The Brown PLT Blog

Articles by tag: User Studies
Crowdsourcing User Studies for Formal Methods
User Studies of Principled Model Finder Output
The PerMission Store
Examining the Privacy Decisions Facing Users
CS Student Work/Sleep Habits Revealed As Possibly Dangerously Normal
Social Ratings of Application Permissions (Part 4: The Goal)
Social Ratings of Application Permissions (Part 3: Permissions Within a Domain)
Social Ratings of Application Permissions (Part 2: The Effect of Branding)
Social Ratings of Application Permissions (Part 1: Some Basic Conditions)
Can We Crowdsource Language Design?
Tags: Programming Languages, User Studies, Semantics
Posted on 06 July 2017.Programming languages are user interfaces. There are several ways of making decisions when designing user interfaces, including:
- a small number of designers make all the decisions, or
- user studies and feedback are used to make decisions.
Most programming languages have been designed by a Benevolent Dictator for Life or a committee, which corresponds to the first model. What happens if we try out the second?
We decided to explore this question. To get a large enough number of answers (and to engage in rapid experimentation), we decided to conduct surveys on Amazon Mechanical Turk, a forum known to have many technically literate people. We studied a wide range of common programming languages features, from numbers to scope to objects to overloading behavior.
We applied two concrete measures to the survey results:
- Consistency: whether individuals answer similar questions the same way, and
- Consensus: whether we find similar answers across individuals.
Observe that a high value of either one has clear implications for language design, and if both are high, that suggests we have zeroed in on a “most natural” language.
As Betteridge’s Law suggests, we found neither. Indeed,
-
A surprising percentage of workers expected some kind of dynamic scope (83.9%).
-
Some workers thought that record access would distribute over the field name expression.
-
Some workers ignored type annotations on functions.
-
Over the field and method questions we asked on objects, no worker expected Java’s semantics across all three.
These and other findings are explored in detail in our paper.
Crowdsourcing User Studies for Formal Methods
Tags: Verification, User Studies
Posted on 03 July 2017.For decades, we have neglected performing serious user studies of formal-methods tools. This is now starting to change. An earlier post introduces our new work in this area.
That study works with students in an upper-level class, who are a fairly good proxy for some developers (and are anyway an audience we have good access to). Unfortunately, student populations are problematic for several reasons:
-
There are only so many students in a class. There may not be enough to obtain statistical strength, especially on designs that require A/B testing and the like.
-
The class is offered only so often. It may take a whole year between studies. (This is a common problem in computing education research.)
-
As students progress through a class, it’s hard to “rewind” them and study their responses at an earlier stage in their learning.
And so on. It would be helpful if we could obtain large numbers of users quickly, relatively cheaply, and repeatedly.
This naturally suggests crowdsourcing. Unfortunately, the tasks we are examining involve using tools based on formal logic, not identifying birds or picking Web site colors (or solving CAPTCHAs…). That would seem to greatly limit the utility of crowd-workers on popular sites like Mechanical Turk.
In reality, this depends on how the problem is phrased. If we view it as “Can we find lots of Turkers with knowledge of Promela (or Alloy or …)?”, the answer is pretty negative. If, however, we can rework the problems somewhat so the question is “Can we get people to work on a puzzle?”, we can find many, many more workers. That is, sometimes the problem is one of vocabulary (and in particular, the use of specific formal methods languages) than of raw ability.
Concretely, we have taken the following steps:
-
Adapt problems from being questions about Alloy specifications to being phrased as logic “puzzles”.
-
Provide an initial training phase to make sure workers understand what we’re after.
-
Follow that with an evaluation phase to ensure that they “got the idea”. Only consider responses from those workers who score at a high enough threshold on evaluation.
-
Only then conduct the actual study.
Observe that even if we don’t want to trust the final results obtained from crowdsourcing, there are still uses for this process. Designing a good study requires several rounds of prototyping: even simple wording choices can have huge and unforeseen (negative) consequences. The more rounds we get to test a study, the better it will come out. Therefore, the crowd is useful at least to prototype and refine a study before unleashing it on a more qualified, harder-to-find audience — a group that, almost by definition, you do not want to waste on a first-round study prototype.
