students thinking exactly this, too.
The paper sets out to do several things.
First, we try to understand the conceptions of stacks that students have coming into an upper-level programming languages course. (It’s not great, y’all.)
Second, we create some tooling to help students learn more about stacks. More on that below. The tooling seems to work well for students who get some practice using it.
Third, we find that even after several rounds of direct instruction and practice, some misconceptions remain. In particular, students do not properly understand how environments chain to get scope right.
Fourth, in a class that had various interventions including interpreters, students did much better than in a class where students learned from interpreters alone. Though we love interpreters and think they have various valuable uses in programming languages education, our results make us question some of the community’s beliefs about the benefits of using interpreters. In particular, some notions of transfer that we would have liked to see do not occur. We therefore believe that the use of interpreters needs much more investigation.
As for the tooling: One of the things we learned from our initial study is that students simply do not have a standardized way of presenting stacks. What goes in them, and how, were all over the map. We conjecture there are many reasons: students mostly see stacks and are rarely asked to draw them; and when they do, they have no standard tools for doing so. So they invent various ad hoc notations, which in turn don’t necessarily reinforce all the aspects that a stack should represent.
We therefore created a small tool for drawing stacks. What we did was repurpose Snap! to create a palette of stack, environment, and heap blocks. It’s important to understand these aren’t runnable programs: these are just static representations of program states. But Snap! is fine with that. This gave us a consistent notation that we could use everywhere: in class, in the textbook, and in homeworks. The ability to make stacks very quickly with drag-and-drop was clearly convenient to students who gained experience with the tool, because many used it voluntarily; it was also a huge benefit for in-class instruction over a more conventional drawing tool. An unexpected success for block syntaxes!
For more details, see the paper.
Gradual Soundness: Lessons from Static Python
Tags: Python, Types, User Studies
Posted on 28 June 2022.It is now virtually a truism that every dynamic language adopts a gradual static type system. However, the space of gradual typing is vast, with numerous tradeoffs between expressiveness, efficiency, interoperability, migration effort, and more.
This work focuses on the Static Python language built by the Instagram team at Meta. Static Python is an interesting language in this space for several reasons:
-
It is designed to be sound.
-
It is meant to run fast.
-
It is reasonably expressive.
The static type system is a combination of what the literature calls concrete and transient types. Concrete types provide full soundness and low performance overhead, but impose nonlocal constraints. Transient types are sound in a shallow sense and easier to use; they help to bridge the gap between untyped code and typed concrete code. The net result is a language that is in active use, with high performance, inside Meta.
Our work here is to both formalize and assess the language. We investigate the language’s soundness claims and report on its performance on both micro-benchmarks and in production systems. In particular, we find that the design holds up the intent of soundness well, but the act of modeling it uncovered several bugs (including one that produced a segmentation fault), all of which have now been fixed.
We believe Static Python is a particularly interesting language for the gradual typing community to study. It is not based on virtuoso theoretical advances; rather, it takes solid ideas (e.g., from Muehlboeck and Tate’s Nom language), combines them well, and pays attention to the various affordances needed by practicing programmers. It therefore offers useful advice to the designers of other gradually-typed languages, in particular those who confront large code-bases and would like incremental approaches to transition from dynamic safety to static soundness. You can read much more about this in the paper.
As an aside, this paper is a collaboration that was born entirely thanks to Twitter and most probably would never have occurred withtout it. An aggrieved-sounding post by Guido van Rossum led to an exchange between Carl Meyer at Meta and Shriram, which continued some time later here. Eventually they moved to Direct Messaging. Shriram pointed out that Ben Greenman could investigate this further, and from that, this collaboration was born.
Applying Cognitive Principles to Model-Finding Output
Tags: User Studies, Verification, Visualization
Posted on 26 April 2022.Model-finders produce output to help users understand the specifications they have written. They therefore effectively make assumptions about how these will be processed cognitively, but are usually unaware that they are doing so. What if we apply known principles from cognitive science to try to improve the output of model-finders?
Model Finding and Specification Exploration
Model-finding is everywhere. SAT and SMT solvers are the canonical model-finders: given a logical specification, they generate a satisfying instance (a “model”) or report that it’s impossible. Their speed and generality have embedded them in numerous back-ends. They are also used directly for analysis and verification, e.g., through systems like Alloy.
One powerful modality enabled by tools like Alloy is the exploration of specifications. Usually, model-finders are used for verification: you have a specification and some properties about it, and a verifier tells you whether the properties are satisfied or not. However, we often don’t have properties; we just want to understand the consequences of a design. While a conventional verifier is useless in this setting, model-finders have no problem with it: they will generate models of the specification that show different possible ways in which it can be realized.
Presenting Exploration
The models generated by exploration (or even by verification, where they are typically counterexamples) can be presented in several ways. For many users, the most convenient output is visual. Here, for instance, is a typical image generated using the Sterling visualizer:
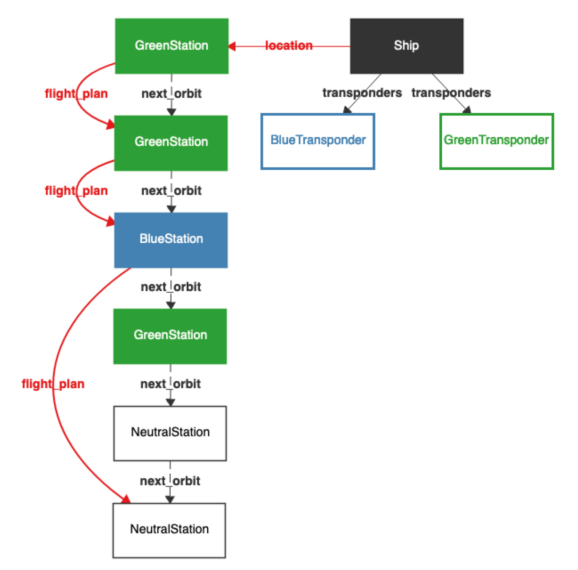
As of this writing, Alloy will let you sequentially view one model at a time.
Exploration for Understanding
The purpose of showing these models is to gain understanding. It is therefore reasonable to ask what forms of presentation would be most useful to enable the most understanding. In earlier work we studied details of how each model is shown. That work is orthogonal to what we do here.
Here, we are interested in how many models, and of what kind, should be displayed. We draw on a rich body of literature in perceptual psychology going back to seminal work by Gibson and Gibson in 1955. A long line of work since then has explored several dimensions of this, resulting in a modern understanding of contrasting cases. In this work, you don’t show a single result; rather, you show a set of similar examples, to better help people build models of what they are seeing. Since our goal is to help people understand a specification through visual output, it was natural to ask whether any of this literature could help in our setting.
Our Study
We concretely studied numerous experimental conditions involving different kinds of contrasting cases, where we show multiple models on screen at once. Critically, we looked at the use of both positive and negative models. Positive models are what you expect: models of the specification. In contrast, “negative” models are ones that don’t model the specification.
