The Brown PLT Blog

Articles by tag: Security
Examining the Privacy Decisions Facing Users
Verifying Extensions' Compliance with Firefox's Private Browsing Mode
Social Ratings of Application Permissions (Part 4: The Goal)
Social Ratings of Application Permissions (Part 3: Permissions Within a Domain)
Social Ratings of Application Permissions (Part 2: The Effect of Branding)
Social Ratings of Application Permissions (Part 1: Some Basic Conditions)
A Privacy-Affecting Change in Firefox 20
Belay Lessons: Smarter Web Programming
ADsafety
The PerMission Store
Tags: Android, Permissions, Privacy, Security, Tools, User Studies
Posted on 21 February 2017.This is Part 2 of our series on helping users manage app permissions. Click here to read Part 1.
As discussed in Part 1 of this series, one type of privacy decision users have to make is which app to install. Typically, when choosing an app, users pick from the first few apps that come up when they search a keyword in their app store, so the app store plays a big roll in which apps users download.
Unfortunately, most major app stores don’t help users make this decision in a privacy-minded way. Because these stores don’t factor privacy into their ranking, the top few search results probably aren’t the most privacy-friendly, so users are already picking from a problematic pool. Furthermore, users rely on information in the app store to choose from within that limited pool, and most app stores offer very little in the way of privacy information.
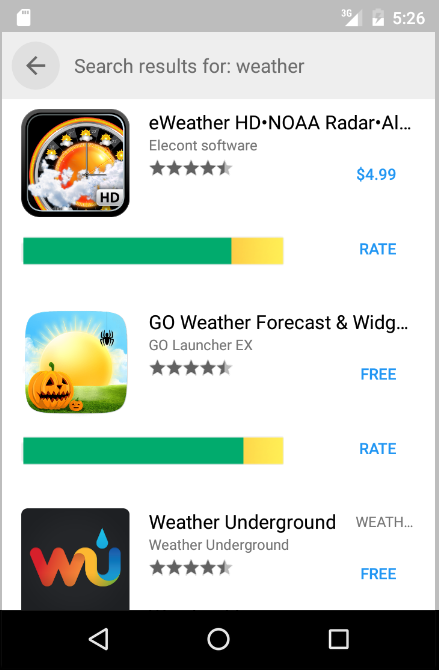
We’ve built a marketplace, the PerMission Store, that tackles both the ranking and user information concerns by adding one key component: permission-specific ratings. These are user ratings, much like the star ratings in the Google Play store, but they are specifically about an app’s permissions.1
To help users find more privacy friendly apps, the privacy ratings are incorporated into the PerMission Store’s ranking mechanism, so that apps with better privacy scores are more likely to appear in the top hits for a given search. (We also consider factors like the star rating in our ranking, so users are still getting useful apps.) So users are selecting from a more privacy-friendly pool of apps right off the bat.
Apps’ privacy ratings are also displayed in an easy-to-understand way, alongside other basic information like star rating and developer. This makes it straightforward for users to consider privacy along with other key factors when deciding which app to install.
Incorporating privacy into the store itself makes it so that choosing privacy-friendly apps is as a natural as choosing useful apps.
The PerMission Store is currently available as an Android app and can be found on Google Play.
A more detailed discussion of the PerMission Store can be found in Section 3.1 of our paper.
This is Part 2 of our series on helping users manage app permissions. Click here to read Part 1.
1: As a bootstrapping mechanism, we’ve collected rating for a couple thousand apps from Mechanical Turk. Ultimately, though, we expect the ratings to come from in-the-wild users.
Examining the Privacy Decisions Facing Users
Tags: Android, Permissions, Privacy, Security, User Studies
Posted on 25 January 2017.This is Part 1 of our series on helping users manage app permissions. Click here to read Part 2.
It probably comes as no surprise to you that users are taking their privacy in their hands every time they install or use apps on their smartphones (or tablets, or watches, or cars, or…). This begs the question, what kinds of privacy decisions are users actually making? And how can we help them with those decisions?
At first blush, users can manage privacy in two ways: by choosing which apps to install, and by managing their apps’ permissions once they’ve installed them. For the first type of decision, users could benefit from a privacy-conscious app store to help them find more privacy-respecting apps. For the second type of decision, users would be better served by an assistant that helps them decide which permissions to grant.
Users can only making installation decisions when they actually have a meaningful choice between different apps. If you’re looking for Facebook, there really aren’t any other apps that you could use instead. This left us wondering if users ever have a meaningful choice between different apps, or whether they are generally looking for a specific app.
