The Brown PLT Blog

Essentials of Garbage Collection
Tag: Education
Posted on 19 February 2013.How do we teach students the essential ideas behind garbage collection?
A garbage collector (GC) implementation must address many overlapping concerns. There are algorithmic decisions, e.g., the GC algorithm to use; there are representation choices, e.g, the layout of the stack; and there are assumptions about the language, e.g., unforgeable pointers. These choices, and more, affect each other and make it very difficult for students to get off the ground.
Programming language implementations can be similarly complex. However, over the years, starting from McCarthy's seminal paper, we've found it invaluable to write definitional interpreters for simple core languages, that allow us to easily explore the consequences of language design. What is the equivalent for garbage collectors?
Testing and Curricular Dependencies
Testing is important for any program, and is doubly so for a garbage collector, which must correctly deal with complex inputs (i.e., programs!). Furthermore, correctness itself is subtle: besides being efficient, a collector must terminate, be sound (not collect non-garbage), be effective (actually collect enough true garbage), and preserve the essential structure of live data: e.g., given a cyclic datum, it must terminate, and given data with sharing, it must preserve the sharing-structure and not duplicate data.
For instructors, a further concern is the number of deep, curricular dependencies that teaching GC normally incurs. In a course where students already learn compilers and interpreters, it is possible (but hard) to teach GC. However, GC should be teachable in several contexts, such as a systems course, an architecture course, or even as a cool application of graph algorithms. Eliminating GC's curricular dependencies is thus valuable.
Even in courses that have student implement compilers or interpreters, testing a garbage collector is very hard. A test-case is a program that exercises the collector in an interesting way. Good tests require complex programs, and complex programs require a rich programming language. In courses, students tend to write compilers and interpreters for simple, core languages and are thus stuck writing correspondingly simple programs. Worse, some important GC features, such as the treatment of cycles and first-class functions, are impossible to test unless the programming language being implemented has the necessary features. Growing a core language for the sake of testing GC would be a case of the tail wagging the dog.
In short, we would like a pedagogic framework where:
- Students can test their collectors using a full-blown programming language, instead of a stilted core language, and
- Students can experiment with different GC algorithms and data-representations, without learning to implement languages.
The Key Idea
Over the past few years, we've built a framework for teaching garbage collection, first started by former Brown PhD student Greg Cooper.
Consider the following Racket program, which would make a great test-case for a garbage collector (with a suitably small heap):
#lang racket
(define (map f l)
(cond
[(empty? l) empty]
[(cons? l) (cons (f (first l))
(map f (rest l)))]))
(map (lambda (x) (+ x 1)) (list 1 2 3))
As written, Racket's native garbage collector allocates the closure
created by lambda and the lists created by cons
and list. But, what if we could route these calls to a
student-written collector and have it manage memory instead?
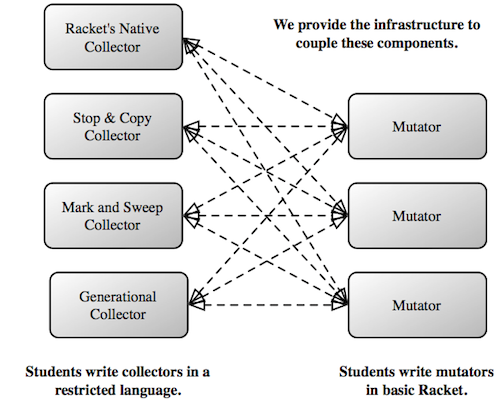
Greg made the following simple observation. Why are these values being managed by the Racket memory system? That's because the bindings for lambda, cons and list (and other procedures and values) are provided by #lang racket. Instead, suppose that with just one change, we could swap in a student-written collector:
#lang plai/mutator (allocator-setup "my-mark-and-sweep.rkt" 30)Using the magic of Racket's modules and macros, #lang plai/mutator maps memory-allocating procedures to student-written functions. The student designates a module, such as my-mark-and-sweep that exports a small, prescribed interface for memory allocation. That module allocates values in a private heap and runs its own GC algorithm when it runs out of space. In our framework, the heap size is a parameter that is trivial to change. The program above selects a heap size of 30, which is small enough to trigger several GC cycles.
We've designed the framework so that students can easily swap in different collectors, change the size of the heap, and even use Racket's native collector, as a sanity check.
Discovering GC Roots
Routing primitive procedures and constants is only half the story. A collector also needs to inspect and modify the program stack, which holds the roots of garbage collection. Since we allow students to write programs in Racket, the stack is just the Racket stack, which is not open for reflection. Therefore, we must also transform the program to expose the contents of the stack.
Our framework automatically transforms Racket programs to A-normal form, which names all intermediate expressions in each activation record. Unlike other transformations, say CPS, A-normalization preserves stack-layout. This makes it easy for students to co-debug their programs and collectors using the built-in DrRacket debugger.
In addition to inspecting individual activation records, a collector also needs to traverse the entire list of records on the stack. We maintain this list on the stack itself using Racket's continuation marks. Notably, continuation marks preserve tail-calls, so the semantics of Racket programs are unchanged.
The combination of A-normalization and continuation marks gives us a key technical advantage. In their absence, we would have to manually convert programs to continuation-passing style (followed by defunctionalization) to obtain roots. Not only would these be onerous curricular dependencies, but they would make debugging very hard.
Controlling and Visualizing the Heap
Of course, we would like to prevent collectors from cheating. An easy way to cheat is to simply allocate on the Racket heap. We do not go to great lengths to prevent all forms of cheating (these are carefully-graded homeworks, after all). However, we do demand that collectors access the “heap” through a low-level interface (where the heap is actually just one large Racket array). This interface prevents the storage of non-flat values, thereby forcing students to construct compound representations for compound data. Notably, our framework is flexible enough that we have students design their own memory representations.
The low-level heap interface has an added benefit. Because our
framework can tell “where the heap is”, and has access to the
student's heap-inspection procedures, we are able to provide a
fairly effective heap visualizer:

Learn More
We've been using this framework to teach garbage collection for several years at several universities. It is now included with Racket, too. If you'd like to play with the framework, check out one of our GC homework assignments.
A pedagogic paper about this work will appear at SIGCSE 2013.
References
[1] John Clements and Matthias Felleisen. A Tail-Recursive Machine with Stack Inspection. ACM Transactions on Programming Languages and Systems (TOPLAS), Vol. 26, No. 6, November 2004. (PDF)
[2] Gregory H. Cooper, Arjun Guha, Shriram Krishnamurthi, Jay McCarthy, and Robert Bruce Findler. Teaching Garbage Collection without Implementing Compilers or Interpreters. In ACM Technical Symnposium on Computer Science Education (SIGCSE) 2013. (paper)
[3] Cormac Flanagan, Amr Sabry, Bruce F. Duba, and Matthias Felleisen. The Essence of Compiling with Continuations. In ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 1993. (PDF)
[4] John McCarthy. Recursive Functions of Symbolic Expressions and their Computation by Machine, Part 1. Communications of the ACM, Volume 3, Issue 4, April 1960. (paper)