For more information, see our paper. We find fairly useful results using workers on Mechanical Turk. In many cases the findings there correspond with those we found with class students.
User Studies of Principled Model Finder Output
Tags: Verification, User Studies
Posted on 01 July 2017.For decades, formal-methods tools have largely been evaluated on their correctness, completeness, and mathematical foundations while side-stepping or hand-waving questions of usability. As a result, tools like model checkers, model finders, and proof assistants can require years of expertise to negotiate, leaving knowledgeable but uninitiated potential users at a loss. This state of affairs must change!
One class of formal tool, model finders, provides concrete instances of a specification, which can guide a user’s intuition or witness the failure of desired properties. But are the examples produced actually helpful? Which examples ought to be shown first? How should they be presented, and what supplementary information can aid comprehension? Indeed, could they even hinder understanding?
We’ve set out to answer these questions via disciplined user-studies. Where can we find participants for these studies? Ideally, we would survey experts. Unfortunately, it has been challenging to do so in the quantities needed for statistical power. As an alternative, we have begun to use formal methods students in Brown’s upper-level Logic for Systems class. The course begins with Alloy, a popular model-finding tool, so students are well suited to participate in basic studies. With this population, we have found some surprising results that call into question some intuitively appealing answers to (e.g.) the example-selection question.
For more information, see our paper.
Okay, that’s student populations. But there are only so many students in a class, and they take the class only so often, and it’s hard to “rewind” them to an earlier point in a course. Are there audiences we can use that don’t have these problems? Stay tuned for our next post.
The PerMission Store
Tags: Android, Permissions, Security, User Studies
Posted on 21 February 2017.This is Part 2 of our series on helping users manage app permissions. Click here to read Part 1.
As discussed in Part 1 of this series, one type of privacy decision users have to make is which app to install. Typically, when choosing an app, users pick from the first few apps that come up when they search a keyword in their app store, so the app store plays a big roll in which apps users download.
Unfortunately, most major app stores don’t help users make this decision in a privacy-minded way. Because these stores don’t factor privacy into their ranking, the top few search results probably aren’t the most privacy-friendly, so users are already picking from a problematic pool. Furthermore, users rely on information in the app store to choose from within that limited pool, and most app stores offer very little in the way of privacy information.
We’ve built a marketplace, the PerMission Store, that tackles both the ranking and user information concerns by adding one key component: permission-specific ratings. These are user ratings, much like the star ratings in the Google Play store, but they are specifically about an app’s permissions.1
To help users find more privacy friendly apps, the privacy ratings are incorporated into the PerMission Store’s ranking mechanism, so that apps with better privacy scores are more likely to appear in the top hits for a given search. (We also consider factors like the star rating in our ranking, so users are still getting useful apps.) So users are selecting from a more privacy-friendly pool of apps right off the bat.
Apps’ privacy ratings are also displayed in an easy-to-understand way, alongside other basic information like star rating and developer. This makes it straightforward for users to consider privacy along with other key factors when deciding which app to install.
Incorporating privacy into the store itself makes it so that choosing privacy-friendly apps is as a natural as choosing useful apps.
The PerMission Store is currently available as an Android app and can be found on Google Play.
A more detailed discussion of the PerMission Store can be found in Section 3.1 of our paper.
This is Part 2 of our series on helping users manage app permissions. Click here to read Part 1.
1: As a bootstrapping mechanism, we’ve collected rating for a couple thousand apps from Mechanical Turk. Ultimately, though, we expect the ratings to come from in-the-wild users.
Examining the Privacy Decisions Facing Users
Tags: Android, Permissions, Security, User Studies
Posted on 25 January 2017.This is Part 1 of our series on helping users manage app permissions. Click here to read Part 2.
