The Brown PLT Blog

Articles by tag: Large Language Models
LLMs ⭢ Regular Expressions, Responsibly!
Iterative Student Program Planning using Transformer-Driven Feedback
Generating Programs Trivially: Student Use of Large Language Models
Human Judgment as a Specification
Tags: Large Language Models, Semantics, Tools, Linear Temporal Logic
Posted on 09 June 2026.The rise of GenAI in programming clearly requires an accompanying rise in formal methods, to confirm that AI systems running wild are producing the solutions we actually want. That in turn requires that we specify what we want. This specification is necessarily mathematical, to take advantage of the formal methods tools. But most programmers know far less about formal specification than they do about programming. What can they do?
Getting Specifications the Bad Way
The key problem we’re tackling is: how do we go from the informal (usually prose) to the formal. A natural solution is: use LLMs to translate prose into the formal specifications. On the one hand, this is not absurd: LLMs can do a fairly good job at generating terms in many contemporary formal notations. Here’s Ron Minsky, tongue-in-cheek:
I wonder if a more plausible model is, you go to your large language model and say, ‘Please write me a specification for a function that sorts a list.’ And then it, like, spits something out. And then you look at it and think, yeah, that seems about right.
Richard Eisenberg’s response to this gets to the heart of the matter: How can we be sure that the generated specification is the right one? The human may have just plain been wrong. They may have been obviously wrong, or they could have been wrong in subtle ways. They may have been been ambiguous, and the LLM may have taken the wrong interpretation. There may also be common misconceptions about the language (which may then also be embedded in the language models). Or they may have been referring to things for which there is no clear ground truth, or the only truth is in their head: what they mean depends on their context. None of these problems is fixable by an LLM alone.
Humans in the Loop
We therefore think it’s important for humans to be in the loop while formalizing specifications. A true vibe-coder, by definition, isn’t going to care. Instead, we want to target the responsible programmer: they care about their work quality, but they are also human, i.e., busy, lazy, and so on. What can we do to help them?
We believe any solution should have two key characteristics:
-
It must be meaningful. Asking humans to pass judgment on complex and abstract statements is unlikely to be effective. Laziness, automation bias, inability to form good judgments, and a desire to get things done will all lead to meaningless confirmation.
-
It must be moderate. Asking lots of questions, no matter how simple, can be exhausting and will also lead to errors as the number of questions grows. We should try to make every human action be highly impactful and not ask users to perform too many actions.
Observe that it’s easy to have one and not the other. Telling people “you must read all the code generated by an LLM” is definitely meaningful—but it is not at all moderate (so most people won’t do it). Classical security alerts, which ask just one yes/no question, are moderate effort, but not meaningful (because the alternative is to not get the job done). The challenge is to push along both dimensions just far enough to get real value but not so far as to lose people.
Our Solution
A few months ago, we posted about PICK, a tool we built to help us make better use of LLMs to generate regular expressions. You give the LLM a prompt and get back not one regex but rather several plausible ones. Your usual options are to take what the model gives you, or to read the regexes yourself and try to figure out which is right. PICK does something else: it shows you concrete strings chosen to distinguish the candidates from one another, and asks you to upvote or downvote each. The regex that survives your votes wins. It’s worth reading that post to get a sense of the workflow.
That post doesn’t mention two important things.
First, that we now have experimental results that show that this workflow works very well.
Second, that this isn’ tied to regular expressions alone. We have built PICK for three illustrative domains so far, intentionally chosen to be unlike one another: regular expressions, linear temporal logic (LTL), and attribute-based access control (ABAC). In all three the algorithm is the same: generate candidates, sample from set differences, present a pair of scenarios, update scores, converge or admit defeat. The workflow does not have to be redesigned per domain. (Readers of our older post on differential analysis will see the family resemblance. PICK is the in-the-loop version, where the semantic differences between still-viable candidates drive the next question.)
What lets the same algorithm work across all three domains is that they share two key properties:
- Closure under negation and intersection — so the difference between two candidates is itself expressible.
- Sampling from that difference — so the system can show the user concrete cases where the candidates disagree.
The machinery here is not exotic. It is the stuff of a sophomore theory-of-computation course: closure properties, set differences, and witness generation. Many of the formalisms programmers use every day already have it — either inherently (Boolean logic, network routing rules, package-version constraints) or by the standard trick of bounding the universe of discourse (almost anything at which you would point a SAT/SMT solver). The properties everyone is told in class are important and then never quite sees applied are, in 2026, what stand between you and a confidently wrong access-control policy. And motivated by, of all things, cognitive science principles. So at the very least, maybe we can improve how we teach the theory of computation!