To explore this question, we surveyed Mechanical turk workers about 66 different Android apps, asking whether they thought the app could be replaced by a different one. The apps covered a broad range of functionality, from weather apps, to games, to financial services.
It turns out that apps vary greatly in their “replaceability,” and, rather than falling cleanly into “replaceable” and “unique” groups, they run along a spectrum between the two. At one end of the spectrum you have apps like Instagram, which less than 20% of workers felt could be replaced. On the other end of the spectrum are apps like Waze, which 100% of workers felt was replaceable. In the middle are apps whose replaceability depends on which features you’re interested in. For example, take an app like Strava, which lets you track your physical activity and compete with friends. If you only want to track yourself, it could be replaced by something like MapMyRide, but if you’re competing with friends who all use Strava, you’re pretty much stuck with Strava.
Regardless of exactly which apps fall where on the spectrum, though, there are replaceable apps, so users are making real decisions about which apps to install. And, for irreplaceable apps, they are also having to decide how to manage those apps’ permissions. These two types of decisions require two approaches to assisting users. A privacy-aware marketplace would aid users with installation decisions by helping them find more privacy-respecting apps, while a privacy assistant could help users manage their apps’ permissions.
Click here to read about our privacy-aware marketplace, the PerMission Store, and stay tuned for our upcoming post on a privacy assistant!
A more detailed discussion of this study can be found in Section 2 of our paper.
Verifying Extensions' Compliance with Firefox's Private Browsing Mode
Tags: Browsers, JavaScript, Programming Languages, Security, Types, Verification
Posted on 19 August 2013.All modern browsers now support a “private browsing mode”, in which the browser ostensibly leaves behind no traces on the user's file system of the user's browsing session. This is quite subtle: browsers have to handle caches, cookies, preferences, bookmarks, deliberately downloaded files, and more. So browser vendors have invested considerable engineering effort to ensure they have implemented it correctly.
Firefox, however, supports extensions, which allow third party code to run with all the privilege of the browser itself. What happens to the security guarantee of private browsing mode, then?
The current approach
Currently, Mozilla curates the collection of extensions, and any extension must pass through a manual code review to flag potentially privacy-violating behaviors. This is a daunting and tedious task. Firefox contains well over 1,400 APIs, of which about twenty are obviously relevant to private-browsing mode, and another forty or so are less obviously relevant. (It depends heavily on exactly what we mean by the privacy guarantee of “no traces left behind”: surely the browser should not leave files in its cache, but should it let users explicitly download and save a file? What about adding or deleting bookmarks?) And, if the APIs or definition of private-browsing policy ever change, this audit must be redone for each of the thousands of extensions.
The asymmetry in this situation should be obvious: Mozilla auditors should not have to reconstruct how each extension works; it should be the extension developers' responsibility to convince the auditor that their code complies with private-browsing guarantees. After all, they wrote the code! Moreover, since auditors are fallible people, too, we should look to (semi-)automated tools to lower their reviewing effort.
Our approach
So what property, ultimately, do we need to confirm about an extension's code to ensure its compliance? Consider the pseudo-code below, which saves the current preferences to disk every few minutes:
var prefsObj = ...
const thePrefsFile = "...";
function autoSavePreferences() {
if (inPivateBrowsingMode()) {
// ...must store data only in memory...
return;
} else {
// ...allowed to save data to disk...
var file = openFile(thePrefsFile);
file.write(prefsObj.tostring());
}
}
window.setTimeout(autoSafePreferences, 3000);The key observation is that this code really defines two programs that happen to share the same source code: one program runs when the browser is in private browsing mode, and the other runs when it isn't. And we simply do not care about one of those programs, because extensions can do whatever they'd like when not in private-browsing mode. So all we have to do is “disentangle” the two programs somehow, and confirm that the private-browsing version does not contain any file I/O.
Technical insight
Our tool of choice for this purpose is a type system for JavaScript. We've used such a system before to analyze the security of the ADsafe sandbox. The type system is quite sophisticated to handle JavaScript idioms precisely, but for our purposes here we need only part of its expressive power. We need three pieces: first, three new types; second, specialized typing rules; and third, an appropriate type environment.
- We define one new primitive type:
Unsafe. We will ascribe this type to all the privacy-relevant APIs. - We use union types to define
Ext, the type of “all private-browsing-safe extensions”, namely: numbers, strings, booleans, objects whose fields areExt, and functions whose argument and return types areExt. Notice thatUnsafe“doesn’t fit” intoExt, so attempting to use an unsafe function, or pass it around in extension code, will result in a type error. - Instead of defining
Boolas a primitive type, we will instead defineTrueandFalseas primitive types, and defineBoolas their union.