It probably comes as no surprise to you that users are taking their privacy in their hands every time they install or use apps on their smartphones (or tablets, or watches, or cars, or…). This begs the question, what kinds of privacy decisions are users actually making? And how can we help them with those decisions?
At first blush, users can manage privacy in two ways: by choosing which apps to install, and by managing their apps’ permissions once they’ve installed them. For the first type of decision, users could benefit from a privacy-conscious app store to help them find more privacy-respecting apps. For the second type of decision, users would be better served by an assistant that helps them decide which permissions to grant.
Users can only making installation decisions when they actually have a meaningful choice between different apps. If you’re looking for Facebook, there really aren’t any other apps that you could use instead. This left us wondering if users ever have a meaningful choice between different apps, or whether they are generally looking for a specific app.
To explore this question, we surveyed Mechanical turk workers about 66 different Android apps, asking whether they thought the app could be replaced by a different one. The apps covered a broad range of functionality, from weather apps, to games, to financial services.
It turns out that apps vary greatly in their “replaceability,” and, rather than falling cleanly into “replaceable” and “unique” groups, they run along a spectrum between the two. At one end of the spectrum you have apps like Instagram, which less than 20% of workers felt could be replaced. On the other end of the spectrum are apps like Waze, which 100% of workers felt was replaceable. In the middle are apps whose replaceability depends on which features you’re interested in. For example, take an app like Strava, which lets you track your physical activity and compete with friends. If you only want to track yourself, it could be replaced by something like MapMyRide, but if you’re competing with friends who all use Strava, you’re pretty much stuck with Strava.
Regardless of exactly which apps fall where on the spectrum, though, there are replaceable apps, so users are making real decisions about which apps to install. And, for irreplaceable apps, they are also having to decide how to manage those apps’ permissions. These two types of decisions require two approaches to assisting users. A privacy-aware marketplace would aid users with installation decisions by helping them find more privacy-respecting apps, while a privacy assistant could help users manage their apps’ permissions.
Click here to read about our privacy-aware marketplace, the PerMission Store, and stay tuned for our upcoming post on a privacy assistant!
A more detailed discussion of this study can be found in Section 2 of our paper.
CS Student Work/Sleep Habits Revealed As Possibly Dangerously Normal
Tags: Education, User Studies
Posted on 14 June 2014. Written by Jesse Polhemus, and originally posted at the Brown CS blogImagine a first-year computer science concentrator (let’s call him Luis) e-mailing friends and family back home after a few weeks with Brown Computer Science (BrownCS). Everything he expected to be challenging is even tougher than anticipated: generative recursion, writing specifications instead of implementations, learning how to test his code instead of just writing it. Worst of all is the workload. On any given night, he’s averaging –this seems too cruel to be possible– no more than eight or nine hours of sleep.
Wait, what? Everyone knows that CS students don't get any sleep, so eight or nine hours is out of the question. Or is it? Recent findings from PhD student Joseph Gibbs Politz, adjunct professor Kathi Fisler, and professor Shriram Krishnamurthi analyze when students completed tasks in two different BrownCS classes, shedding interesting light on an age-old question: when do our students work, and when (if ever) do they sleep? The question calls to mind a popular conception of the computer scientist that Luis has likely seen in countless movies and books:
- Hours are late. (A recent poster to boardgames@lists.cs.brown.edu requests a 2 PM start time in order to avoid being “ridiculously early” for prospective players.)
- Sleep is minimal. BrownCS alumnus Andy Hertzfeld, writing about the early days of Apple Computer in Revolution in the Valley, describes the “gigantic bag of chocolate-covered espresso beans” and “medicinal quantities of caffeinated beverages” that allowed days of uninterrupted coding.
Part 1: Deadline Experiments
The story begins a few years before Luis’s arrival, when Shriram would routinely schedule his assignments to be due at the 11:00 AM start of class. “Students looked exhausted,” he remembers. “They were clearly staying up all night in order to complete the assignment just prior to class.”