How Synthesis Also Subtly Fails
So yes, PICK is a validation workflow: you have some intent, the model proposes candidates, and PICK helps you check those candidates against what you meant. But that framing undersells the idea. What PICK also does is recover something synthesis tends to erase: an independent witness to user intent.
To see why that witness matters, it helps to remember what verification was for.
Verification is famously written P ⊧ ɸ: a program P implements a property ɸ. The check is informative precisely because P and ɸ are written independently. If both encode the same misconception, agreement rules out nothing; the redundancy disappears. (And this is the danger of having both sides of the verification coin generated by an LLM. PICK intervenes to make sure the LLM is not the only source of ɸ.)
Now consider synthesis: ɸ ⟹ P. The program is correct-by-construction. However, that means it is also incorrect-by-construction. When ɸ is wrong, the resulting P is wrong in precisely the same way, and no cross-check of P against ɸ can catch that. This was already true of classical deductive synthesis and of programming-by-example. It is wildly more true of synthesis-by-LLM. The LLM only sees the user’s natural language, which is a lossy hint of what they want.
Piling on more LLMs does not necessarily fix this. They share training data, share priors, and often share misconceptions. More models give you more agreement, faster. They do not necessarily give you more redundancy, which is what verification has always been about. And neither can know the user’s true intent: which is exactly what PICK is about.
Human Judgment as Specification
In PICK,
that independent witness is not a separately-written spec — it lives in the user’s classifications: each accept or reject is a commitment to a concrete behavior, and the candidates that survive must be consistent with all of them together. Taken as a whole, those commitments expose what the original prompt left unstated. Suppose the prompt was “a regex for dates”, and the model came back with several candidates. PICK puts strings in front of you: yes to 1/15/2025 and no to 13/01/2025 declares a position on day-month-year versus month-day-year — a question the prompt left implicit and the user may never have answered formally, even to themselves. The user arrives with a vague intent; PICK helps sharpen it — call it spec elucidation — not by interrogating them about formulae but by forcing them to commit on questions the prompt leaves implicit.
This is also why PICK can usefully fail. Sometimes none of the model’s candidates is right, and PICK ends with zero survivors. Under the spec-elucidation reading, that outcome means: the commitments you made through classification could not be satisfied by anything the model produced. Better to know than to ship the regex anyway.
This is also why we do not believe PICK becomes less useful as models improve. Better models do not make user intent more articulate — asked for “a regex matching countries of North America”, a more capable model still cannot tell you whether you want the Caribbean included, or where you want to stop heading south. Better models produce better candidates, faster — which shifts user effort precisely toward the work PICK is built to support.
To learn more, read our ECOOP 2026 paper, or try out the PICK:Regex tool in VS Code.
If you have a formal language with the closure properties above — we suspect you would be surprised how many do — we would very much like to hear from you.
LLMs ⭢ Regular Expressions, Responsibly!
Tags: Large Language Models, Semantics, Tools
Posted on 11 December 2025.This tool is part of a much broader effort to help us use GenAI responsibly. Please see our newer post with details about the broader context.
Do you use GenAI/LLMs to generate your regular expressions? We certainly do! But we always do it with trepidation, given the many slips that can occur with blindly pasting the output into a program. We may have been unclear in our prose, our prose may have been ambiguous, the domain may lend itself to ambiguity (what is a “date”?), the LLM may have misinterpreted what you said, the domain may have persistent misconceptions, and so on.
Oh, you read your regexes, you say? Is this a valid regex for dates?
^(?:(?:31-(?:0[13578]|1[02])-(?:\d{4}))|
(?:29|30-(?:0[13-9]|1[0-2])-(?:\d{4}))|
(?:29-02-(?:(?:\d\d(?:0[48]|[2468][048]|[13579][26]))|
(?:[048]000)))|
(?:0[1-9]|1\d|2[0-8]-(?:0[1-9]|1[0-2])-(?:\d{4})))
But we can do a lot better! Our new tool, PICK:Regex, does the following. It asks you for a prompt and sends it to a GenAI system. However, it doesn’t ask for one regex; instead, it uses an LLMs ability to interpret prose in multiple ways to generate multiple (about four) candidate expressions. (The details don’t matter, but if you want to you can open the images below in a new tab to read them more easily.)