- If an expression has some union type, and only one component
of that union actually typechecks, then we optimistically say
that the expression typechecks even with the whole union type.
This might seem very strange at first glance: surely, the
expression
5("true")shouldn't typecheck? But remember, our goal is to prevent privacy violations, and the code above will simply crash---it will never write to disk. Accordingly, we permit this code in our type system. - We add special rules for typechecking if-expressions. When
the condition typechecks at type
True, we only check the then-branch; when the condition typechecks at typeFalse, we only check the else-branch. (Otherwise, we check both branches as normal.)
- We give all the privacy-relevant APIs the
type
Unsafe. - We give the API
inPrivateBrowsingMode()the typeTrue. Remember: we just don't care what happens when it's false!
Put together, what do all these pieces achieve?
Because Unsafe and Ext are disjoint from
each other, we can safely segregate any code into two pieces that
cannot communicate with each other. By carefully initializing the
type environment, we make Unsafe precisely delineate
the APIs that extensions should not use in private browsing mode.
The typing rules for if-expressions plus the type
for inPrivateBrowsingMode() amount to disentangling the
two programs from each other: essentially, it implements dead-code
elimination at type-checking time. Lastly, the rule about union
types makes the system much easier for programmers to use, since they
do not have to spend any effort satisfying the typechecker about
properties other than this privacy guarantee.
In short, if a program passes our typechecker, then it must not call any privacy-violating APIs while in private-browsing mode, and hence is safe. No audit needed!
Wait, what about exceptions to the policy?
Sometimes, extensions have good reasons for writing to disk even
while in private-browsing mode. Perhaps they're updating their
anti-phishing blacklists, or they implement a download-helper that
saves a file the user asked for, or they are a bookmark manager. In
such cases, there simply is no way for the code to typecheck. As in
any type system, we provide a mechanism to break out of the type
system: an unchecked typecast. We currently write such casts
as cheat(T). Such casts must be checked by a human
auditor: they are explicitly marking the places where the extension
is doing something unusual that must be confirmed.
(In our original version, we took our cue from Haskell and wrote
such casts as unsafePerformReview, but sadly that is
tediously long to write.)
But does it work?
Yes.
We manually analyzed a dozen Firefox extensions that had already
passed Mozilla's auditing process. We annotated the extensions with
as few type annotations as possible, with the goal of forcing the
code to pass the typechecker, cheating if necessary.
These annotations found five extensions that violated
the private-browsing policy: they could not be typechecked without
using cheat, and the unavoidable uses
of cheat pointed directly to where the extensions
violated the policy.
Further reading
We've written up our full system, with more formal definitions of the types and worked examples of the annotations needed. The writeup also explains how we create the type environment in more detail, and what work is necessary to adapt this system to changes in the APIs or private-browsing implementation.
Social Ratings of Application Permissions (Part 4: The Goal)
Tags: Android, Permissions, Security, User Studies
Posted on 31 May 2013.(This is the fourth post in our series on Android application permissions. Click through for Part 1, Part 2, and Part 3.)
In this, the final post in our application permissions series, we'll discuss our trajectory for this research. Ultimately, we want to enable users to make informed decisions about the apps they install on their smartphones. Unfortunately, informed consent becomes difficult when you are asking users to make decisions in an area in which they have little expertise. Rating systems allow users to rely on the collective expertise of other users.
We intend to integrate permission ratings in to the app store in much the same way that functionality ratings are already there. This allows users to use visual cues they are already familiar with, such as the star rating that appears on the app page.

We may also wish to convey to users how each individual permission is rated. This finer-grained information gives users the ability to make decisions in line with their own priorities. For example, if users are particularly concerned about the integrity of their email accounts, an app that has a low-rated email access permission may be unacceptable to a user, even if the app receives otherwise high scores for permissions. We can again leverage well-known visual cues to convey this information, perhaps with meters similar to password meters, as seen in the mock-up image below.
