The Brown PLT Blog

The Essence of JavaScript
Tags: JavaScript, Programming Languages, Semantics
Posted on 29 September 2011.Back in 2008, the group decided to really understand JavaScript. Arjun had built a static analysis for JavaScript from scratch. Being the honest chap that he is, he was forced to put the following caveat into the paper:
"We would like to formally prove that our analysis is sound. A sound analysis would guarantee that our tool will never raise a false alarm, an imporant usability concern. However, a proof of soundness would require a formal semantics for JavaScript and the DOM in browsers, and this does not exist."
A "formal semantics for JavaScript [...] does not exist"? Didn't he know
about the official documents on such matters, the ECMAScript standard?
ECMAScript 3rd edition, the standard at the time, was around 180 pages long,
written in prose and pseudocode. Reading it didn't help much. It includes
gems such as this description of the switch statement:
1. Let A be the list of CaseClause items in the first
CaseClauses, in source text order.
2. For the next CaseClause in A, evaluate CaseClause. If there is
no such CaseClause, go to step 7.
3. If input is not equal to Result(2), as defined by the !==
operator, go to step 2.
4. Evaluate the StatementList of this CaseClause.
5. If Result(4) is an abrupt completion then return Result(4).
6. Go to step 13.
7. Let B be the list of CaseClause items in the second
CaseClauses, in source text order.
8. For the next CaseClause in B, evaluate CaseClause. If there is
no such CaseClause, go to step 15.
9. If input is not equal to Result(8), as defined by the !==
operator, go to step 8.
10. Evaluate the StatementList of this CaseClause.
11. If Result(10) is an abrupt completion then return Result(10).
12. Go to step 18.
...
And this is just one of 180 pages of lesser or greater eloquence. With this as his formal reference, it's no wonder Arjun had a hard time making soundness claims.
Around the same time, Ankur Taly, Sergio Maffeis, and John Mitchell noticed the same problem. They presented a formal semantics for JavaScript in their APLAS 2008 paper. You can find their semantics here, and it is a truly staggering effort, running for 40+ pages (that's at least four times easier to understand!). However, we weren't quite satisfied. Their semantics formalizes the ECMAScript specification as written, and therefore inherits some of its weirdness, such as heap-allocated "scope objects", implicit coercions, etc. We still couldn't build tools over it, and were unwilling to do 40-page case analyses for proofs. Leo Meyerovich, peon extraordinaire and friend of the blog, felt the same:
"Challenging current attempts to analyze JavaScript, there is no formal semantics realistic enough to include many of the attack vectors we have discussed yet structured and tractable enough that anyone who is not the inventor has been able to use; formal proofs are therefore beyond the scope of this work."
How To Tackle JavaScript: The PLT Way
We decided to start smaller. In the fall of 2009, Arjun wrote down a semantics for the "core" of JavaScript that fits on just three pages (that's 60 times easier to understand!). This is great programming languages research—we defined away the hairy parts of the problem and focused on a small core that was amenable to proof. For these proofs, we could assume the existence of a trivial desugaring that maps real JavaScript programs into programs in the core semantics, which Arjun dubbed λJS.
Things were looking great until one night Arjun had a few too many glasses of wine and decided to implement desugaring. Along with Claudiu Saftoiu, he wrote a thousand lines of Haskell that turns JavaScript programs into λJS programs. Even worse, they implemented an interpreter for λJS, so the resulting programs actually run. They had therefore produced a JavaScript runtime.
Believe it or not, there are other groups in the business of creating JavaScript runtimes, namely Google, Mozilla, Microsoft, and a few more. And since they care about the correctness of their implementations, they have actual test suites. Which Arjun's system could run, and give answers for, that may or may not be the right ones:
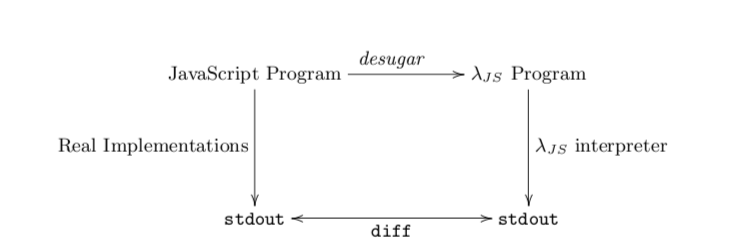
As it turns out, Arjun and Claudiu did a pretty good job. λJS agrees with Mozilla SpiderMonkey on a few thousand lines of tests. We say "agreed" and not "passed" because SpiderMonkey fails some of its own tests. Without any other standard of correctness, λJS strives for bug-compatibility with SpiderMonkey on those tests.
Building on λJS
λJS is discussed in our ECOOP paper, but it's the work built on λJS that's most interesting. We've built the following systems ourselves:
- A type-checker for JavaScript that employs a novel mix of type-checking and flow analysis ("flow typing"), discussed in our ESOP 2011 paper, and
- An extension to the above type-checker to verify ADsafe, as discussed in our USENIX Security 2011 paper.
- David van Horn and Matt Might use λJS to build an analytic framework for JavaScript,
- Rodolfo Toledo and Éric Tanter use λJS to specify aspects for JavaScript,
- IBEX, from Microsoft Research, uses λJS for its JavaScript backend to produce verified Web browser extensions, and
- Others have a secret reimplementation of λJS in Java. We are now enterprise-ready.
Want to use λJS to write JavaScript tools? Check out our software and let us know what you think!
Coming up next: The latest version of JavaScript, ECMAScript 5th ed.,
is vastly improved. We've nearly finished updating our JavaScript semantics to
match ECMAScript 5th ed. Our new semantics uses the official ECMAScript test
suite and tackles problems, such as eval, that the original
λJS elided. We'll talk about it next time. Update:
We've written about our update, dubbed S5, its semantics for accessors,
and a particularly interesting
example.