There can, of course, be an infinite number of negative models, most of which are of no use whatsoever: if I write a specification of a leader-election protocol, a whale or a sandwich are legitimate negative models. What we are interested in is “near miss” models, i.e., ones that could almost have been models but for a small difference. Our theory was that showing these models would help a user better understand the “space” of their model. (In this, we were inspired by prior work by Montaghmi and Rayside.)
Our Findings
We study these questions through both crowdsourced and talkaloud studies, and using both quantitative and qualitative methods. We find that in this setting, the use of multiple models does not seem to have been a big win. (Had it been, we would still have to confront the problem of how to fit all that information onto a screen in the general case.) The use of negative instances does seem to be helpful. We also constructed novel modes of output such as where a user can flip between positive and negative instances, and these seem especially promising.
Of course, our findings come with numerous caveats. Rather than think of our results as in any way definitive, we view this as formative work for a much longer line of research at the intersection of formal methods and human-computer interaction. We especially believe there is enormous potential to apply cognitive science principles in this space, and our paper provides some very rough, preliminary ideas of how one might do so.
For More Details
You can read about all this in our paper. Be warned, the paper is a bit of heavy going! There are a lot of conditions and lots of experiments and data. But hopefully you can get the gist of it without too much trouble.
Student Help-Seeking for (Un)Specified Behaviors
Tags: Education, Misconceptions, Testing, Tools, User Studies
Posted on 02 October 2021.Here’s a summary of the full arc, including later work, of the Examplar project.
Over the years we have done a lot of work on Examplar, our system for helping students understand the problem before they start implementing it. Given that students will even use it voluntarily (perhaps even too much), it would seem to be a success story.
However, a full and fair scientific account of Examplar should also examine where it fails. To that end, we conducted an extensive investigation of all the posts students made on our course help forum for a whole semester, identified which posts had to do with problem specification (and under-specification!), and categorized how helpful or unhelpful Examplar was.
The good news is we saw several cases where Examplar had been directly helpful to students. These should indeed be considered a lower-bound, because the point of Examplar is to “answer” many questions directly, so they would never even make it onto the help forum.
But there is also bad news. To wit:
-
Students sometimes simply fail to use Examplar’s feedback; is this a shortcoming of the UI, of the training, or something inherent to how students interact with such systems?
-
Students tend to overly focus on inputs, which are only a part of the suite of examples.
-
Students do not transfer lessons from earlier assignments to later ones.
-
Students have various preconceptions about problem statements, such as imagining functionality not asked for or constraints not imposed.
-
Students enlarge the specification beyond what was written.
-
Students sometimes just don’t understand Examplar.
These serve to spur future research in this field, and may also point to the limits of automated assistance.
To learn more about this work, and in particular to get the points above fleshed out, see our paper!
Developing Behavioral Concepts of Higher-Order Functions
Tags: Higher-Order Functions, Education, User Studies
Posted on 31 July 2021.Higher-Order Functions (HOFs) are an integral part of the programming process. They are so ubiquitous, even Java had to bow and accept them. They’re especially central to cleanly expressing the stages of processing data, as the R community and others have discovered.
How do we teach higher-order functions? In some places, like
How to Design Programs,
HOFs are presented as abstractions over common patterns. That is,
you see a certain pattern of program behavior over and over, and
eventually learn to parameterize it and call it map, filter, and
so on. That is a powerful method.
In this work, we take a different perspective. Our students often write examples first, so they can think in terms of the behavior they want to achieve. Thus, they need to develop an understanding of HOFs as abstractions over common behaviors: “mapping”, “filtering”, etc.
Our goal in this work is to study how well students form behavioral abstractions having been taught code pattern abstractions. Our main instrument is sets of input-output behavior, such as
(list "red" "green" "blue")
-->
(list 3 5 4)
(Hopefully that calls to mind “mapping”.) We very carefully designed a set of these to capture various specific similarities, overlaps, and impossibilities.
We then evaluated students using two main devices, inspired by activities in machine learning:
-
Clustering: Group behaviors into clusters of similar ones.
-
Classification: For each behavior, assign a label.
We also tried labeling over visual presentations.
Our paper describes these instruments in detail, and our outcomes. What is most interesting, perhaps, is not our specific outcomes, but this style of thinking about teaching HOFs. We think the materials—especially the input-output pairs, and a table of properties—will be useful to educators who are tackling this topic. More broadly, we think there’s a huge unexplored space of HOF pedagogy combined with meaningful evaluation. We hope this work inspires more work along these lines.
Adversarial Thinking Early in Post-Secondary Education
Tags: Education, User Studies
Posted on 18 July 2021.Adversarial Thinking (AT) is often described as “thinking like a hacker” or as a “security mindset”. These quasi-definitions are not only problematic in their own right (in some cases, they can be outright circular), they are also too narrow. We believe that AT applies in many other settings as well: in finding ways where machine learning can go wrong, for identifying problems with user interfaces, and for that matter even in software testing and verification.
All these are, however, quite sophisticated computer science concepts. Does that mean AT can only be covered in advanced computer science courses—security, machine learning, formal methods, and the like? Put differently, how much technical sophistication do students need before they can start to engage in it?
We believe AT can be covered starting from a fairly early stage. In this work, we’ve studied its use with (accelerated) introductory post-secondary (university) students. We find that they do very well, but also exhibit some weaknesses. We also find that they are able to reckon with the consequences of systems well beyond their technical capability. Finally, we find that they focus heavily on social issues, not just on technical ones.
In addition to these findings, we have also assembled a rich set of materials covering several aspects of computer science. Students generally found these engaging and thought-provoking, and responded to them with enthusiasm. We think educators would benefit greatly from this collection of materials.
Want to Learn More?
If you’re interested in this, and in the outcomes, please see our paper.
Teaching and Assessing Property-Based Testing
Tags: Education, Formal Methods, Properties, Testing, User Studies
Posted on 10 January 2021.Property-Based Testing (PBT) sees increasing use in industry, but lags significantly behind in education. Many academics have never even heard of it. This isn’t surprising; computing education still hasn’t come to terms with even basic software testing, even when it can address pedagogic problems. So this lag is predictable.
The Problem of Examples
But even people who want to use it often struggle to find good examples of it. Reversing a list drives people to drink, and math examples are hard to relate to. This is a problem from several respects. Without compelling examples, nobody will want to teach it. Even if they do, unless the examples are compelling, students will not pay attention to it. And if the students don’t, they won’t recognize opportunities to use it later in their careers.
This loses much more than a testing technique. We consider PBT a gateway to formal specification. Like a formal spec, it’s an abstract statement about behaviors. Unlike a formal spec, it doesn’t require learning a new language or mathematical formalism, it’s executable, and it produces concrete counter-examples. We therefore use it, in Brown’s Logic for Systems course, as the starting point to more formal specifications. (If they learn nothing about formal specification but simply become better testers, we’d still consider that a win.)