Initially, he moved the deadline to 2:00 AM, figuring that night owl students would finish work in the early hours of the morning and then get some sleep. This was effective, but someone pointed out that it was unfair to other professors who taught earlier classes and were forced to deal with tired students who had finished Shriram’s assignment but not slept sufficiently.
“My final step,” he explains, “was to change deadlines to midnight. I also began penalizing late assignments on a 24-hour basis instead of an hourly one. This encourages students to get a full night’s sleep even if they miss a deadline.”
This was the situation when Luis arrives. The next task was to start measuring the results.
Part 2: Tracking Events
Shriram, Kathi, and Joe analyzed two of Shriram’s classes, CS 019 and CS 1730. For each class, Luis must submit test suites at any time he chooses, then read reviews of his work from fellow students. He then continues working on the solution, eventually producing a final implementation that must be submitted prior to the midnight deadline.
Part 3: Reality And Mythology
Given these parameters, what work and sleep patterns would you expect? We asked professor Tom Doeppner to reflect on Luis and share his experience of working closely with students as Director of Undergraduate Studies and Director of the Master’s Program. “Do students work late? I know I get e-mail from students at all hours of the night,” he says, “and I found out quickly that morning classes are unpopular, which is why I teach in the afternoon. Maybe it’s associated with age? I liked to work late when I was young, but I got out of the habit in my thirties.”
Asked about the possible mythologizing of late nights and sleeplessness, Tom tells a story from his own teaching: “Before we broke up CS 169 into two classes, the students had t-shirts made: ‘CS 169: Because There Are Only 168 Hours In A Week’. I think there’s definitely a widespread belief that you’re not really working hard unless you’re pulling multiple all-nighters.”
This doesn’t exactly sound like Luis’s sleep habits! Take a look at the graphs below to see how mythology and reality compare.
Part 4: Results And Conclusions
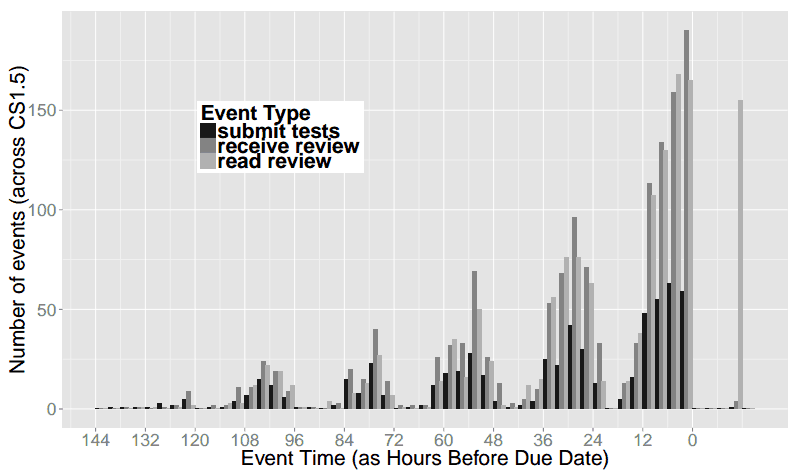
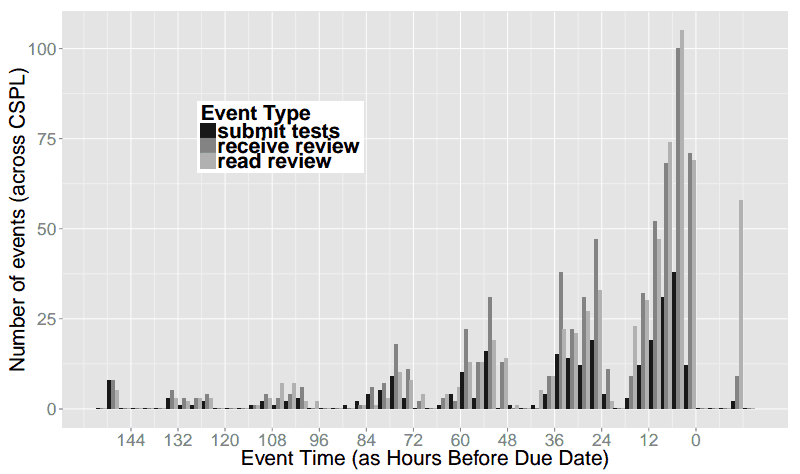
The graphs below depict test suite submissions, with time displayed in six-hour segments. For example, between 6 PM and the midnight deadline (“6-M”), 50 CS 173 students are submitting tests.