In theory, that’s better than getting just one interpretation. But now you may have to read four regexes like the above, which is actually worse! Therefore, instead, PICK shows you concrete examples. Furthermore, the examples are carefully chosen to tell apart the regexes. You are then asked to upvote/downvote each example. As you do, you are actually voting on all the candidate regexes.
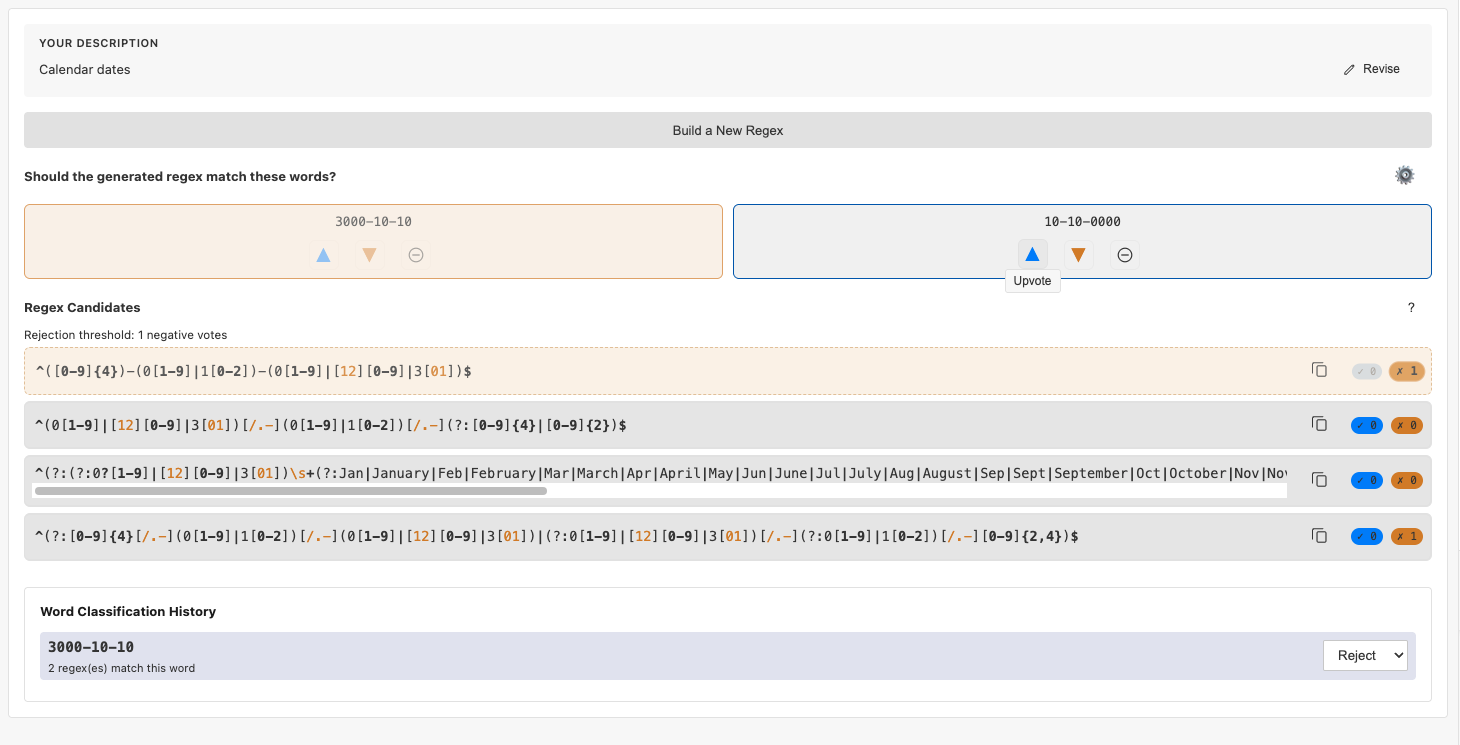
You can stop at any point (you’re always shown the regexes), but the process naturally halts when only one regex remains (this is your best candidate of the ones you’ve seen so far) or none remain (in which case it would have been dangerous to use the LLMs output!).
As you’re looking at examples, you may realize you could have provided a better prompt (or could have used a more expensive LLM). You don’t need to start over; you can revise your request. This generates regexes afresh, but critically, you don’t lose your hard work: your prior upvotes and downvotes are automatically applied to the new proposed regexes.
Also as you’re looking at examples, you might come up with some good ones of your own. You can type these into PICK and vote on them (i.e., provide both positive and negative examples), and PICK will add them to the example stream. Similarly, you can edit an example PICK has shown you before voting on it.
