The Brown PLT Blog

Articles by tag: Software-Defined Networking
Tierless Programming for SDNs: Verification
Tierless Programming for SDNs: Optimality
Tierless Programming for SDNs: Events
Tierless Programming for Software-Defined Networks
Tierless Programming for SDNs: Differential Analysis
Tags: Flowlog, Programming Languages, Software-Defined Networking, Verification
Posted on 02 June 2015.
This post is part of our series about tierless network programming with Flowlog:
Part 1: Tierless Programming
Part 2: Interfacing with External Events
Part 3: Optimality
Part 4: Verification
Part 5: Differential Analysis
Verification is a powerful way to make sure a program meets expectations, but what if those expectations aren't written down, or the user lacks the expertise to write formal properties? Flowlog supports a powerful form of property-free analysis: program differencing.
When we make a program change, usually we're starting from a version that "works". We'd like to transfer what confidence we had in the original version to the new version, plus confirm our intuition about the changes. In other words, even if the original program had bugs, we'd like to at least confirm that the edit doesn't introduce any new ones.
Of course, taking the syntactic difference of two programs is easy — just use diff! — but usually that's not good enough. What we want is the behavioral, or semantic difference. Flowlog provides semantic differencing via Alloy, similarly to how it does property checking. We call Flowlog's differencing engine Chimp (short for Change-impact).
Differences in Output and State Transitions
Chimp translates both the old (prog1) and new (prog2) versions to Alloy, then supports asking questions like: Will the two versions ever handle packets differently? More generally, we can ask Chimp whether the program's output behavior ever differs: does there exist some program state and input event such that, in that state, the two programs will disagree on output?
pred changePolicyOut[st: State, ev: Event] {
some out: Event |
prog1/outpolicy[st,ev,out] && not prog2/outpolicy[st,ev,out] ||
prog2/outpolicy[st,ev,out] && not prog1/outpolicy[st,ev,out]
}
Any time one program issues an output event that the other doesn't, Chimp
displays an Alloy scenario.
We might also ask: When can the programs change state differently? Similarly to changePolicyOut above, Chimp defines changeStateTransition[st: State, ev: Event] as matching any of the following for each table T in the program:
some x0, ..., xn: univ |
prog1/afterEvent_T[prestate, ev, x0, ..., xn] &&
not prog2/afterEvent_T[prestate, ev, x0, ..., xn] ||
prog2/afterEvent_T[prestate, ev, x0, ..., xn] &&
not prog1/afterEvent_T[prestate, ev, x0, ..., xn]
Recall that afterEvent_T keeps track of when each tuple is in the table T after an event is processed.
Refining Differential Analysis
The two predicates above are both built into Chimp. Using them as a starting point, users can ask pointed questions about the effects of the change. For instance, will any TCP packets be handled differently? Just search for a pre-state and a TCP packet that the programs disagree on:
some prestate: State, p: EVtcp_acket | changePolicyOut[prestate, p]This lets users explore the consequences of their change without any formal guidance except their intuition about what the change should do.
Reachability
So far, these queries show scenarios where the programs differ, taking into consideration all potential inputs and starting states; this includes potentially unreachable starting states. We could, for instance, have two programs that behave differently if a table is populated (resulting in a non-empty semantic diff!) yet never actually insert rows into that table. Chimp provides optional reachability-checking to counter this, although users must cap the length of system traces being searched.
Schema Clashes
Suppose that we want to modify the original source-tracking example to keep track of flows by source and destination, rather than just source addresses. Now instead of one column:
TABLE seen(macaddr);the seen table has two columns:
TABLE seen(macaddr, macaddr);
This poses a challenge for Chimp; what shape should the seen table be? If Chimp finds a scenario, should it show a seen table with one or two columns? We call this situation a schema clash, and Chimp addresses it by creating two separate tables in the prestate: one with one column (used by the first program) and another with two columns (used by the second program).
Doing this causes a new issue: Chimp searches for arbitrary states that satisfy the change-impact predicates. Since there is no constraint between the values of the two tables, Chimp might return a scenario where (say) the first seen table is empty, but the second contains tuples!
This doesn't match our intuition for the change: we expect that for every source in the first table, there is a source-destination pair in the second table, and vice versa. We can add this constraint to Chimp and filter the scenarios it shows us, but first, we should ask whether that constraint actually reflects the behavior of the two programs.