Therefore, for the past 10 years, and with growing emphasis, we’ve been teaching PBT: starting in our accelerated introductory course, then in Logic for Systems, and gradually in other courses as well. But how do we motivate the concept?
Relational Problems
We motivate PBT through what we call relational problems. What are those?
Think about your typical unit test. You write an input-output
pair: f(x) is y. Let’s say it fails:
-
Usually, the function
fis wrong. Congrats, you’ve just caught a bug! -
Sometimes, the test is wrong:
f(x)is not, in fact,y. This can take some reflection, and possibly reveals a misunderstanding of the problem.
That’s usually where the unit-testing story ends. However, there is one more possibility:
- Neither is “wrong”.
f(x)has multiple legal results,w,y, andz; your test chosey, but this particular implementation happened to returnzorwinstead.
We call these “relational” because f is clearly more a relation than
a function.
Some Examples
So far, so abstract. But many problems in computing actually have a relational flavor:
-
Consider computing shortest paths in a graph or network; there can be many shortest paths, not just one. If we write a test to check for one particular path, we could easily run into the problem above.
-
Many other graph algorithms are also relational. There are many legal answers, and the implementation happens to pick just one of them.
-
Non-deterministic data structures inspire relational behavior.
-
Various kinds of matching problems—e.g., the stable-marriage problem—are relational.
-
Combinatorial optimization problems are relational.
-
Even sorting, when done over non-atomic data, is relational.
In short, computing is full of relational problems. While they are not at all the only context in which PBT makes sense, they certainly provide a rich collection of problems that students already study that can be used to expose this idea in a non-trivial setting.
Assessing Student Performance
Okay, so we’ve been having students write PBT for several years now. But how well do they do? How do we go about measuring such a question? (Course grades are far too coarse, and even assignment grades may include various criteria—like code style—that are not strictly germane to this question.) Naturally, their core product is a binary classifier—it labels a purported implementation as valid or invalid—so we could compute precision and recall. However, these measures still fail to offer any semantic insight into how students did and what they missed.
We therefore created a new framework for assessing this. To wit, we took each problem’s abstract property statement (viewed as a formal specification), and sub-divided it into a set of sub-properties whose conjunction is the original property. Each sub-property was then turned into a test suite, which accepted those validators that enforced the property and rejected those that did not. This let us get a more fine-grained understanding of how students did, and what kinds of mistakes they made.
Want to Learn More?
If you’re interested in this, and in the outcomes, please see our paper.
What’s Next?
The results in this paper are interesting but preliminary. Our follow-up work describes limitations to the approach presented here, thereby improving the quality of evaluation, and also innovates in the generation of classifying tests. Check it out!
Students Testing Without Coercion
Tags: Education, Testing, Tools, User Studies
Posted on 20 October 2020.Here’s a summary of the full arc, including later work, of the Examplar project.
It is practically a trope of computing education that students are over-eager to implement, yet woefully under-eager to confirm they understand the problem they are tasked with, or that their implementation matches their expectations. We’ve heard this stereotype couched in various degrees of cynicism, ranging from “students can’t test” to “students won’t test”. We aren’t convinced, and have, for several years now, experimented with nudging students towards early example writing and thorough testing.
We’ve blogged previously about our prototype IDE, Examplar — our experiment in encouraging students to write illustrative examples for their homework assignments before they actually dig into their implementation. Examplar started life as a separate, complementary tool from Pyret’s usual programming environment, providing a buffer just for the purposes of developing a test suite. Clicking Run in Examplar runs the student’s test suite against our implementations (not theirs) and then reports the degree to which the suite was valid and thorough (i.e., good at catching our buggy implementations). With this tool, students could catch their misconceptions before implementing them.
Although usage of this tool was voluntary for all but the first assignment, students relied on it extensively throughout the semester and the quality of final submissions improved drastically compared to prior offerings of the course. Our positive with this prototype encouraged us to fully-integrate Examplar’s feedback into students’ development environment. Examplar’s successor provides a unified environment for the development of both tests and implementation:

This new environment — which provides Examplar-like feedback on every Run — no longer requires that students have the self-awareness to periodically switch to a separate tool. The environment also requires students to first click a “Begin Implementation” button before showing the tab in which they write their implementation.
This unified environment enabled us to study, for the first time, whether students wrote examples early, relative to their implementation progress. We tracked the maximum test thoroughness students had achieved prior to each edit-and-run of their implementations file. Since the IDE notified students of their test thoroughness upon each run, and since students could only increase their thoroughness via edits to their tests file, the mean of these scores summarizes how thoroughly a student explored the problem with tests before fully implementing it.
We find that nearly every student on nearly every assignment achieves some level of thoroughness before their implementation work:

To read more about our design of this environment, its pedagogic context, and our evaluation of students’ development process, check out the full paper here.
Using Design Alternatives to Learn About Data Organizations
Tags: Education, User Studies
Posted on 27 June 2020.A large number of computer science education papers focus on data structures. By this, they mean the canon: lists, queues, stacks, heaps, and so on. These are certainly vital to the design of most programs.
However, there is another kind of “data structure” programmers routinely contend with: how to represent the world your program is about. Suppose, for instance, you’re trying to represent a family’s genealogy. You could:
-
Represent each person as a node and have references to their two biological parents, who in turn have references to their biological parents, and so on. The tree “bottoms out” when we get to people about whom we have no more information.
-
Represent each person as a node and have references to their children instead (a list, say, if we want to preserve their birth order). This tree bottoms out at people who have no children.
-
Represent each coupling as a node, and have references to their children (or issue, as genealogists like to say). Now you may have a kind of node for children and another for coupling.
And so on. There are numerous possibilities. Which one should we pick? It depends on (1) what information we even have, (2) what operations we want to perform, and (3) what complexity we need different operations to take.
Unfortunately, computing education research doesn’t talk about this problem very much at all; in fact, we don’t seem to even have terminology to talk about this issue. In a sense, this is also very much a matter of data structure, though of a different kind: whereas the purely abstract data structures of computer science we might call computational data structures, these — which center around directly representing real-world information — we might instead call representational data structures. That could get pretty confusing, though, so we’ve adopted the term data organization to refer to the latter.
Learning to think about data organization is an essential computing skill. But how early can we teach it? How well can students wrestle with it? What methods should we use? Do they need to be sophisticated programmers before they can engage in reasoning about representations?
Good news: we can begin this quite early, and students don’t need to be sophisticated computer scientists: they can just think about the world, and their experiences living in it, to reason about data organizations. Representational data structures probably do a far better job of drawing on their lived experience than computational ones do! (Unless they’ve previously lived as a computer.)
There are several ways we could introduce this topic. We chose to expose them to pairs of representations for the same domain, and have them compare the two. This is related to theories of perception. Read the paper to learn more!