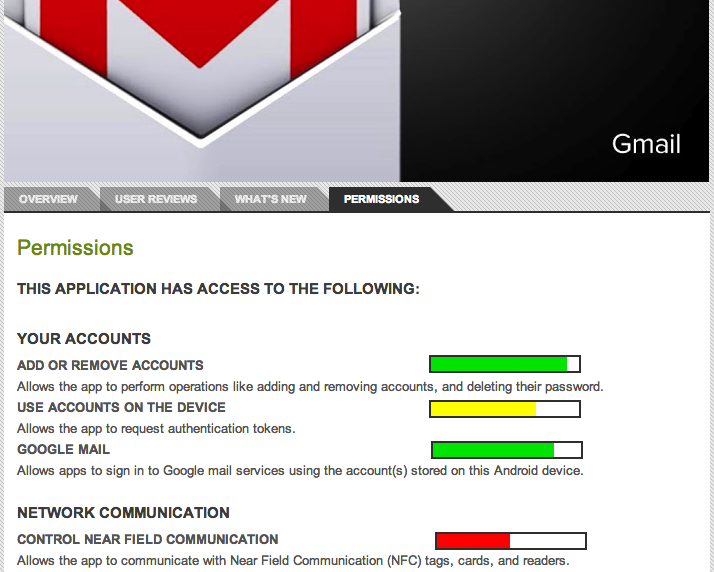
There are a variety of other features we may want to incorporate into a permission rating system: allowing users to select favorite or trusted raters could enable them to rely on a particularly savvy relative or friend. Additionally, users could build a privacy profile, and view ratings only from like-minded users. Side-by-side comparisons of different apps' permissions rating could let users choose between similar apps more easily.
Giving users an easy way to investigate app permissions will allow them to make privacy a part of their decision-making process without requiring extra work or research on their part. This will improve the overall security of using a smartphone (or other permission-rich device), leaving users less vulnerable to unintended sharing of their personal data.
There's more! Click through to read Part 1, Part 2, and Part 3of the series!Social Ratings of Application Permissions (Part 3: Permissions Within a Domain)
Tags: Android, Permissions, Security, User Studies
Posted on 29 May 2013.(This is the third post in our series on Android application permissions. Click through for Part 1, Part 2, and Part 4.)
In a prior post we discussed the potential value for a social rating system for smartphone apps. Such a system would give non-expert users some information about apps before installing them. Ultimately, the goal of such a system would be to help users choose between different apps with similar functionality (for an app they need) or decide if the payoff of an app is worth the potential risk of installing it (for apps they want). Both of these use cases would require conscientious ratings of permissions.
We chose to study this issue by considering the range of scores that respondents give to permissions. If respondents were not considering the permissions carefully, we would expect the score to be uniform across different permissions. We examined the top five weather forecasting apps in the Android marketplace: The Weather Channel, WeatherBug Elite, Acer Life Weather, WeatherPro, and AccuWeather Platinum. We chose weather apps because they demonstrate a range of permission requirements; Acer Life Weather requires only four permissions while AccuWeather Platinum and WeatherBug Elite each require eleven permissions. We asked respondents to rate an app's individual permissions as either acceptable or unacceptable.
Our findings, which we present in detail below, show that users will rate application permissions conscientiously. In short, we found that although the approval ratings for each permission are all over 50%, they vary significantly from permission to permission. Approval ratings for individual permissions ranged from 58.8% positive (for “Modify or delete the contents of your USB storage”) to 82.5% (for “Find accounts on the device”). The table at the bottom of this post shows the percentage of users who considered a given permission acceptable. Because the ratings range from acceptable to unacceptable, they are likely representative of a given permissions' risk (unlike uniformly positive or negative reviews). This makes them effective tools for users in determining which applications they wish to install on their phones.
Meaningful ratings tell us that it is possible to build a rating system for application permissions to accompany the existing system for functionality. In our next post, we'll discuss what such a system might look like!
| Modify or delete the contents of your USB storage | 58.8 % |
| Send sticky broadcast | 60 % |
| Control vibration | 67.5 % |
| View Wi-Fi connections | 70 % |
| Read phone status and identity | 70 % |
| Test access to protected storage | 72.5 % |
| Google Play license check | 73.8 % |
| Run at startup | 75.8 % |
| Read Google service configuration | 76.3 % |
| Full network access | 76.5 % |
| Approximate location | 79 % |
| View network connections | 80.5 % |
| Find accounts on the device | 82.5 % |
Social Ratings of Application Permissions (Part 2: The Effect of Branding)
Tags: Android, Permissions, Security, User Studies
Posted on 22 May 2013.(This is the second post in this series. Click through for Part 1 and Part 3, and Part 4.)
In a prior post, we introduced our experiments investigating user ratings of smartphone application permissions. In this post we'll discuss the effect that branding has on users' evaluation of an app's permissions. Specifically, what effect does a brand name have on users' perceptions and ratings of an app?