Differential Properties
Since it's based on Flowlog's verification framework, Chimp allows us to check properties stated over multiple programs. Our expecation above, stated in Alloy for an arbitrary state s, is:
all src: Macaddr | src in s.seen1 iff some dst: Macaddr | src->dst in s.seen2
Let's check that this condition holds for all reachable states. We'll proceed inductively. The condition holds trivially at the starting (empty) state; so we only need to show that it is preserved as the program transitions. We search for a counterexample:
some prestate: State, ev: Event | {
// prestate satisfies the condition
all src: Macaddr | src in prestate.seen_1 iff
some dst: Macaddr | src->dst in prestate.seen_2
// poststate does not
some src: Macaddr |
(prog1/afterEvent_seen_1[prestate,ev,src] and
all dst: Macaddr | not prog2/afterEvent_seen_2[prestate,ev,src,dst])
||
(not prog1/afterEvent_seen_1[prestate,ev,src] and
some dst: Macaddr | prog2/afterEvent_seen_2[prestate,ev,src,dst])
}
Chimp finds no counterexample. Unfortunately, Chimp can't guarantee that this isn't a false negative; the query falls outside the class where Chimp can guarantee a complete search. Nevertheless, the lack of counterexample serves to increase our confidence that the change respects our intent.
After adding the constraint that, for every source in the first table, there is a source-destination pair in the second table, Chimp shows us that the new program will change the state (to add a new destination) even if the source is already in seen.
Further Reading
Chimp supports more features than discussed here; for instance, Chimp can compare the behavior of any number of program versions, but a two-program comparison is the most common. You can read more about Chimp in our paper.
Tierless Programming for SDNs: Verification
Tags: Flowlog, Programming Languages, Software-Defined Networking, Verification
Posted on 17 April 2015.
This post is part of our series about tierless network programming with Flowlog:
Part 1: Tierless Programming
Part 2: Interfacing with External Events
Part 3: Optimality
Part 4: Verification
Part 5: Differential Analysis
The last post said what it means for Flowlog's compiler to be optimal, which prevents certain bugs from ever occurring. But what about the program itself? Flowlog has built-in features to help verify program correctness, independent of how the network is set up.
To see Flowlog's program analysis in action, let's first expand our watchlist program a bit more. Before, we just flooded packets for demo purposes:
DO forward(new) WHERE
new.locPt != p.locPt;
Now we'll do something a bit smarter. We'll make the program learn which ports
lead to which hosts, and use that knowledge to avoid flooding when possible (this
is often called a "learning switch"):
TABLE learned(switchid, portid, macaddr);
ON packet(pkt):
INSERT (pkt.locSw, pkt.locPt, pkt.dlSrc) INTO learned;
DO forward(new) WHERE
learned(pkt.locSw, new.locPt, pkt.dlDst);
OR
(NOT learned(pkt.locSw, ANY, pkt.dlDst) AND
pkt.locPt != new.locPt);
The learned table stores knowledge about where addresses have been
seen on the network. If a packet arrives with a destination the switch has
seen before as a source, there's no need to flood! While this program is still
fairly naive (it will fail if the network has cycles in it) it's complex
enough to have a few interesting properties we'd like to check. For instance,
if the learned table ever holds multiple ports for the same switch
and address, the program will end up sending multiple copies of the same
packet. But can the program ever end up in such a state? Since the initial,
startup state is empty, this amounts to checking:
Verifying Flowlog
Each Flowlog rule defines part of an event-handling function saying how the system should react to each packet seen. Rules compile to logical implications that Flowlog's runtime interprets whenever a packet arrives.
Alloy is a tool for analyzing relational logic specifications. Since Flowlog rules compile to logic, it's easy to describe in Alloy how Flowlog programs behave. In fact, Flowlog can automatically generate Alloy specifications that describe when and how the program takes actions or changes its state.For example, omitting some Alloy-language foibles for clarity, here's how Flowlog describes our program's forwarding behavior in Alloy.
pred forward[st: State, p: EVpacket, new: EVpacket] {
// Case 1: known destination
(p.locSw->new.locPt->p.dlDst) in learned and
(p.locSw->new.locPt) in switchHasPort and ...)
or
// Case 2: unknown destination
(all apt: Portid | (p.locSw->apt->p.dlDst) not in learned and
new.locPt != p.locPt and
(p.locSw->new.locPt) in switchHasPort and ...)