Somewhat subtly, this also adds a dimension to “computational thinking” that is usually quite missing from standard discussions about it. Activities like those described in this paper generate new and engaging activities that many students can participate in. Indeed, computing background does not seem to matter much in our data, and a more diverse group of students is likely to make a much richer set of judgments—thereby enabling students in traditionally underrepresented groups to contribute based on their unique experiences, and also feel more valued.
What Help Do Students Seek in TA Office Hours?
Tags: Education, User Studies
Posted on 20 May 2020.In computer science, a large number of students get help from teaching assistants (TAs). A great deal of their real education happens in these hours. While TA hours are an excellent resource, they are also rather opaque to the instructors, who do not really know what happens in them.
How do we construct a mechanism to study what happens in hours? It’s actually not obvious at all:
-
We could set up cameras to record all the interactions in hours. While this would provide a lot of information, it significantly changes the nature of hours. For many students, hours are private time with a TA, where they can freely speak about their discomfort and get help from a peer; they might ask personal questions; they might also complain about the instructor. One does not install cameras in confessionals.
-
We could ask TAs to write extensive notes (redacting private information) after the student has left. This also has various flaws:
-
Their memory may be faulty.
-
Their recollection may be biased by their own beliefs.
-
It would slow down processing students, who already confront overly-long lines and waits.
-
What do we instead want? A process that is non-intrusive, lightweight, and yet informative. We have to also give up on perfect knowledge, and focus on information that is actually useful to the instructor.
Part of the problem is that we as a community lack a systematic method to help students in the first place. If students have no structure to how they approach help-seeking, then it’s hard to find patterns and make sense of what they actually do.
However, this is exactly a problem that the How to Design Programs Design Recipe was addressed to solve. It provides a systematic way for students to structure their problem-solving and help-seeking. TAs are instructed to focus on the steps of the Design Recipe in order, not addressing later steps until students have successfully completed the earlier ones. This provides an “early warning” diagnostic, addressing root causes rather than their (far-removed) manifestations.
Therefore, we decided to use the Design Recipe steps as a lens for obtaining insight into TA hours. We argue that this provides a preliminary tool that addresses our needs: it is lightweight, non-intrusive, and yet useful to the instructor. Read the paper to learn more!
Can We Crowdsource Language Design?
Tags: Crowdsourcing, Programming Languages, Semantics, User Studies
Posted on 06 July 2017.Programming languages are user interfaces. There are several ways of making decisions when designing user interfaces, including:
- a small number of designers make all the decisions, or
- user studies and feedback are used to make decisions.
Most programming languages have been designed by a Benevolent Dictator for Life or a committee, which corresponds to the first model. What happens if we try out the second?
We decided to explore this question. To get a large enough number of answers (and to engage in rapid experimentation), we decided to conduct surveys on Amazon Mechanical Turk, a forum known to have many technically literate people. We studied a wide range of common programming languages features, from numbers to scope to objects to overloading behavior.
We applied two concrete measures to the survey results:
- Consistency: whether individuals answer similar questions the same way, and
- Consensus: whether we find similar answers across individuals.
Observe that a high value of either one has clear implications for language design, and if both are high, that suggests we have zeroed in on a “most natural” language.
As Betteridge’s Law suggests, we found neither. Indeed,
-
A surprising percentage of workers expected some kind of dynamic scope (83.9%).
-
Some workers thought that record access would distribute over the field name expression.
-
Some workers ignored type annotations on functions.
-
Over the field and method questions we asked on objects, no worker expected Java’s semantics across all three.
These and other findings are explored in detail in our paper.
Crowdsourcing User Studies for Formal Methods
Tags: Crowdsourcing, User Studies, Verification
Posted on 03 July 2017.For decades, we have neglected performing serious user studies of formal-methods tools. This is now starting to change. An earlier post introduces our new work in this area.
That study works with students in an upper-level class, who are a fairly good proxy for some developers (and are anyway an audience we have good access to). Unfortunately, student populations are problematic for several reasons:
-
There are only so many students in a class. There may not be enough to obtain statistical strength, especially on designs that require A/B testing and the like.
-
The class is offered only so often. It may take a whole year between studies. (This is a common problem in computing education research.)
-
As students progress through a class, it’s hard to “rewind” them and study their responses at an earlier stage in their learning.
And so on. It would be helpful if we could obtain large numbers of users quickly, relatively cheaply, and repeatedly.
This naturally suggests crowdsourcing. Unfortunately, the tasks we are examining involve using tools based on formal logic, not identifying birds or picking Web site colors (or solving CAPTCHAs…). That would seem to greatly limit the utility of crowd-workers on popular sites like Mechanical Turk.
In reality, this depends on how the problem is phrased. If we view it as “Can we find lots of Turkers with knowledge of Promela (or Alloy or …)?”, the answer is pretty negative. If, however, we can rework the problems somewhat so the question is “Can we get people to work on a puzzle?”, we can find many, many more workers. That is, sometimes the problem is one of vocabulary (and in particular, the use of specific formal methods languages) than of raw ability.
Concretely, we have taken the following steps:
-
Adapt problems from being questions about Alloy specifications to being phrased as logic “puzzles”.
-
Provide an initial training phase to make sure workers understand what we’re after.
-
Follow that with an evaluation phase to ensure that they “got the idea”. Only consider responses from those workers who score at a high enough threshold on evaluation.
-
Only then conduct the actual study.
Observe that even if we don’t want to trust the final results obtained from crowdsourcing, there are still uses for this process. Designing a good study requires several rounds of prototyping: even simple wording choices can have huge and unforeseen (negative) consequences. The more rounds we get to test a study, the better it will come out. Therefore, the crowd is useful at least to prototype and refine a study before unleashing it on a more qualified, harder-to-find audience — a group that, almost by definition, you do not want to waste on a first-round study prototype.
For more information, see our paper. We find fairly useful results using workers on Mechanical Turk. In many cases the findings there correspond with those we found with class students.
User Studies of Principled Model Finder Output
Tags: Crowdsourcing, Formal Methods, User Studies, Verification, Visualization
Posted on 01 July 2017.For decades, formal-methods tools have largely been evaluated on their correctness, completeness, and mathematical foundations while side-stepping or hand-waving questions of usability. As a result, tools like model checkers, model finders, and proof assistants can require years of expertise to negotiate, leaving knowledgeable but uninitiated potential users at a loss. This state of affairs must change!
One class of formal tool, model finders, provides concrete instances of a specification, which can guide a user’s intuition or witness the failure of desired properties. But are the examples produced actually helpful? Which examples ought to be shown first? How should they be presented, and what supplementary information can aid comprehension? Indeed, could they even hinder understanding?
We’ve set out to answer these questions via disciplined user-studies. Where can we find participants for these studies? Ideally, we would survey experts. Unfortunately, it has been challenging to do so in the quantities needed for statistical power. As an alternative, we have begun to use formal methods students in Brown’s upper-level Logic for Systems class. The course begins with Alloy, a popular model-finding tool, so students are well suited to participate in basic studies. With this population, we have found some surprising results that call into question some intuitively appealing answers to (e.g.) the example-selection question.