We investigated this question using four well-known apps: Facebook, Gmail, Pandora Radio, and Angry Birds. Subjects were presented with a description of the app and its required permissions. We created surveys displaying the information presented to users in the Android app store, and asked users to rate the acceptability of the apps required permissions, and indicate whether they would install the app on their phone. Some of the subjects were presented with the true description of the app including its actual name, and the rest were presented with the same description, but with the well-known name replaced by a generic substitute. For example, Gmail was disguised as Mangogo Mail.
In the cases of Pandora and Angry Birds, there were no statistically significant differences in subjects' responses between the two conditions. However, there were significant differences in the responses for Gmail and Facebook.
For Gmail, participants rated the generic version's permissions as less acceptable and were less likely to install that version. For Facebook, however, participants rated the permissions for the generic version as less acceptable, but it had no effect on whether subjects would install the app. These findings raise interesting questions. Are the differences in responses caused by privacy considerations or other concerns, such as ability to access existing accounts? Why are people more willing to install a less secure social network than an insecure email client?
It is possible that people would be unwilling to install a generic email application because they want to be certain they could access their existing email or social network accounts. To separate access concerns from privacy concerns, we did a follow-up study in which we asked subjects to evaluate an app that was an interface over a brand-name app. In Gmail's case, for instance, subjects were presented with Gmore!, an app purporting to offer a smoother interaction with one's Gmail account.
Our findings for the interface apps was similar to the generic apps: for Facebook, subjects rated the permissions as less acceptable, but there was no effect on the likelihood of their installing the app; for Gmail, subjects rated the permissions as less acceptable and were less likely to install the app. In fact, the app that interfaced with Gmail had the lowest installation rate of any of the apps: just 47% of respondents would install the app, as opposed to 83% for brand-name Gmail, and 71% for generic Mangogo Mail. This suggests that subjects were concerned about the privacy of the apps, not just their functionality.
It is interesting that the app meant to interface with Facebook showed no significant difference in installation rates. Perhaps users are less concerned about the information on a social network than the information in their email, and see the potential consequences of installing an insecure social network as less dire than those associated with installing an insecure email client. This is just speculation, and this question requires further examination.
Overall, it seems that branding may play a role in how users perceive a given app's permissions, depending on the app. We would like to examine the nuances of this effect in greater detail. Why does this effect occur in some apps but not others? When does the different perception of permissions affect installation rates and why? These questions are exciting avenues for future research!
There's more! Click through to read Part 1, Part 3, and Part 4 of the series!Social Ratings of Application Permissions (Part 1: Some Basic Conditions)
Tags: Android, Permissions, Security, User Studies
Posted on 18 May 2013.(This is the first post in our series on Android application permissions. Click through for Part 2, Part 3, and Part 4.)
Smartphones obtain their power from allowing users to install arbitrary apps to customize the device’s behavior. However, with this versatility comes risk to security and privacy.
Different manufacturers have chosen to handle this problem in different ways. Android requires all applications to display their permissions to the user before being installed on the phone (then, once the user installs it, the application is free to use its permissions as it chooses). The Android approach allows users to make an informed decision about the applications they choose to install (and to do so at installation time, not in the midst of a critical task), but making this decision can be overwhelming, especially for non-expert users who may not even know what a given permission means. Many applications present a large number of permissions to users, and its not always clear why an application requires certain permissions. This requires users to gamble on how dangerous they expect a given application to be.
One way to help users is to rely on the expertise or experiences of other users, an approach that is already common in online marketplaces. Indeed, the Android application marketplace already allows users to rate applications. However, these reviews are meant to rate the application as a whole, and are not specific to the permissions required by the application. Therefore the overall star rating of an application is largely indicative of users’ opinions of the functionality of an application, not the security of the application. When users do offer opinions about security and privacy, as they sometimes do, these views are buried in text and lost unless the user reads all the comments.
Our goal is to make security and privacy ratings first-class members of the marketplace rating system. We have begun working on this problem, and will explain our preliminary results in this and a few more blog posts. All the experiments below were conducted on Mechanical Turk.
In this post, we examine the following questions:
- Will people even rate the app's permissions? Even when there are lots of permissions to rate?
- Does users’ willingness to install a given application change depending on when they are asked to make this choice - before they’ve reflected on the individual permissions or after?
- Do their ratings differ depending on how they were told about the app?
We created surveys that mirrored the data provided by the Android installer (and as visible on the Google Play Web site). We examined four applications: Facebook, Gmail, Pandora, and Angry Birds. We asked respondents to rate the acceptability of the permissions required by each application and state whether they would install the application if they needed an app with that functionality.
In the first condition, respondents were asked whether they would install the app before
or after they were asked to rate the app’s individual permissions. In this case, only Angry
Birds showed any distinction between the two conditions: Respondents were more likely to install
the application if the were asked after they were asked to rate the permissions.