Finally, you can also change your mind. PICK shows you all your prior classifications at the bottom. If you change how you classified an example, that will update the scores of all the candidates.
PICK is based on the confluence of two very different bodies of ideas. It draws from cognitive science: the idea of understanding the abstract through the concrete, and the theory of contrasting cases. It also puts to work all the formal language closure properties you studied in a theory of computation class and wondered why and when they would ever be useful.
Enough prose! Please try PICK for yourself. It’s available as an extension from the Visual Studio Code Marketplace (it uses your VSCode LLM configuration). Visit this link, or search for SiddharthaPrasad.pick-regex in the Marketplace. If you don’t have a ready question, try a prompt like “countries of North America”—but before you do, what regex are you expecting? Think about it for a moment, then see what PICK offers you. Let us know what you think!
Iterative Student Program Planning using Transformer-Driven Feedback
Tags: Large Language Models, Education, Program Planning, User Studies
Posted on 05 July 2024.We’ve had a few projects now that address this idea of teaching students to plan out solutions to programming problems. A thus-far missing but critical piece is feedback on this planning process. Ideally we want to give students feedback on their plans before they commit to any code details. Our early studies had students express their plans in a semi-formalized way which would’ve allowed us to automatically generate feedback based on formal structure. However, our most recent project highlighted a strong preference towards more freedom in notation, with plans expressed in far less structured language. This presents a challenge when designing automated feedback.
So how do we interpret plans written with little to no restrictions on notation or structure, in order to still give feedback? We throw it at an LLM, right?
It’s never that simple. We first tried direct LLM feedback, handing the student plan to an LLM with instructions of what kinds of feedback to give. Preliminary feedback results ranged from helpful to useless to incorrect. Even worse, we couldn’t prevent the LLM from directly including a correct answer in its response.
So we built a different kind of feedback system. Student plans, expressed mostly in English, are translated into code via an LLM. (We do not allow the LLM to access the problem statement— otherwise it would silently correct student misconceptions when translating into code.) The resulting code is run against an instructor test suite, and the test suite results are shown to the student as feedback.
When we deployed this system, we found that the results from running the LLM-generated code against our instructor test suite seemed to serve as a useful proxy for student plan correctness. However, many issues from the LLM still caused a great deal of student frustration, especially from the LLM not having access to details from the problem statement.
LLMs are good at presenting correct code solutions and correcting errors, and there is clear incentive for these behaviors to improve. But these behaviors are sometimes counterproductive to student feedback. Creating LLM-based feedback systems still requires careful thought in both its design and presentation to students.
For more detail on our design and results, read here.
Generating Programs Trivially: Student Use of Large Language Models
Tags: Large Language Models, Education, Formal Methods, Properties, Testing, User Studies
Posted on 19 September 2023.The advent of large language models like GPT-3 has led to growing concern from educators about how these models can be used and abused by students in order to help with their homework. In computer science, much of this concern centers on how LLMs automatically generate programs in response to textual prompts. Some institutions have gone as far as instituting wholesale bans on the use of the tool. Despite all the alarm, however, little is known about whether and how students actually use these tools.
In order to better understand the issue, we gave students in an upper-level formal methods course access to GPT-3 via a Visual Studio Code extension, and explicitly granted them permission to use the tool for course work. In order to mitigate any equity issues around access, we allocated $2500 in OpenAI credit for the course, enabling free access to the latest and greatest OpenAI models.
Can you guess the total dollar value of OpenAI credit used by students?
We then analyzed the outcomes of this intervention, how and why students actually did and did not use the LLM.
Which of these graphs do you think best represents student use of GPT models over the semester?
When surveyed, students overwhelmingly expressed concerns about using GPT to help with their homework. Dominant themes included:
- Fear that using LLMs would detract from learning.
- Unfamiliarity with LLMs and issues with output correctness.
- Fear of breaking course rules, despite being granted explicit permission to use GPT.
Much ink has been spilt on the effect of LLMs in education. While our experiment focuses only on a single course offering, we believe it can help re-balance the public narrative about such tools. Student use of LLMs may be influenced by two opposing forces. On one hand, competition for jobs may cause students to feel they must have “perfect” transcripts, which can be aided by leaning on an LLM. On the other, students may realize that getting an attractive job is hard, and decide they need to learn more in order to pass interviews and perform well to retain their positions.
You can learn more about the work from the paper.