For more information, see our paper.
Okay, that’s student populations. But there are only so many students in a class, and they take the class only so often, and it’s hard to “rewind” them to an earlier point in a course. Are there audiences we can use that don’t have these problems? Stay tuned for our next post.
The PerMission Store
Tags: Android, Permissions, Privacy, Security, Tools, User Studies
Posted on 21 February 2017.This is Part 2 of our series on helping users manage app permissions. Click here to read Part 1.
As discussed in Part 1 of this series, one type of privacy decision users have to make is which app to install. Typically, when choosing an app, users pick from the first few apps that come up when they search a keyword in their app store, so the app store plays a big roll in which apps users download.
Unfortunately, most major app stores don’t help users make this decision in a privacy-minded way. Because these stores don’t factor privacy into their ranking, the top few search results probably aren’t the most privacy-friendly, so users are already picking from a problematic pool. Furthermore, users rely on information in the app store to choose from within that limited pool, and most app stores offer very little in the way of privacy information.
We’ve built a marketplace, the PerMission Store, that tackles both the ranking and user information concerns by adding one key component: permission-specific ratings. These are user ratings, much like the star ratings in the Google Play store, but they are specifically about an app’s permissions.1
To help users find more privacy friendly apps, the privacy ratings are incorporated into the PerMission Store’s ranking mechanism, so that apps with better privacy scores are more likely to appear in the top hits for a given search. (We also consider factors like the star rating in our ranking, so users are still getting useful apps.) So users are selecting from a more privacy-friendly pool of apps right off the bat.
Apps’ privacy ratings are also displayed in an easy-to-understand way, alongside other basic information like star rating and developer. This makes it straightforward for users to consider privacy along with other key factors when deciding which app to install.
Incorporating privacy into the store itself makes it so that choosing privacy-friendly apps is as a natural as choosing useful apps.
The PerMission Store is currently available as an Android app and can be found on Google Play.
A more detailed discussion of the PerMission Store can be found in Section 3.1 of our paper.
This is Part 2 of our series on helping users manage app permissions. Click here to read Part 1.
1: As a bootstrapping mechanism, we’ve collected rating for a couple thousand apps from Mechanical Turk. Ultimately, though, we expect the ratings to come from in-the-wild users.
Examining the Privacy Decisions Facing Users
Tags: Android, Permissions, Privacy, Security, User Studies
Posted on 25 January 2017.This is Part 1 of our series on helping users manage app permissions. Click here to read Part 2.
It probably comes as no surprise to you that users are taking their privacy in their hands every time they install or use apps on their smartphones (or tablets, or watches, or cars, or…). This begs the question, what kinds of privacy decisions are users actually making? And how can we help them with those decisions?
At first blush, users can manage privacy in two ways: by choosing which apps to install, and by managing their apps’ permissions once they’ve installed them. For the first type of decision, users could benefit from a privacy-conscious app store to help them find more privacy-respecting apps. For the second type of decision, users would be better served by an assistant that helps them decide which permissions to grant.
Users can only making installation decisions when they actually have a meaningful choice between different apps. If you’re looking for Facebook, there really aren’t any other apps that you could use instead. This left us wondering if users ever have a meaningful choice between different apps, or whether they are generally looking for a specific app.
To explore this question, we surveyed Mechanical turk workers about 66 different Android apps, asking whether they thought the app could be replaced by a different one. The apps covered a broad range of functionality, from weather apps, to games, to financial services.
It turns out that apps vary greatly in their “replaceability,” and, rather than falling cleanly into “replaceable” and “unique” groups, they run along a spectrum between the two. At one end of the spectrum you have apps like Instagram, which less than 20% of workers felt could be replaced. On the other end of the spectrum are apps like Waze, which 100% of workers felt was replaceable. In the middle are apps whose replaceability depends on which features you’re interested in. For example, take an app like Strava, which lets you track your physical activity and compete with friends. If you only want to track yourself, it could be replaced by something like MapMyRide, but if you’re competing with friends who all use Strava, you’re pretty much stuck with Strava.
Regardless of exactly which apps fall where on the spectrum, though, there are replaceable apps, so users are making real decisions about which apps to install. And, for irreplaceable apps, they are also having to decide how to manage those apps’ permissions. These two types of decisions require two approaches to assisting users. A privacy-aware marketplace would aid users with installation decisions by helping them find more privacy-respecting apps, while a privacy assistant could help users manage their apps’ permissions.
Click here to read about our privacy-aware marketplace, the PerMission Store, and stay tuned for our upcoming post on a privacy assistant!
A more detailed discussion of this study can be found in Section 2 of our paper.
CS Student Work/Sleep Habits Revealed As Possibly Dangerously Normal
Tags: Education, User Studies
Posted on 14 June 2014. Written by Jesse Polhemus, and originally posted at the Brown CS blogImagine a first-year computer science concentrator (let’s call him Luis) e-mailing friends and family back home after a few weeks with Brown Computer Science (BrownCS). Everything he expected to be challenging is even tougher than anticipated: generative recursion, writing specifications instead of implementations, learning how to test his code instead of just writing it. Worst of all is the workload. On any given night, he’s averaging –this seems too cruel to be possible– no more than eight or nine hours of sleep.
Wait, what? Everyone knows that CS students don't get any sleep, so eight or nine hours is out of the question. Or is it? Recent findings from PhD student Joseph Gibbs Politz, adjunct professor Kathi Fisler, and professor Shriram Krishnamurthi analyze when students completed tasks in two different BrownCS classes, shedding interesting light on an age-old question: when do our students work, and when (if ever) do they sleep? The question calls to mind a popular conception of the computer scientist that Luis has likely seen in countless movies and books:
- Hours are late. (A recent poster to boardgames@lists.cs.brown.edu requests a 2 PM start time in order to avoid being “ridiculously early” for prospective players.)
- Sleep is minimal. BrownCS alumnus Andy Hertzfeld, writing about the early days of Apple Computer in Revolution in the Valley, describes the “gigantic bag of chocolate-covered espresso beans” and “medicinal quantities of caffeinated beverages” that allowed days of uninterrupted coding.
Part 1: Deadline Experiments
The story begins a few years before Luis’s arrival, when Shriram would routinely schedule his assignments to be due at the 11:00 AM start of class. “Students looked exhausted,” he remembers. “They were clearly staying up all night in order to complete the assignment just prior to class.”
Initially, he moved the deadline to 2:00 AM, figuring that night owl students would finish work in the early hours of the morning and then get some sleep. This was effective, but someone pointed out that it was unfair to other professors who taught earlier classes and were forced to deal with tired students who had finished Shriram’s assignment but not slept sufficiently.