}
An Alloy predicate is either true or false for a given input. This one says
whether, in a given state st, an arbitrary packet p will be
forwarded as a new packet new (containing the output port and any
header modifications).
It combines both forwarding rules together to construct a logical definition
of forwarding behavior, rather than just a one-way implication (as in the case
of individual rules).
The automatically generated specification also contains other predicates that say how and when the controller's state will change. For instance, afterEvent_learned, which says when a given entry will be present in learned after the controller processes a packet. An afterEvent predicate is automatically defined for every state table in the program.
Using afterEvent_Learned, we can verify our goal: that whenever an event ev arrives, the program will never add a second entry (sw, pt2,addr) to learned:
assert FunctionalLearned {
all pre: State, ev: Event |
all sw: Switchid, addr: Macaddr, pt1, pt2: Portid |
(not (sw->pt1->addr in pre.learned) or
not (sw->pt2->addr in pre.learned)) and
afterEvent_learned[pre, ev, sw, pt1, addr] and
afterEvent_learned[pre, ev, sw, pt2, addr] implies pt1 = pt2
}
Alloy finds a counterexample scenario (in under a second):
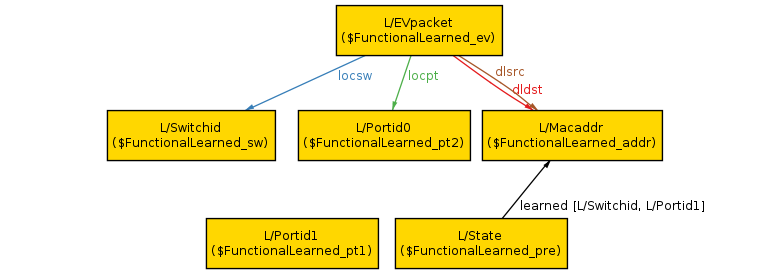
The scenario shows an arbitrary packet (L/EVpacket; the L/ prefix can be ignored) arriving at port 1 (L/Portid1) on an arbitrary switch (L/Switchid). The packet has the same source and destination MAC address (L/Macaddr). Before the packet arrived, the controller state had a single row in its learned table; it had previously learned that L/Macaddr can be reached out port 0 (L/Portid1). Since the packet is from the same address, but a different port, it will cause the controller to add a second row to its learned table, violating our property.
This situation isn't unusual if hosts are mobile, like laptops on a campus network are. To fix this issue, we add a rule that removes obsolete mappings from the table:
DELETE (pkt.locSw, pt, pkt.dlSrc) FROM learned WHERE not pt = pkt.locPt;Alloy confirms that the property holds of the modified program. We now know that any reachable state of our program is valid.
Verification Completeness
Alloy does bounded verification: along with properties to check, we provide concrete bounds for each datatype. We might say to check up to to 3 switches, 4 IP addresses, and so on. So although Alloy never returns a false positive, it can in general produce false negatives, because it searches for counterexamples only up to the given bounds. Fortunately, for many useful properties, we can compute and assert a sufficient bound. In the property we checked above, a counterexample needs only 1 State (to represent the program's pre-state) and 1 Event (the arriving packet), plus room for its contents (2 Macaddrs for source and destination, etc.), along with 1 Switchid, 2 Portids and 1 Macaddr to cover the possibly-conflicted entries in the state. So when Alloy says that the new program satisfies our property, we can trust it.
Benefits of Tierlessness
Suppose we enhanced the POX version of this program (Part 1) to learn ports in the same way, and then wanted to check the same property. Since the POX program explicitly manages flow-table rules, and the property involves a mixture of packet-handling (what is sent up to the controller?) and controller logic (how is the state updated?), checking the POX program would mean accounting for those rules and how the controller updates them over time. This isn't necessary for the Flowlog version, because rule updates are all handled optimally by the runtime. This means that property checking is simpler: there's no multi-tiered model of rule updates, just a model of the program's behavior.
You can read more about Flowlog's analysis support in our paper.
In the next post, we'll finish up this sequence on Flowlog by reasoning about behavioral differences between multiple versions of the same program.
Tierless Programming for SDNs: Optimality
Tags: Flowlog, Programming Languages, Software-Defined Networking, Verification
Posted on 13 April 2015.