Overall, however, the effect of asking before or after was very small; this is good, because it
suggests that in the future we can ignore the overall rating, and it also offers some flexibility for
interface design.
The second condition was how the subject heard about the app (or rather, how they were asked to
imagine they heard about it). Subjects were asked to imagine either that the app had been recommended
to them by a colleague, that the app was a top “featured app” in the app store, or that the
app was a top rated app in the app store. In this case, only Facebook showed any interesting results:
respondents were less likely to install the application if it had been recommended by a colleague than
if it was featured or highly rated. This result is particularly odd given that, due to the network effect
of an app like Facebook, we would expect the app to be more valuable if friends or colleagues also use it.
We would like to study this phenomenon further.
Again, though this finding may be interesting, the fact that it has so little impact means we can set this
condition aside in our future studies, thus narrowing the search space of factors that do affect how users
rate permissions.
That concludes this first post on this topic. In future posts we’ll examine the effect of branding, and present detailed ratings of apps in one particular domain. Stay tuned!
There's more! Click through to read Part 2, Part 3, and Part 4 of the series!
A Privacy-Affecting Change in Firefox 20
Posted on 10 April 2013.
Attention, privacy-conscious Firefox users! Firefox has supported private browsing mode (PBM) for a long time, and Mozilla's guidelines for manipulating privacy sensitive data have not changed...but the implementation of PBM has, with potentially surprising consequences. Previously innocent extensions may now be leaking private browsing information. Read on for details.
Global Private-Browsing Mode: Easy!
In earlier versions of Firefox, PBM was an all-or-nothing affair: either all currently open windows were in private mode, or none of them were. This made handling sensitive data easy; the essential logic for privacy-aware extensions is simply:
if (inPBM)
...must store data only in memory...
else
...allowed to save data to disk...(For the technically curious reader, there were some additional steps to take if extension code used shared modules: they additionally had to listen to events signalling exit from PBM, to flush any sensitive data from memory. This was not terribly hard; trying to "do the right thing" would generally work.)
Per-window Private Browsing: Trickier!
However, in Firefox 20, PBM is now a per-window setting. This means that both public and private windows can be open simultaneously. Now, the precautions above are not sufficient. Consider a session-management extension, that periodically saves all open windows and tabs:
window.setInterval(3000, function() {
if (inPBM) return;
var allWindowsAndTabs = enumerateAllWindowsAndTabs();
save(allWindowsAndTabs);
});
Most likely, this code internally uses Firefox's
nsIWindowMediator API to produce the enumeration. The
trouble is, that API does exactly what it claims: it enumerates
all windows—public and private—regardless of the
privacy status of the calling window. In particular, suppose that
both public and private windows were open simultaneously, and the
callback above ran in one of the public windows. Then
inPBM would be false, and so the rest of the
function would continue, enumerate all windows, and save them: a clear
violation of private browsing, even though no code was running in the
private browsing windows!
This code was perfectly safe in earlier versions of Firefox, because the possibility of having private and public windows open simultaneously just could not occur. This example demonstrates the need to carefully audit interactions between seemingly unrelated APIs, features, and modes—ideally, mechanically.
Takeaway Lessons
Private browsing “mode” is no longer as modal as it used to be. Privacy-conscious users need to take a careful look at the extensions they use—especially ones that observe browser-wide changes, like the session-manager example above—and double-check that they appear to behave properly with the new private-browsing changes, or (better yet) have been updated to support PBM explicitly.
Privacy-conscious developers need to take a careful look at their code and ensure that it's robust enough to handle these changed semantics for PBM, particularly in all code paths that occur after a check for PBM has returned false.
Belay Lessons: Smarter Web Programming
Posted on 18 December 2011.
This post comes from the keyboard of Matt Carroll, who has worked with us for the past two years. He's the main implementer of desugaring for S5, and spent this semester rebuilding and improving in-house Brown PLT web applications. He writes about his experience here.
The Brown computer science department uses a home-grown web application called Resume to conduct its faculty recruitment process. This semester, Joe and I re-wrote Resume with Belay. Belay is the product of Joe and Arjun's summer research at Google: it's an ongoing inquiry into web development best practices, specifically concerning identity, account management, and security. From my perspective (that of a novice web programmer), getting to grips with the Belay philosophy was a thought-provoking experience, and a great education in the pitfalls that a web developer must (unfortunately) bear in mind.