“My final step,” he explains, “was to change deadlines to midnight. I also began penalizing late assignments on a 24-hour basis instead of an hourly one. This encourages students to get a full night’s sleep even if they miss a deadline.”
This was the situation when Luis arrives. The next task was to start measuring the results.
Part 2: Tracking Events
Shriram, Kathi, and Joe analyzed two of Shriram’s classes, CS 019 and CS 1730. For each class, Luis must submit test suites at any time he chooses, then read reviews of his work from fellow students. He then continues working on the solution, eventually producing a final implementation that must be submitted prior to the midnight deadline.
Part 3: Reality And Mythology
Given these parameters, what work and sleep patterns would you expect? We asked professor Tom Doeppner to reflect on Luis and share his experience of working closely with students as Director of Undergraduate Studies and Director of the Master’s Program. “Do students work late? I know I get e-mail from students at all hours of the night,” he says, “and I found out quickly that morning classes are unpopular, which is why I teach in the afternoon. Maybe it’s associated with age? I liked to work late when I was young, but I got out of the habit in my thirties.”
Asked about the possible mythologizing of late nights and sleeplessness, Tom tells a story from his own teaching: “Before we broke up CS 169 into two classes, the students had t-shirts made: ‘CS 169: Because There Are Only 168 Hours In A Week’. I think there’s definitely a widespread belief that you’re not really working hard unless you’re pulling multiple all-nighters.”
This doesn’t exactly sound like Luis’s sleep habits! Take a look at the graphs below to see how mythology and reality compare.
Part 4: Results And Conclusions
The graphs below depict test suite submissions, with time displayed in six-hour segments. For example, between 6 PM and the midnight deadline (“6-M”), 50 CS 173 students are submitting tests.
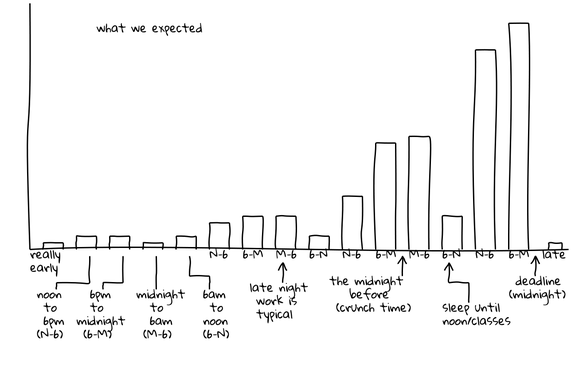
This graph is hypothetical, showing Joe, Kathi, and Shriram’s expectations for submission activity. They expected activity to be slow and increase steadily, culminating in frantic late-night activity just before the deadline. Generally taller “M-6” (midnight to 6 AM) bars indicate late-night work and a corresponding flurry of submissions, followed by generally shorter “6-N” (6 AM to noon) bars when students tried to get a few winks in. Cumulatively, these two trends depict the popular conception of the computer science student who favors late hours and perpetually lacks sleep.
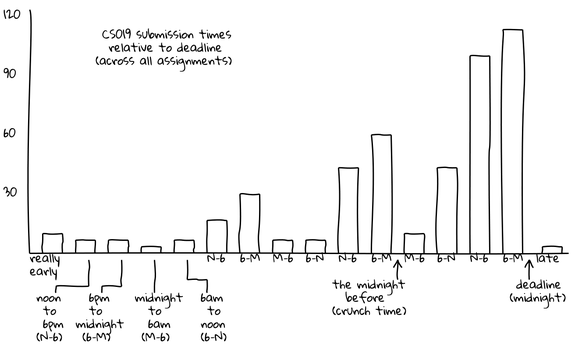
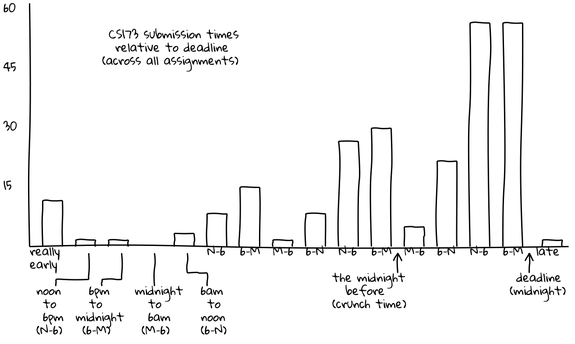
These graphs show actual submissions. As expected, activity generally increases over time and the last day contains the majority of submissions. However, unexpectedly, the “N-6” (noon to 6 PM) and “6-M” (6 PM to midnight) segments are universally the most active. In the case of the CS 173 graph, this morning segment contains far more submissions than any other of the day’s three segments. In both of these graphs, the “M-6” (midnight to 6 AM) segments are universally the least active, even the day the assignment is due. For example, the final segment of this type, which represents the last available span of early morning hours, is among the lowest of all segments, with only ten submissions occurring. In contrast, the corresponding “6-N” (6 AM to noon) shows more than four times as many submissions, suggesting that most students do their work before or after the pre-dawn hours but not during them.
“I wouldn’t have expected that,” Joe comments. “I think of the stories folks tell of when they work not lining up with that, in terms of staying up late and getting up just in time for class. Our students have something important to do at midnight other than work: they cut off their work before midnight and do something else. For the majority it’s probably sleep, but it could just be social time or other coursework. Either way, it’s an interesting across-the-board behavior.”
If word of these results gets out, what can Luis and his fellow students expect? “People will realize,” Shriram says, “that despite what everyone likes to claim, students even in challenging courses really are getting sleep, so it’s okay for them to, too.” Joe agrees: “There isn’t so much work in CS that you have to sacrifice normal sleeping hours for it.”
Luis, his family, and his well-rested classmates will undoubtedly be glad to hear it. The only question is: will their own descriptions of their work/sleep habits change to match reality, or are tales of hyper-caffeinated heroics too tempting to resist?
Appendix
The graphs above are simplified for readability, and aggregated into 6-hour increments. Below we include graphs of the raw data in 3-hour increments. This shows that there is some work going on from 12am-3am the night before assignments are due, but essentially nothing from 3am-6am.
In both of these classes, we were also performing experiments on code review, so the raw data includes when students read the code reviews they received, in addition to when they submitted their work. Since the review necessarily happens after submission, and the reading of the review after that, we see many more “late” events for reading reviews.