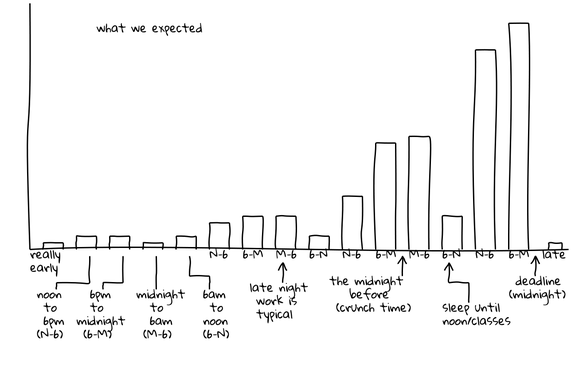
This graph is hypothetical, showing Joe, Kathi, and Shriram’s expectations for submission activity. They expected activity to be slow and increase steadily, culminating in frantic late-night activity just before the deadline. Generally taller “M-6” (midnight to 6 AM) bars indicate late-night work and a corresponding flurry of submissions, followed by generally shorter “6-N” (6 AM to noon) bars when students tried to get a few winks in. Cumulatively, these two trends depict the popular conception of the computer science student who favors late hours and perpetually lacks sleep.
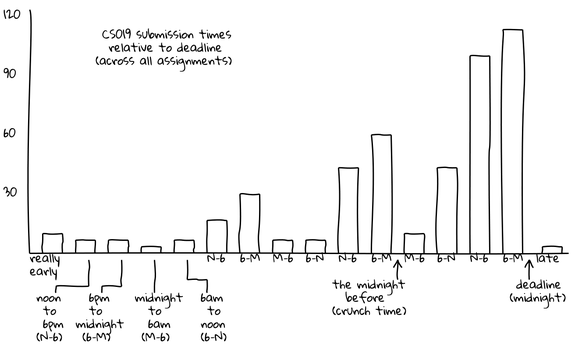
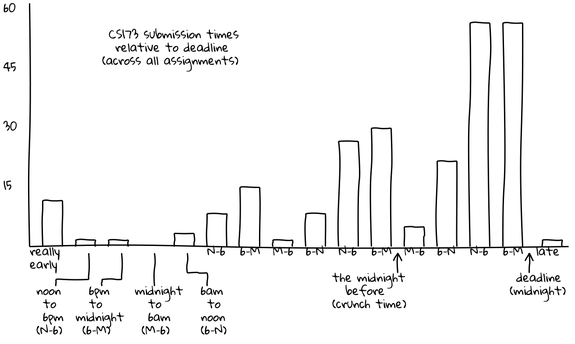
These graphs show actual submissions. As expected, activity generally increases over time and the last day contains the majority of submissions. However, unexpectedly, the “N-6” (noon to 6 PM) and “6-M” (6 PM to midnight) segments are universally the most active. In the case of the CS 173 graph, this morning segment contains far more submissions than any other of the day’s three segments. In both of these graphs, the “M-6” (midnight to 6 AM) segments are universally the least active, even the day the assignment is due. For example, the final segment of this type, which represents the last available span of early morning hours, is among the lowest of all segments, with only ten submissions occurring. In contrast, the corresponding “6-N” (6 AM to noon) shows more than four times as many submissions, suggesting that most students do their work before or after the pre-dawn hours but not during them.