This post is part of our series about tierless network programming with Flowlog:
Part 1: Tierless Programming
Part 2: Interfacing with External Events
Part 3: Optimality
Part 4: Verification
Part 5: Differential Analysis
Since packets can trigger controller-state updates and event output, you might wonder exactly which packets a Flowlog controller needs to see. For instance, a packet without a source in the watchlist will never alter the controller's state. Does such a packet need to grace the controller at all? The answer is no. In fact, there are only three conditions under which switch rules do not suffice, and the controller must be involved in packet-handling:
- when the packet will cause a change in controller state;
- when the packet will cause the controller to send an event; and
- when the packet must be modified in ways that OpenFlow 1.0 does not support on switches.
Flowlog's compiler ensures the controller sees packets if and only if one of these holds; the compiler is therefore optimal with respect to this list. To achieve this, the compiler analyzes every packet-triggered statement in the program. For instance, the INSERT statement above will only change the state for packets with a source in the watchlist (a condition made explicit in the WHERE clause) and without a source in the seen table (implicit in Flowlog's logical semantics for INSERT). Only if both of these conditions are met will the controller see a packet. An optimal compiler prevents certain kinds of bugs from occurring: the controller program will never miss packets that will affect its state, and it will never receive packets it doesn't need.
You can read more about Flowlog in our paper.
In the next post, we'll look at Flowlog's built-in verification support.
Tierless Programming for SDNs: Events
Tags: Flowlog, Programming Languages, Software-Defined Networking, Verification
Posted on 01 March 2015.
This post is part of our series about tierless network programming with Flowlog:
Part 1: Tierless Programming
Part 2: Interfacing with External Events
Part 3: Optimality
Part 4: Verification
Part 5: Differential Analysis
The last post introduced Flowlog, a tierless language for SDN controller programming. You might be wondering, "What can I write in Flowlog? How expressive is it?" To support both its proactive compiler and automated program analysis (more on this in the next post) we deliberately limited Flowlog's expressive power. There are no loops in the language, and no recursion. Instead of trying to be universally expressive, Flowlog embraces the fact that most programs don't run in a vacuum. A controller may need to interact with other services, and developers may wish to re-use pre-existing code. To enable this, Flowlog programs can call out to non-Flowlog libraries. The runtime uses standard RPCs (Thrift) for inter-process communication, so existing programs can be quickly wrapped to communicate with Flowlog. Much like how Flowlog abstracts out switch-rule updates, it also hides the details of inter-process communcation. To see this, let's enhance the address-logger application with a watch-list that external programs can add to. We need a new table ("watchlist"), populated by arriving "watchplease" events that populate the table. Finally, we make sure only watched addresses are logged:
TABLE seen(macaddr);
TABLE watchlist(macaddr);
EVENT watchplease = {target: macaddr};
ON watchplease(w):
INSERT (w.target) INTO watchlist;
ON packet(p):
INSERT (p.dlSrc) INTO seen WHERE
watchlist(p.dlSrc);
DO forward(new) WHERE
new.locPt != p.locPt;
When the program receives a watchplease event (sent via RPC from an external
program) it adds the appropriate address to its watchlist.
Sending Events
Flowlog programs can also send events. Suppose we want to notify some other process when a watchlisted address is seen, and the process is listening on TCP port 20000. We just declare a named pipe that carries notifications to that port:
EVENT sawaddress = {addr: macaddr};
OUTGOING sendaddress(sawaddress) THEN
SEND TO 127.0.0.1:20000;
and then write a notification to that pipe for appropriate packets:
ON packet(p) WHERE watchlist(p.dlSrc): DO sendaddress(s) WHERE s.addr = p.dlSrc;
Synchronous Communication
The event system supports asynchronous communication, but Flowlog also allows synchronous queries to external programs. It does this with a remote state abstraction. If we wanted to manage the watchlist remotely, rather than writingTABLE watchlist(macaddr);we would write:
REMOTE TABLE watchlist(macaddr) FROM watchlist AT 127.0.0.1 20000 TIMEOUT 10 seconds;which tells Flowlog it can obtain the current list by sending queries to port 20000. Since these queries are managed behind the scenes, the program doesn't need to change—as far as the programmer is concerned, a table is a table. Finally, the timeout says that Flowlog can cache prior results for 10 seconds.
Interfacing External Programs with Flowlog
Flowlog can interface with code in any language that supports Thrift RPC (including C++, Java, OCaml, and many others). To interact with Flowlog, one only needs to implement the interface Flowlog requires: a function that accepts notifications and a function that responds to queries. Other functions may also (optionally) send notifications. Thrift's library handles the rest.You can read more about Flowlog's events in our paper.