CS019 in 3-hour increments:
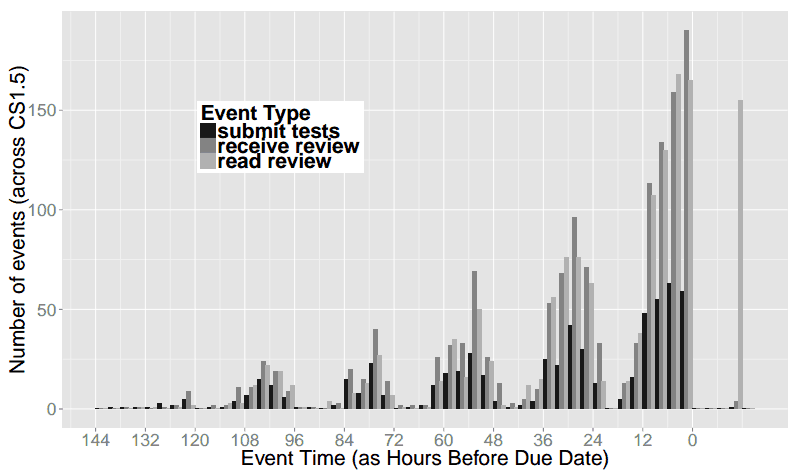
CS173 in 3-hour increments:
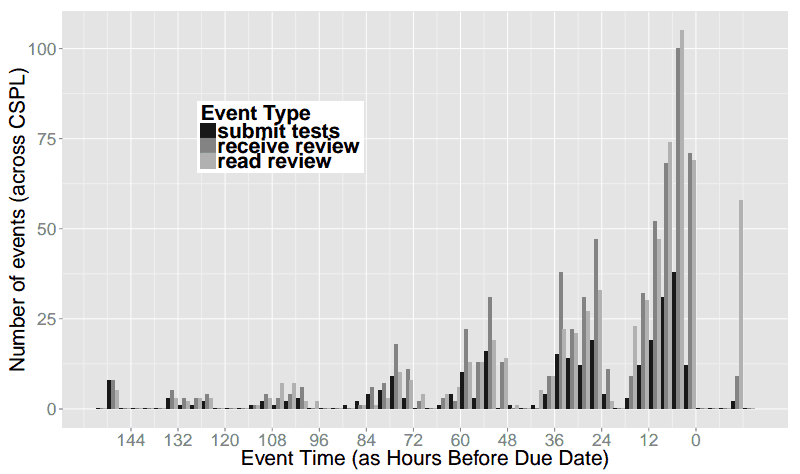
Social Ratings of Application Permissions (Part 4: The Goal)
Tags: Android, Permissions, Security, User Studies
Posted on 31 May 2013.(This is the fourth post in our series on Android application permissions. Click through for Part 1, Part 2, and Part 3.)
In this, the final post in our application permissions series, we'll discuss our trajectory for this research. Ultimately, we want to enable users to make informed decisions about the apps they install on their smartphones. Unfortunately, informed consent becomes difficult when you are asking users to make decisions in an area in which they have little expertise. Rating systems allow users to rely on the collective expertise of other users.
We intend to integrate permission ratings in to the app store in much the same way that functionality ratings are already there. This allows users to use visual cues they are already familiar with, such as the star rating that appears on the app page.

We may also wish to convey to users how each individual permission is rated. This finer-grained information gives users the ability to make decisions in line with their own priorities. For example, if users are particularly concerned about the integrity of their email accounts, an app that has a low-rated email access permission may be unacceptable to a user, even if the app receives otherwise high scores for permissions. We can again leverage well-known visual cues to convey this information, perhaps with meters similar to password meters, as seen in the mock-up image below.
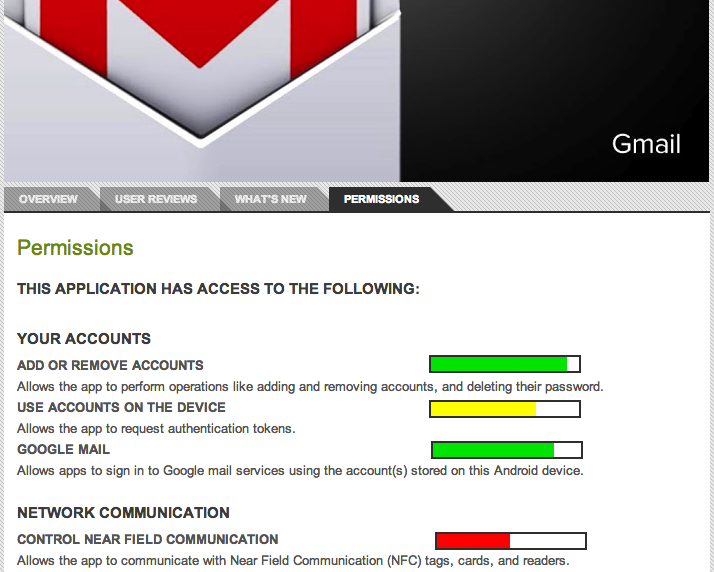
There are a variety of other features we may want to incorporate into a permission rating system: allowing users to select favorite or trusted raters could enable them to rely on a particularly savvy relative or friend. Additionally, users could build a privacy profile, and view ratings only from like-minded users. Side-by-side comparisons of different apps' permissions rating could let users choose between similar apps more easily.
Giving users an easy way to investigate app permissions will allow them to make privacy a part of their decision-making process without requiring extra work or research on their part. This will improve the overall security of using a smartphone (or other permission-rich device), leaving users less vulnerable to unintended sharing of their personal data.
There's more! Click through to read Part 1, Part 2, and Part 3of the series!Social Ratings of Application Permissions (Part 3: Permissions Within a Domain)
Tags: Android, Permissions, Security, User Studies
Posted on 29 May 2013.(This is the third post in our series on Android application permissions. Click through for Part 1, Part 2, and Part 4.)
In a prior post we discussed the potential value for a social rating system for smartphone apps. Such a system would give non-expert users some information about apps before installing them. Ultimately, the goal of such a system would be to help users choose between different apps with similar functionality (for an app they need) or decide if the payoff of an app is worth the potential risk of installing it (for apps they want). Both of these use cases would require conscientious ratings of permissions.
We chose to study this issue by considering the range of scores that respondents give to permissions. If respondents were not considering the permissions carefully, we would expect the score to be uniform across different permissions. We examined the top five weather forecasting apps in the Android marketplace: The Weather Channel, WeatherBug Elite, Acer Life Weather, WeatherPro, and AccuWeather Platinum. We chose weather apps because they demonstrate a range of permission requirements; Acer Life Weather requires only four permissions while AccuWeather Platinum and WeatherBug Elite each require eleven permissions. We asked respondents to rate an app's individual permissions as either acceptable or unacceptable.
Our findings, which we present in detail below, show that users will rate application permissions conscientiously. In short, we found that although the approval ratings for each permission are all over 50%, they vary significantly from permission to permission. Approval ratings for individual permissions ranged from 58.8% positive (for “Modify or delete the contents of your USB storage”) to 82.5% (for “Find accounts on the device”). The table at the bottom of this post shows the percentage of users who considered a given permission acceptable. Because the ratings range from acceptable to unacceptable, they are likely representative of a given permissions' risk (unlike uniformly positive or negative reviews). This makes them effective tools for users in determining which applications they wish to install on their phones.