“I wouldn’t have expected that,” Joe comments. “I think of the stories folks tell of when they work not lining up with that, in terms of staying up late and getting up just in time for class. Our students have something important to do at midnight other than work: they cut off their work before midnight and do something else. For the majority it’s probably sleep, but it could just be social time or other coursework. Either way, it’s an interesting across-the-board behavior.”
If word of these results gets out, what can Luis and his fellow students expect? “People will realize,” Shriram says, “that despite what everyone likes to claim, students even in challenging courses really are getting sleep, so it’s okay for them to, too.” Joe agrees: “There isn’t so much work in CS that you have to sacrifice normal sleeping hours for it.”
Luis, his family, and his well-rested classmates will undoubtedly be glad to hear it. The only question is: will their own descriptions of their work/sleep habits change to match reality, or are tales of hyper-caffeinated heroics too tempting to resist?
Appendix
The graphs above are simplified for readability, and aggregated into 6-hour increments. Below we include graphs of the raw data in 3-hour increments. This shows that there is some work going on from 12am-3am the night before assignments are due, but essentially nothing from 3am-6am.
In both of these classes, we were also performing experiments on code review, so the raw data includes when students read the code reviews they received, in addition to when they submitted their work. Since the review necessarily happens after submission, and the reading of the review after that, we see many more “late” events for reading reviews.
CS019 in 3-hour increments:
CS173 in 3-hour increments:
Social Ratings of Application Permissions (Part 4: The Goal)
Tags: Android, Permissions, Security, User Studies
Posted on 31 May 2013.(This is the fourth post in our series on Android application permissions. Click through for Part 1, Part 2, and Part 3.)
In this, the final post in our application permissions series, we'll discuss our trajectory for this research. Ultimately, we want to enable users to make informed decisions about the apps they install on their smartphones. Unfortunately, informed consent becomes difficult when you are asking users to make decisions in an area in which they have little expertise. Rating systems allow users to rely on the collective expertise of other users.
We intend to integrate permission ratings in to the app store in much the same way that functionality ratings are already there. This allows users to use visual cues they are already familiar with, such as the star rating that appears on the app page.

We may also wish to convey to users how each individual permission is rated. This finer-grained information gives users the ability to make decisions in line with their own priorities. For example, if users are particularly concerned about the integrity of their email accounts, an app that has a low-rated email access permission may be unacceptable to a user, even if the app receives otherwise high scores for permissions. We can again leverage well-known visual cues to convey this information, perhaps with meters similar to password meters, as seen in the mock-up image below.
There are a variety of other features we may want to incorporate into a permission rating system: allowing users to select favorite or trusted raters could enable them to rely on a particularly savvy relative or friend. Additionally, users could build a privacy profile, and view ratings only from like-minded users. Side-by-side comparisons of different apps' permissions rating could let users choose between similar apps more easily.
Giving users an easy way to investigate app permissions will allow them to make privacy a part of their decision-making process without requiring extra work or research on their part. This will improve the overall security of using a smartphone (or other permission-rich device), leaving users less vulnerable to unintended sharing of their personal data.
There's more! Click through to read Part 1, Part 2, and Part 3of the series!Social Ratings of Application Permissions (Part 3: Permissions Within a Domain)
Tags: Android, Permissions, Security, User Studies
Posted on 29 May 2013.(This is the third post in our series on Android application permissions. Click through for Part 1, Part 2, and Part 4.)
In a prior post we discussed the potential value for a social rating system for smartphone apps. Such a system would give non-expert users some information about apps before installing them. Ultimately, the goal of such a system would be to help users choose between different apps with similar functionality (for an app they need) or decide if the payoff of an app is worth the potential risk of installing it (for apps they want). Both of these use cases would require conscientious ratings of permissions.
We chose to study this issue by considering the range of scores that respondents give to permissions. If respondents were not considering the permissions carefully, we would expect the score to be uniform across different permissions. We examined the top five weather forecasting apps in the Android marketplace: The Weather Channel, WeatherBug Elite, Acer Life Weather, WeatherPro, and AccuWeather Platinum. We chose weather apps because they demonstrate a range of permission requirements; Acer Life Weather requires only four permissions while AccuWeather Platinum and WeatherBug Elite each require eleven permissions. We asked respondents to rate an app's individual permissions as either acceptable or unacceptable.