In the next post, we'll look at what it means for Flowlog's compiler to be optimal.
Tierless Programming for Software-Defined Networks
Tags: Flowlog, Programming Languages, Software-Defined Networking, Verification
Posted on 30 September 2014.
This post is part of our series about tierless network programming with Flowlog:
Part 1: Tierless Programming
Part 2: Interfacing with External Events
Part 3: Optimality
Part 4: Verification
Part 5: Differential Analysis
Network devices like switches and routers update their behavior in real-time. For instance, a router may change how it forwards traffic to address an outage or congestion. In a traditional network, devices use distributed protocols to decide on mutually consistent behavior, but Software-Defined Networks (SDN) operate differently. Switches are no longer fully autonomous agents, but instead receive instructions from logically centralized controller applications running on separate hardware. Since these applications can be arbitrary programs, SDN operators gain tremendous flexibility in customizing their network.
The most popular SDN standard in current use is OpenFlow. With OpenFlow, Controller applications install persistent forwarding rules on the switches that match on packet header fields and list actions to take on a match. These actions can include header modifications, forwarding, and even sending packets to the controller for further evaluation. When a packet arrives without a matching rule installed, the switch defaults to sending the packet to the controller for instructions.
Let's write a small controller application. It should (1) record the addresses of machines sending packets on the network and (2) cause each switch to forward traffic by flooding (i.e., sending out on all ports except the arrival port). This is simple enough to write in POX, a controller platform for Python. The core of this program is a function that reacts to packets as they arrive at the controller (we have removed some boilerplate and initialization):
def _handle_PacketIn (self, event):
packet = event.parsed
def install_nomore ():
msg = of.ofp_flow_mod()
msg.match = of.ofp_match(dl_src = packet.src)
msg.buffer_id = event.ofp.buffer_id
msg.actions.append(of.ofp_action_output(port = of.OFPP_FLOOD))
self.connection.send(msg)
def do_flood ():
msg = of.ofp_packet_out()
msg.actions.append(of.ofp_action_output(port = of.OFPP_FLOOD))
msg.data = event.ofp
msg.buffer_id = None
msg.in_port = event.port
self.connection.send(msg)
self.seenTable.add(packet.src)
install_nomore()
do_flood()
First, the controller records the packet's source in its internal table. Next, the install_nomore function adds a rule to the switch saying that packets with this source should be flooded. Once the rule is installed, the switch will not send packets with the same source to the controller again. Finally, the do_flood function sends a reply telling the switch to flood the packet.
This style of programming may remind you of the standard three-tier web-programming architecture. Much like a web program generates JavaScript or SQL strings, controller programs produce new switch rules in real-time. One major difference is that switch rules are much less expressive than JavaScript, which means that less computation can be delegated to the switches. A bug in a controller program can throw the entire network's behavior off. But it's easy to introduce bugs when every program produces switch rules in real-time, effectively requiring its own mini-compiler!
SDN Programming Without Tiers
We've been working on a tierless language for SDN controllers: Flowlog. In Flowlog, you write programs as if the controller sees every packet, and never have to worry about the underlying switch rules. This means that some common bugs in controller/switch interaction can never occur, but it also means that the programming experience is simpler. In Flowlog, our single-switch address-monitoring program is just:
TABLE seen(macaddr); ON ip_packet(p): INSERT (p.dlSrc) INTO seen; DO forward(new) WHERE new.locPt != p.locPt;
The first line declares a one-column database table, "seen". Line 2 says that the following two lines are triggered by IP packets. Line 3 adds those packets' source addresses to the table, and line 4 sends the packets out all other ports.
As soon as this program runs, the Flowlog runtime proactively installs switch rules to match the current controller state and automatically ensures consistency. As the controller sees more addresses, the switch sends fewer packets back to the controller—but this is entirely transparent to the programmer, whose job is simplified by the abstraction of an all-seeing controller.
Examples and Further Reading
Flowlog is good for more than just toy examples. We've used Flowlog for many different network applications: ARP-caching, network address translation, and even mediating discovery and content-streaming for devices like Apple TVs. You can read more about Flowlog and Flowlog applications in our paper.
The next post talks more about what you can use Flowlog to write, and also see how Flowlog allows programs to call out to external libraries in other languages.