Meaningful ratings tell us that it is possible to build a rating system for application permissions to accompany the existing system for functionality. In our next post, we'll discuss what such a system might look like!
| Modify or delete the contents of your USB storage | 58.8 % |
| Send sticky broadcast | 60 % |
| Control vibration | 67.5 % |
| View Wi-Fi connections | 70 % |
| Read phone status and identity | 70 % |
| Test access to protected storage | 72.5 % |
| Google Play license check | 73.8 % |
| Run at startup | 75.8 % |
| Read Google service configuration | 76.3 % |
| Full network access | 76.5 % |
| Approximate location | 79 % |
| View network connections | 80.5 % |
| Find accounts on the device | 82.5 % |
Social Ratings of Application Permissions (Part 2: The Effect of Branding)
Tags: Android, Permissions, Security, User Studies
Posted on 22 May 2013.(This is the second post in this series. Click through for Part 1 and Part 3, and Part 4.)
In a prior post, we introduced our experiments investigating user ratings of smartphone application permissions. In this post we'll discuss the effect that branding has on users' evaluation of an app's permissions. Specifically, what effect does a brand name have on users' perceptions and ratings of an app?
We investigated this question using four well-known apps: Facebook, Gmail, Pandora Radio, and Angry Birds. Subjects were presented with a description of the app and its required permissions. We created surveys displaying the information presented to users in the Android app store, and asked users to rate the acceptability of the apps required permissions, and indicate whether they would install the app on their phone. Some of the subjects were presented with the true description of the app including its actual name, and the rest were presented with the same description, but with the well-known name replaced by a generic substitute. For example, Gmail was disguised as Mangogo Mail.
In the cases of Pandora and Angry Birds, there were no statistically significant differences in subjects' responses between the two conditions. However, there were significant differences in the responses for Gmail and Facebook.
For Gmail, participants rated the generic version's permissions as less acceptable and were less likely to install that version. For Facebook, however, participants rated the permissions for the generic version as less acceptable, but it had no effect on whether subjects would install the app. These findings raise interesting questions. Are the differences in responses caused by privacy considerations or other concerns, such as ability to access existing accounts? Why are people more willing to install a less secure social network than an insecure email client?
It is possible that people would be unwilling to install a generic email application because they want to be certain they could access their existing email or social network accounts. To separate access concerns from privacy concerns, we did a follow-up study in which we asked subjects to evaluate an app that was an interface over a brand-name app. In Gmail's case, for instance, subjects were presented with Gmore!, an app purporting to offer a smoother interaction with one's Gmail account.
Our findings for the interface apps was similar to the generic apps: for Facebook, subjects rated the permissions as less acceptable, but there was no effect on the likelihood of their installing the app; for Gmail, subjects rated the permissions as less acceptable and were less likely to install the app. In fact, the app that interfaced with Gmail had the lowest installation rate of any of the apps: just 47% of respondents would install the app, as opposed to 83% for brand-name Gmail, and 71% for generic Mangogo Mail. This suggests that subjects were concerned about the privacy of the apps, not just their functionality.
It is interesting that the app meant to interface with Facebook showed no significant difference in installation rates. Perhaps users are less concerned about the information on a social network than the information in their email, and see the potential consequences of installing an insecure social network as less dire than those associated with installing an insecure email client. This is just speculation, and this question requires further examination.
Overall, it seems that branding may play a role in how users perceive a given app's permissions, depending on the app. We would like to examine the nuances of this effect in greater detail. Why does this effect occur in some apps but not others? When does the different perception of permissions affect installation rates and why? These questions are exciting avenues for future research!
There's more! Click through to read Part 1, Part 3, and Part 4 of the series!Social Ratings of Application Permissions (Part 1: Some Basic Conditions)
Tags: Android, Permissions, Security, User Studies
Posted on 18 May 2013.(This is the first post in our series on Android application permissions. Click through for Part 2, Part 3, and Part 4.)
Smartphones obtain their power from allowing users to install arbitrary apps to customize the device’s behavior. However, with this versatility comes risk to security and privacy.
Different manufacturers have chosen to handle this problem in different ways. Android requires all applications to display their permissions to the user before being installed on the phone (then, once the user installs it, the application is free to use its permissions as it chooses). The Android approach allows users to make an informed decision about the applications they choose to install (and to do so at installation time, not in the midst of a critical task), but making this decision can be overwhelming, especially for non-expert users who may not even know what a given permission means. Many applications present a large number of permissions to users, and its not always clear why an application requires certain permissions. This requires users to gamble on how dangerous they expect a given application to be.
One way to help users is to rely on the expertise or experiences of other users, an approach that is already common in online marketplaces. Indeed, the Android application marketplace already allows users to rate applications. However, these reviews are meant to rate the application as a whole, and are not specific to the permissions required by the application. Therefore the overall star rating of an application is largely indicative of users’ opinions of the functionality of an application, not the security of the application. When users do offer opinions about security and privacy, as they sometimes do, these views are buried in text and lost unless the user reads all the comments.
Our goal is to make security and privacy ratings first-class members of the marketplace rating system. We have begun working on this problem, and will explain our preliminary results in this and a few more blog posts. All the experiments below were conducted on Mechanical Turk.
In this post, we examine the following questions:
- Will people even rate the app's permissions? Even when there are lots of permissions to rate?
- Does users’ willingness to install a given application change depending on when they are asked to make this choice - before they’ve reflected on the individual permissions or after?
- Do their ratings differ depending on how they were told about the app?
We created surveys that mirrored the data provided by the Android installer (and as visible on the Google Play Web site). We examined four applications: Facebook, Gmail, Pandora, and Angry Birds. We asked respondents to rate the acceptability of the permissions required by each application and state whether they would install the application if they needed an app with that functionality.
In the first condition, respondents were asked whether they would install the app before
or after they were asked to rate the app’s individual permissions. In this case, only Angry
Birds showed any distinction between the two conditions: Respondents were more likely to install
the application if the were asked after they were asked to rate the permissions.
Overall, however, the effect of asking before or after was very small; this is good, because it
suggests that in the future we can ignore the overall rating, and it also offers some flexibility for
interface design.
The second condition was how the subject heard about the app (or rather, how they were asked to
imagine they heard about it). Subjects were asked to imagine either that the app had been recommended
to them by a colleague, that the app was a top “featured app” in the app store, or that the
app was a top rated app in the app store. In this case, only Facebook showed any interesting results:
respondents were less likely to install the application if it had been recommended by a colleague than
if it was featured or highly rated. This result is particularly odd given that, due to the network effect
of an app like Facebook, we would expect the app to be more valuable if friends or colleagues also use it.
We would like to study this phenomenon further.
Again, though this finding may be interesting, the fact that it has so little impact means we can set this
condition aside in our future studies, thus narrowing the search space of factors that do affect how users
rate permissions.
That concludes this first post on this topic. In future posts we’ll examine the effect of branding, and present detailed ratings of apps in one particular domain. Stay tuned!
There's more! Click through to read Part 2, Part 3, and Part 4 of the series!