Our findings, which we present in detail below, show that users will rate application permissions conscientiously. In short, we found that although the approval ratings for each permission are all over 50%, they vary significantly from permission to permission. Approval ratings for individual permissions ranged from 58.8% positive (for “Modify or delete the contents of your USB storage”) to 82.5% (for “Find accounts on the device”). The table at the bottom of this post shows the percentage of users who considered a given permission acceptable. Because the ratings range from acceptable to unacceptable, they are likely representative of a given permissions' risk (unlike uniformly positive or negative reviews). This makes them effective tools for users in determining which applications they wish to install on their phones.
Meaningful ratings tell us that it is possible to build a rating system for application permissions to accompany the existing system for functionality. In our next post, we'll discuss what such a system might look like!
| Modify or delete the contents of your USB storage | 58.8 % |
| Send sticky broadcast | 60 % |
| Control vibration | 67.5 % |
| View Wi-Fi connections | 70 % |
| Read phone status and identity | 70 % |
| Test access to protected storage | 72.5 % |
| Google Play license check | 73.8 % |
| Run at startup | 75.8 % |
| Read Google service configuration | 76.3 % |
| Full network access | 76.5 % |
| Approximate location | 79 % |
| View network connections | 80.5 % |
| Find accounts on the device | 82.5 % |
Social Ratings of Application Permissions (Part 2: The Effect of Branding)
Tags: Android, Permissions, Security, User Studies
Posted on 22 May 2013.(This is the second post in this series. Click through for Part 1 and Part 3, and Part 4.)
In a prior post, we introduced our experiments investigating user ratings of smartphone application permissions. In this post we'll discuss the effect that branding has on users' evaluation of an app's permissions. Specifically, what effect does a brand name have on users' perceptions and ratings of an app?
We investigated this question using four well-known apps: Facebook, Gmail, Pandora Radio, and Angry Birds. Subjects were presented with a description of the app and its required permissions. We created surveys displaying the information presented to users in the Android app store, and asked users to rate the acceptability of the apps required permissions, and indicate whether they would install the app on their phone. Some of the subjects were presented with the true description of the app including its actual name, and the rest were presented with the same description, but with the well-known name replaced by a generic substitute. For example, Gmail was disguised as Mangogo Mail.
In the cases of Pandora and Angry Birds, there were no statistically significant differences in subjects' responses between the two conditions. However, there were significant differences in the responses for Gmail and Facebook.
For Gmail, participants rated the generic version's permissions as less acceptable and were less likely to install that version. For Facebook, however, participants rated the permissions for the generic version as less acceptable, but it had no effect on whether subjects would install the app. These findings raise interesting questions. Are the differences in responses caused by privacy considerations or other concerns, such as ability to access existing accounts? Why are people more willing to install a less secure social network than an insecure email client?
It is possible that people would be unwilling to install a generic email application because they want to be certain they could access their existing email or social network accounts. To separate access concerns from privacy concerns, we did a follow-up study in which we asked subjects to evaluate an app that was an interface over a brand-name app. In Gmail's case, for instance, subjects were presented with Gmore!, an app purporting to offer a smoother interaction with one's Gmail account.
Our findings for the interface apps was similar to the generic apps: for Facebook, subjects rated the permissions as less acceptable, but there was no effect on the likelihood of their installing the app; for Gmail, subjects rated the permissions as less acceptable and were less likely to install the app. In fact, the app that interfaced with Gmail had the lowest installation rate of any of the apps: just 47% of respondents would install the app, as opposed to 83% for brand-name Gmail, and 71% for generic Mangogo Mail. This suggests that subjects were concerned about the privacy of the apps, not just their functionality.