I Am Not My Cookies
Standard web applications make use of cookies for authentication. When you visit a site and enter your credentials, the site's response sets a session cookie in your browser. Subsequent requests to the site use the information in the cookie to determine 'who you are' and whether 'you' are allowed to do what 'your' request is trying to do. I use quotations in the prior sentence to highlight the fact that HTTP cookies are a poor method of establishing user identity. If another, malicious, web site you visit manages to trick you into sending a request to the original site, that request will contain your cookie, and the good site may treat that request as legitimate and execute it. This is the infamous cross-site request forgery (CSRF) attack.
Belay applications eschew the use of cookies, especially for authentication, and thus they are secure by design against this type of vulnerability. This begs the question: without cookies, how do Belay applications decide whether a request is authenticated? The answer may shock you (as it did me): all requests that reach request handler code are treated as legitimate. At this point, we must examine the server-side of Belay apps in greater detail.
Web Capabilities
Your everyday possibly-CSRF-vulnerable site probably has a URL scheme with
well-known endpoints that lead directly to application functionality. For
example, to post to your blog, you (typically via your browser) send a POST
request to www.blog.com/post with your cookies and the
blog body's text. The server-side handler finds your account in the database using
your cookie, checks that your account can post to that blog, and adds a new
post. If the whole surface of the site's URL space is well-known, a CSRF-ing
attacker can excercise the entirety of a user's view of the site with one
compromised cookie.
In contrast, Belay applications have few well-known URLs, corresponding to the public entry points to the site (the login and contact pages, for instance). Instead, Belay's libraries allow server-side code to dynamically generate random unique URLs and map them to request handler functions. Each of these handlers services a particular type of request for a particular set of data. The randomly generated "capability" urls are embedded in the JavaScript or markup returned to the browser. In a well-designed Belay application, each page has the minimum necessary set of capabilities to carry out its mission, and the capabilities are scoped to the minimum set of data with which they need concern themselves. After you successfully log in to a Belay site, the response will contain the set of capabilities needed by the page, and scoped to only that data which is needed by the page's functionality and associated with your user account. No cookies are necessary to identify you as a user or to authenticate your requests.
A Belay app uses its limited URL scheme as its primary security mechanism, ignoring requests unless they come along trusted capability URLs created by a prior, explicit grant. As long as we can rely on our platform's ability to generate unguessable large random numbers, attackers are out of luck. And, even if a capability URL is leaked from its page, it is scoped to only a small set of data on the server, so the vulnerability is limited. This is a much-improved situation compared to a site using cookie-based authentication---leaking a cookie leaks access to the user's entire view of the site.
Grants and Cap Handlers
Here's a Belay request handler, taken from Resume:
class GetLetterHandler(bcap.CapHandler):
def get(self, reference):
filename = get_letter_filename(reference)
return file_response(filename, 'letter')This handler simply looks up the filename associated with a reference and
returns it (using a few helper functions). Accessing a letter written by an
applicant's reference is quite a sensitive operation---letting the wrong
person access a letter would be a serious security bug. Yet,
GetLetterHandler is a two-liner with no apparent security checks
or guards. How can this be safe?
To answer this, we need to consider how a client can cause
GetLetterHandler to be invoked. The Belay server library will
only invoke this handler via capability URLs created with a grant
to GetLetterHandler. So, we can search the codebase for code
that granted such access. A quick search shows one spot:
class GetApplicantsHandler(bcap.CapHandler):
def get(self, reviewer):
applicants_json = []
for applicant in reviewer.get_applicants():
# ... some processing
refs_json = []
for ref in applicants.get_references():
refs_json.append({
'refName': ref.name,
'getLetter': bcap.grant(GetLetterHandler, ref))
})
# ... add some things to applicants_json
return bcap.bcapResponse(applicants_json) When GetApplicantsHandler is invoked, it will return a
structure that, for each applicant, shows something like:
{
name: 'Theodore Roosevelt',
getLetter:
'https://resume.cs.brown.edu/cap/f7327056-4b91-ad57-e5e4f6c514b6'
} On the server, the string
f7327056-4b91-ad57-e5e4f6c514b6 was created and mapped to
the pair of GetLetterHandler and the Reference
database item for Theodore Roosevelt. A GET request to the URL above will
return the reference letter. Note a nice feature of this setup: the server
doesn't use any information from the client, other than the capability URL, to
decide which reference's letter to return. Thus, a client cannot try
providing different id's or other parameters to explore which letters they
have access to. Only those explicitly granted are accessible.