It is interesting that the app meant to interface with Facebook showed no significant difference in installation rates. Perhaps users are less concerned about the information on a social network than the information in their email, and see the potential consequences of installing an insecure social network as less dire than those associated with installing an insecure email client. This is just speculation, and this question requires further examination.
Overall, it seems that branding may play a role in how users perceive a given app's permissions, depending on the app. We would like to examine the nuances of this effect in greater detail. Why does this effect occur in some apps but not others? When does the different perception of permissions affect installation rates and why? These questions are exciting avenues for future research!
There's more! Click through to read Part 1, Part 3, and Part 4 of the series!Social Ratings of Application Permissions (Part 1: Some Basic Conditions)
Tags: Android, Permissions, Security, User Studies
Posted on 18 May 2013.(This is the first post in our series on Android application permissions. Click through for Part 2, Part 3, and Part 4.)
Smartphones obtain their power from allowing users to install arbitrary apps to customize the device’s behavior. However, with this versatility comes risk to security and privacy.
Different manufacturers have chosen to handle this problem in different ways. Android requires all applications to display their permissions to the user before being installed on the phone (then, once the user installs it, the application is free to use its permissions as it chooses). The Android approach allows users to make an informed decision about the applications they choose to install (and to do so at installation time, not in the midst of a critical task), but making this decision can be overwhelming, especially for non-expert users who may not even know what a given permission means. Many applications present a large number of permissions to users, and its not always clear why an application requires certain permissions. This requires users to gamble on how dangerous they expect a given application to be.
One way to help users is to rely on the expertise or experiences of other users, an approach that is already common in online marketplaces. Indeed, the Android application marketplace already allows users to rate applications. However, these reviews are meant to rate the application as a whole, and are not specific to the permissions required by the application. Therefore the overall star rating of an application is largely indicative of users’ opinions of the functionality of an application, not the security of the application. When users do offer opinions about security and privacy, as they sometimes do, these views are buried in text and lost unless the user reads all the comments.
Our goal is to make security and privacy ratings first-class members of the marketplace rating system. We have begun working on this problem, and will explain our preliminary results in this and a few more blog posts. All the experiments below were conducted on Mechanical Turk.
In this post, we examine the following questions:
- Will people even rate the app's permissions? Even when there are lots of permissions to rate?
- Does users’ willingness to install a given application change depending on when they are asked to make this choice - before they’ve reflected on the individual permissions or after?
- Do their ratings differ depending on how they were told about the app?
We created surveys that mirrored the data provided by the Android installer (and as visible on the Google Play Web site). We examined four applications: Facebook, Gmail, Pandora, and Angry Birds. We asked respondents to rate the acceptability of the permissions required by each application and state whether they would install the application if they needed an app with that functionality.
In the first condition, respondents were asked whether they would install the app before
or after they were asked to rate the app’s individual permissions. In this case, only Angry
Birds showed any distinction between the two conditions: Respondents were more likely to install
the application if the were asked after they were asked to rate the permissions.
Overall, however, the effect of asking before or after was very small; this is good, because it
suggests that in the future we can ignore the overall rating, and it also offers some flexibility for
interface design.
The second condition was how the subject heard about the app (or rather, how they were asked to
imagine they heard about it). Subjects were asked to imagine either that the app had been recommended
to them by a colleague, that the app was a top “featured app” in the app store, or that the
app was a top rated app in the app store. In this case, only Facebook showed any interesting results:
respondents were less likely to install the application if it had been recommended by a colleague than
if it was featured or highly rated. This result is particularly odd given that, due to the network effect
of an app like Facebook, we would expect the app to be more valuable if friends or colleagues also use it.
We would like to study this phenomenon further.
Again, though this finding may be interesting, the fact that it has so little impact means we can set this
condition aside in our future studies, thus narrowing the search space of factors that do affect how users
rate permissions.
That concludes this first post on this topic. In future posts we’ll examine the effect of branding, and present detailed ratings of apps in one particular domain. Stay tuned!
There's more! Click through to read Part 2, Part 3, and Part 4 of the series!