Poking around in the codebase more, we can see that
GetApplicantsHandler is only granted to reviewers, who can only
create accounts via an email from the administrator. This reasoning is how we
convince ourselves, as developers, that we haven't screwed up and given away
the ability to see a letter to the wrong user. We do all of this without
worrying about a check on accessing the letter, instead relying on the
unguessability of the URLs generated by grant to enforce our
access restrictions.
This may seem like a new-concept overload, and indeed, I had that exact reaction at first. Over time I gained familiarity with the Belay style, and I became more and more convinced by the benefits it offers. Porting Resume became a fairly straightforward process of identifying each server-side request handler, converting it to a Belay handler, and ensuring that whatever pages needed that functionality received grants to call the handler. There were wrinkles, many due to the fact that Resume also uses Flapjax (a language/library for reactive programming in the browser). Flapjax is another Brown PLT product and it is certainly worthy of its own blog post. We had to account for the interaction between Belay's client-side library and Flapjax.
Note that Belay isn't the first place these ideas have surfaced. Belay builds on foundational research: Waterken and PLT Web Server both support cookie-less, capability-based web interactions. The Belay project addresses broader goals in identity management and sharing on the web, but we've leveraged its libraries to build a more robust system for ourselves.
At the end, the benefits of the redesigned Resume are numerous. Cookies are no longer involved. JavaScript code doesn't know or care about unique IDs for picking items out of the database. Random HTTP request probes result in a 404 response and a line in the server's log, instead of a possible data corruption. You can open as many tabs as you like, with each one logged into its own Resume account, and experience no unwanted interference. We were able to realize these improvements while re-using a significant portion of the original Resume code, unchanged.
After my experience with the Resume port, I'm certainly a Belay fan. The project has more to say about topics such as cross-site authorization, sharing, and multi-site identity management, so check out their site and stay tuned for future updates:
Belay ResearchADsafety
Tags: Browsers, JavaScript, Programming Languages, Security, Types, Verification
Posted on 13 September 2011.
A mashup is a webpage that mixes and mashes content from various sources. Facebook apps, Google gadgets, and various websites with embedded maps are obvious examples of mashups. However, there is an even more pervasive use case of mashups on the Web. Any webpage that displays third-party ads is a mashup. It's well known that third-party content can include third-party cookies; your browser can even block these if you're concerned about "tracking cookies". However, third party content can also include third-party JavaScript that can do all sorts of wonderful and malicious things (just some examples).
Is it possible to safely embed untrusted JavaScript on a page? Google Caja, Microsoft Web Sandbox, and ADsafe are language-based Web sandboxes that try to do so. Language-based sandboxing is a programming language technique that restricts untrusted code using static and runtime checks and rewriting potential dangerous calls to safe, trusted functions.
Sandboxing JavaScript, with all its corner cases, is particularly hard. A
single bug can easily break the entire sandboxing system. JavaScript sandboxes
do not clearly state their intended guarantees, nor do they clearly argue why
they are safe. 
Verifying Web Sandboxes
A year ago, we embarked on a project to verify ADsafe, Douglas Crockford's Web sandbox. ADsafe is admittedly the simplest of the aforementioned sandboxes. But, we were also after the shrimp bounty that Doug offers for sandbox-breaking bugs:
Write a program [...] that calls the alert function when run on any browser. If the program produces no errors when linted with the ADsafe option, then I will buy you a plate of shrimp. (link)A year later, we've produced a USENIX Security paper on our work, which we presented in San Francisco in August. The paper discusses the many common techniques employed by Web sandboxes and discusses the intricacies of their implementations. (TLDR: JavaScript and the DOM are really hard.) Focusing on ADsafe, it precisely states what ADsafety actually means. The meat of the paper is our approach to verifying ADsafe using types. Our verification leverages our earlier work on semantics and types for JavaScript, and also introduces some new techniques:
- Check out the ★s and ☠s in our object types; we use them to type-check "scripty" features of JavaScript. ☠ marks a field as "banned" and ★ specifies the type of all other fields.
- We also characterize JSLint as a type-checker. The Widget type presented in the paper specifies, in 20 lines, the syntactic restrictions of JSLint's ADsafety checks.
Unlike conventional type systems, ours does not prevent runtime errors. After all, stuck programs are safe because they trivially don't execute any code. If you think type systems only catch "method not found" errors, you should have a look at ours.
We found bugs in both ADsafe and JSLint that manifested as type errors. We reported all of them and they were promptly fixed by Doug Crockford. A big thank you to Doug for his encouragement, for answering our many questions, and for buying us every type of shrimp dish in the house.

Learn more about ADsafety! Check out:
- The paper, code, and proofs;
- Video of Arjun presenting at USENIX Security;
- ADsafe and JSLint.